
200M神模TimesFM!零样本超有监督,时序预测新高度!
仅需200M,零样本性能超越有监督——谷歌时序预测基础模型TimesFM揭秘
在大数据和人工智能的浪潮中,时间序列预测技术以其独特的魅力,成为了零售、金融、制造业、医疗保健和自然科学等多个领域不可或缺的工具。想象一下,如果能****出未来一段时间内的市场需求、股票价格或是疾病传播趋势,那将会为企业决策、政策制定带来多大的便利?传统的预测方法往往受限于数据规模、模型复杂度等因素,难以达到理想的预测效果。今天,我们就来聊聊谷歌最新推出的时序预测基础模型——TimesFM,看看它是如何以仅200M的参数量,实现了零样本性能超越有监督模型的壮举。
一、时间序列预测的挑战与机遇
时间序列预测,简单来说,就是基于历史数据,对未来某一时刻或某一段时间内的数值进行预测。这种预测技术在各个领域都有着广泛的应用,如零售业的库存管理、金融市场的风险控制、制造业的生产计划等。时间序列预测也面临着诸多挑战,如数据的复杂性、模型的泛化能力、预测的准确性等。传统的预测方法,如线性回归、ARIMA模型等,虽然简单易用,但在处理复杂数据时往往力不从心。而深度学习模型,尤其是循环神经网络(RNN)和长短时记忆网络(LSTM)等,虽然在处理序列数据方面有着得天独厚的优势,但也需要大量的数据和计算资源来训练模型,且模型训练周期长、调参复杂。

二、TimesFM模型的诞生与特点
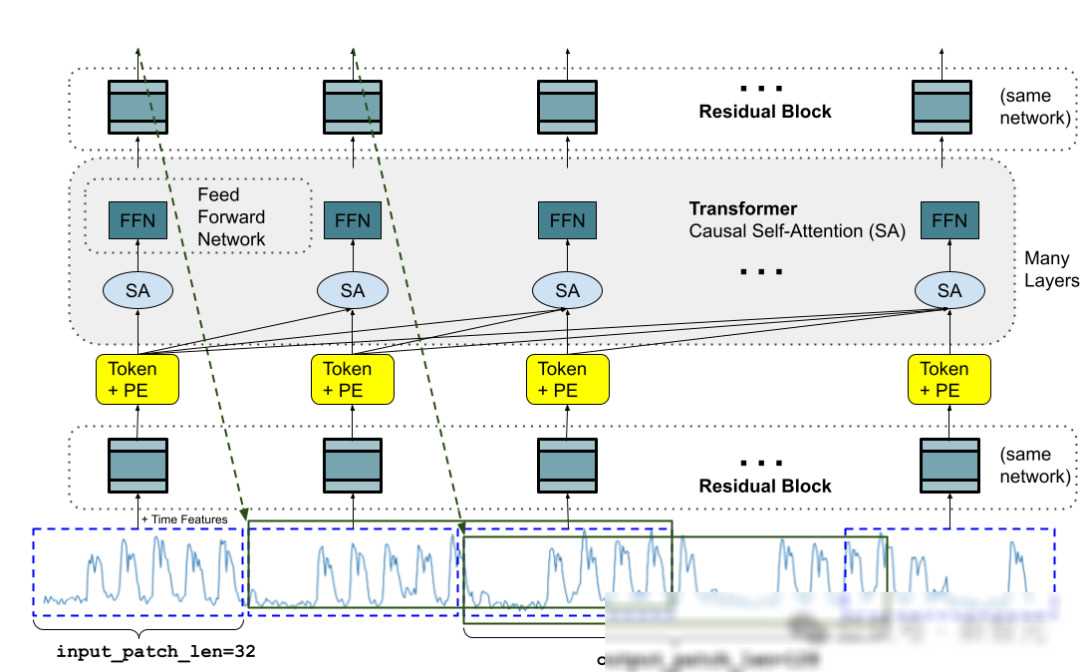
面对这些挑战,谷歌的研究人员们提出了一种新的解决方案——TimesFM模型。TimesFM模型是一种基于Transformer架构的时序预测基础模型,它在预训练阶段使用了1000亿个“真实世界时间点”的数据,通过自监督学习的方式,让模型学会了从海量数据中提取有用的信息。与传统的深度学习模型相比,TimesFM模型具有以下几个显著的特点:
轻量级模型:TimesFM模型仅有200M的参数量,这使得它在计算资源有限的情况下也能发挥出色的性能。相比之下,许多大型的语言模型动辄数十亿甚至上百亿的参数量,不仅训练成本高,而且在实际应用中也难以部署。
零样本性能:TimesFM模型在未经过额外训练的情况下,就能对未见过的数据集进行预测,并且其性能接近于在这些数据集上明确训练过的有监督模型。这种零样本学习的能力使得TimesFM模型具有更强的泛化能力和适应性。
