
Apache Doris Variant:数据类型新纪元,深度解析!
Apache Doris 2.1:Variant数据类型引领半结构化数据新纪元
在当今数字化飞速发展的时代,数据无疑是驱动企业创新的重要引擎。随着业务场景的多样化,传统的结构化数据已难以满足复杂多变的数据处理需求。半结构化数据以其灵活多变、无需事先定义固定结构的特点,正逐渐成为数据存储和分析的新宠。今天,就让我们一起探讨Apache Doris 2.1版本中全新引入的Variant数据类型,如何引领半结构化数据进入新纪元。
半结构化数据,如XML、JSON、日志文件等,以其灵活多变、易于扩展的特性,在数据存储和分析领域展现出强大的生命力。它不受固定结构的束缚,能够轻松应对业务场景中的复杂需求。这种灵活性也带来了一系列挑战。如何在保证数据灵活性的提高数据的解析性能、查询效率以及降低运维成本,成为了摆在数据工程师面前的一大难题。
Apache Doris(原名Apache Incubator Doris),作为一款高性能的MPP分析型数据库,一直致力于为用户提供极致的数据处理体验。在2.1版本中,Doris团队引入了全新的Variant数据类型,旨在全面增强半结构化数据的分析能力。
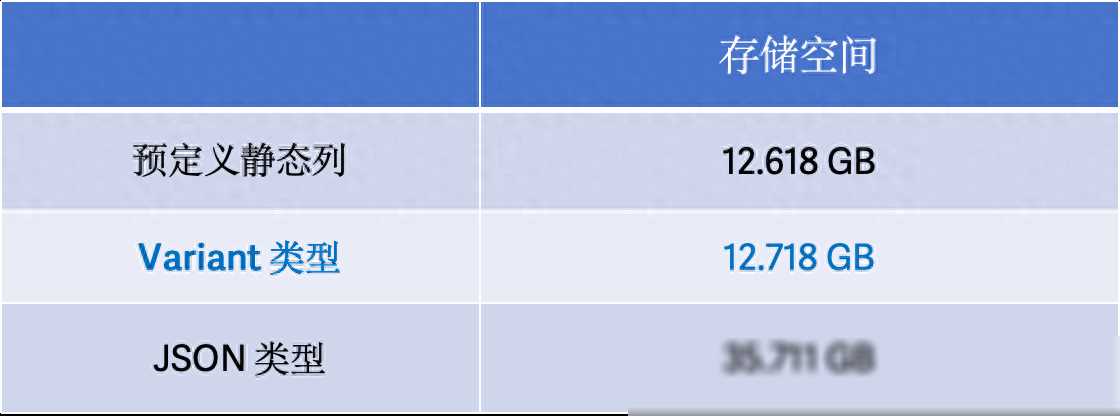
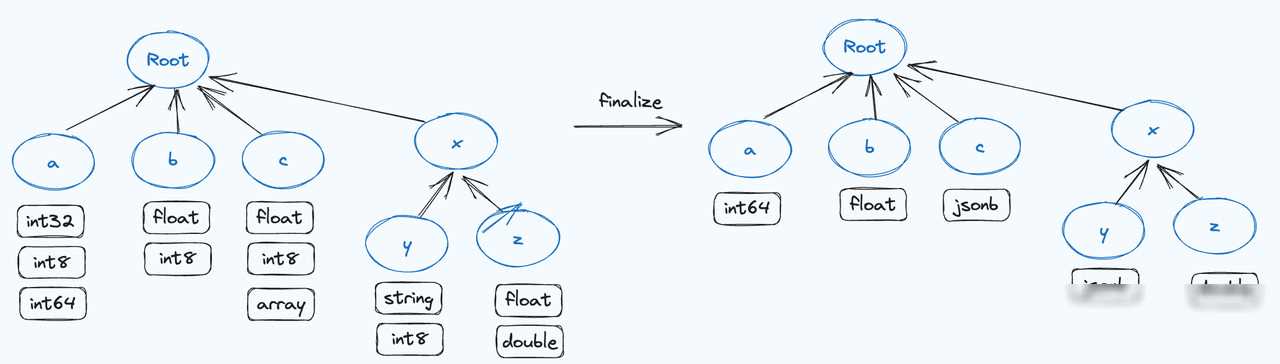
Variant数据类型支持存储半结构化数据,并支持包含不同数据类型的复杂数据结构。它无需提前在表结构中定义具体的列,彻底改变了Doris过去基于String、JSONB等行存类型的存储和查询方式。Variant类型擅长处理复杂多变的嵌套结构,能够自动根据列的结构和类型推断列信息,并将其合并到现有表的Schema中。这种灵活的Schema On Write写入方式,使得数据存储和查询变得更加高效和便捷。
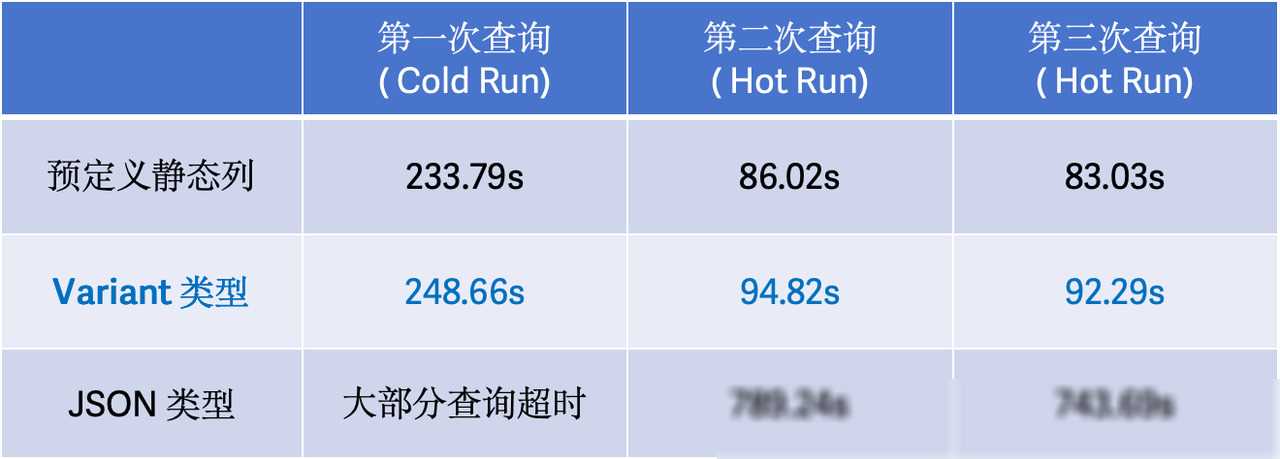