高效预测:TimesFM模型采用了堆叠的Transformer层作为主要构建块,通过自注意力和前馈层等机制,使得模型能够高效地捕捉时间序列数据中的长期依赖关系。模型还支持变长输入和输出,能够适应不同长度的时间序列数据。
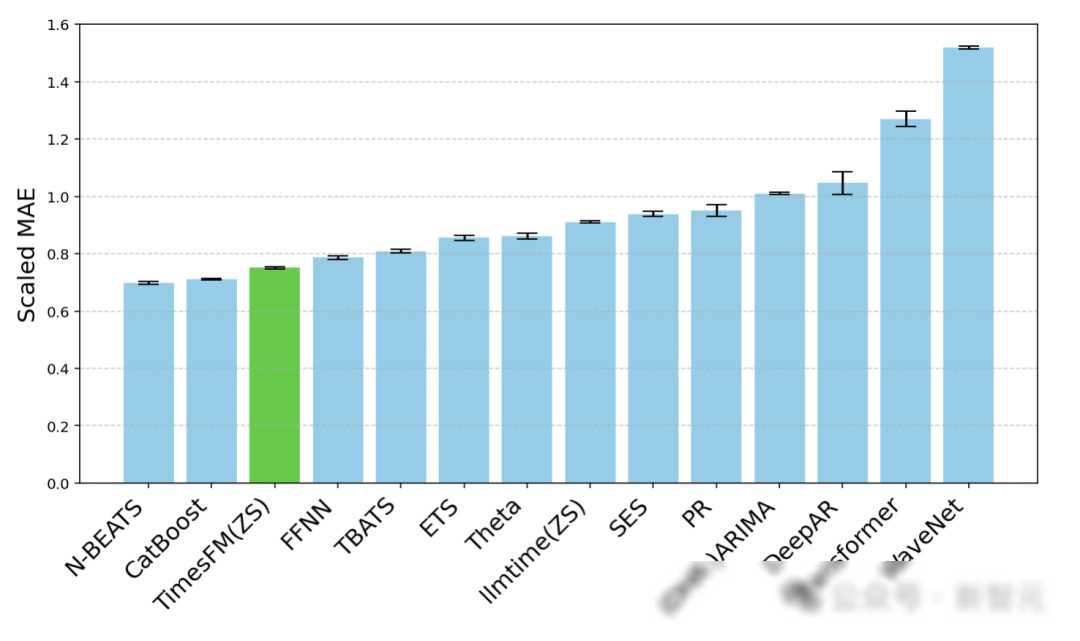
三、TimesFM模型的应用与效果
为了验证TimesFM模型的有效性,谷歌的研究人员们在多个领域和时间粒度的数据集上进行了实验。实验结果表明,TimesFM模型在不同领域和时间粒度的各种未见过的数据集上均取得了优异的预测性能。具体来说,在零售领域的需求预测任务中,TimesFM模型能够****出未来一段时间内的市场需求,帮助企业优化库存管理、降低库存成本;在金融市场的风险控制任务中,TimesFM模型能够预测出股票价格的波动趋势,为投资者提供有价值的参考信息;在制造业的生产计划任务中,TimesFM模型能够预测出未来一段时间内的生产需求,帮助企业合理安排生产计划、提高生产效率。
除了上述应用外,TimesFM模型还具有广泛的扩展性。研究人员们可以通过对模型进行微调或集成其他技术(如特征工程、集成学习等),进一步提高模型的预测性能和泛化能力。此外,TimesFM模型还可以与其他技术(如自然语言处理、图像识别等)相结合,实现跨领域的预测任务。
四、展望与挑战
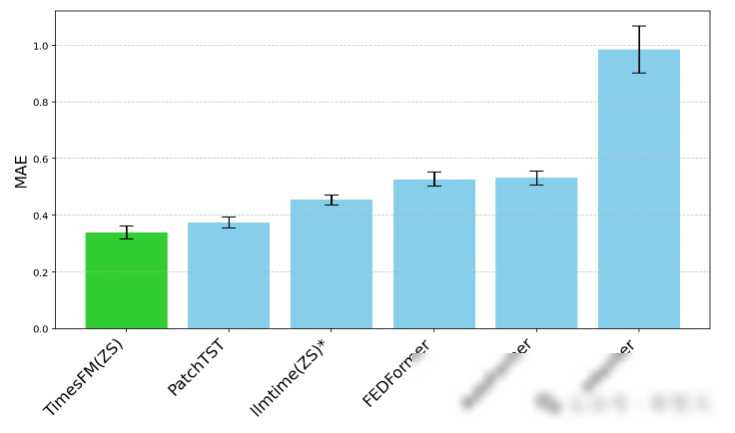
虽然TimesFM模型在时间序列预测领域取得了显著的成果,但它仍然面临着一些挑战和问题。虽然模型在多个数据集上均取得了优异的性能,但其在实际应用中的稳定性和鲁棒性还需要进一步验证。模型在处理大规模数据集时可能会面临计算资源不足的问题,因此需要优化模型的计算效率和可扩展性。随着技术的不断发展和数据的不断增长,时间序列预测领域也将会不断涌现出新的技术和方法,如何将这些新技术和方法与TimesFM模型相结合,实现更好的预测性能和泛化能力,将是未来研究的重要方向。
总之,TimesFM模型作为一种轻量级、高效且具备零样本学习能力的时序预测基础模型,为时间序列预测领域带来了新的机遇和挑战。我们相信,在不久的将来,随着技术的不断发展和应用的不断拓展,TimesFM模型将会发挥更加重要的作用,为我们带来更加精准的预测和更加智能的决策支持。