Variant数据类型的引入,不仅提升了Doris在半结构化数据处理方面的能力,更在性能和效率上带来了显著的提升。根据官方测试数据,相较于传统的JSON类型,Variant在存储空间上减少了约65%,查询速度提升了超过8倍。这一数据足以证明Variant数据类型在性能上的卓越表现。
在实际应用中,Variant数据类型的优势更加明显。以Github Events数据为例,通过使用Variant数据类型,我们可以轻松地建立表结构、导入数据并进行查询操作。无论是获取Top5 Star数的代码库、查询评论中包含特定关键词的数量,还是查询评论最多的Issue号及对应库,Variant数据类型都能够快速准确地给出答案。这种高效的查询性能,对于需要处理大量半结构化数据的业务场景来说,无疑是一大福音。
在使用Variant数据类型时,我们需要掌握一些基本的使用技巧。在创建表时,我们需要使用variant关键字来指定Variant列。在查询Variant列的子列时,我们需要使用[]操作符来访问子列的值。由于Variant列的子列类型可能不固定,因此在使用过滤和聚合等功能时,我们需要对子列执行额外的CAST操作来确保数据类型的一致性。

除了基本的使用技巧外,我们还需要注意一些性能优化方面的问题。例如,在Variant列上创建索引时,如果子列较多可能会导致索引列过多而影响写入性能。因此,在创建索引时需要根据实际业务需求进行权衡。另外,对于等值查询场景,我们可以使用布隆过滤器来加速等值过滤操作,提高查询性能。
随着半结构化数据应用场景的不断拓展和深入,Variant数据类型将会在未来的数据处理中发挥越来越重要的作用。作为Apache Doris 2.1版本中的一大亮点功能,Variant数据类型已经在多个实际项目中得到了成功应用,并获得了用户的一致好评。未来,随着Doris团队的持续努力和优化升级,Variant数据类型将会变得更加完善和强大,为用户提供更加高效、便捷的数据处理体验。
总之,Apache Doris 2.1版本中全新引入的Variant数据类型为我们带来了半结构化数据处理的新机遇和挑战。通过掌握其基本使用技巧和性能优化方法,我们可以更好地利用Variant数据类型来处理和分析复杂多变的半结构化数据,从而为企业的创新和发展提供有力的支持。