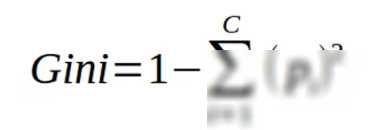决策树工作原理揭秘:智能计算,一目了然!
决策树:机器学习的强大工具
在机器学习领域,决策树无疑是一个引人注目的算法。它不仅简单易懂,易于实现,而且在分类和回归任务中都能展现出卓越的性能。今天,我们就来深入了解一下决策树的工作原理、计算方法以及它在各个领域的应用。
一、决策树的基本概念
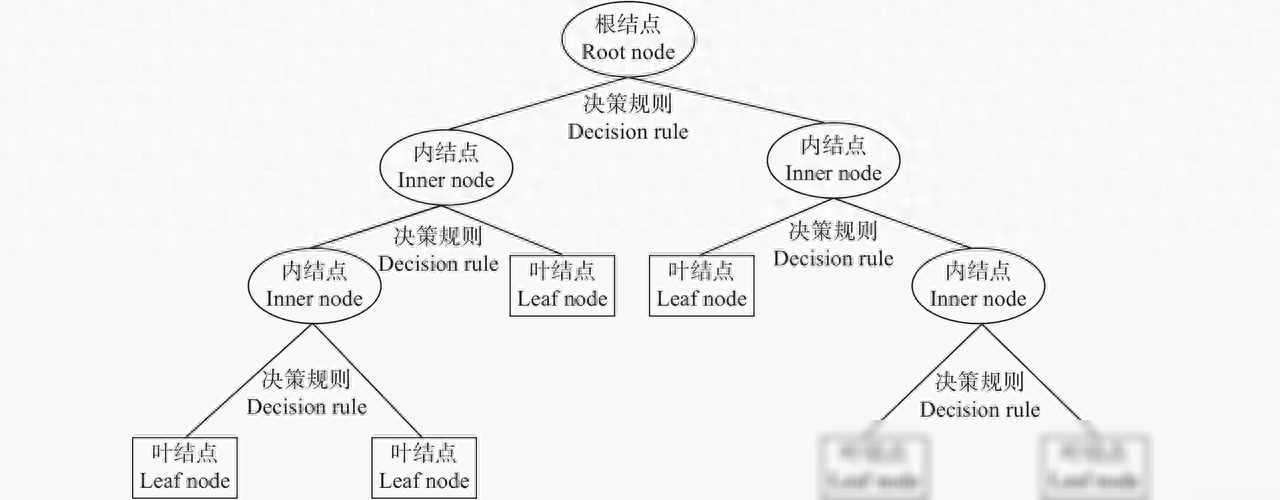
决策树,顾名思义,就像是一棵树的结构,其中包含了多个节点和分支。每个节点代表一个特征属性上的测试,每个分支代表该测试的一个输出,而每个叶节点则代表一个类别或者一个回归值。简单来说,决策树就是通过一系列的问题和答案,将数据逐步划分到不同的类别或预测值中去。
二、决策树的工作原理
决策树的工作原理是基于特征对数据集进行递归的划分。在构建决策树的过程中,算**不断地寻找最优的划分特征,以使得划分后的子集纯度最高。这里的纯度可以理解为子集中数据点的同质性,即同一类别的数据点越多,纯度就越高。
在选择划分特征时,常用的衡量指标有信息增益、增益率、基尼指数等。以信息增益为例,它表示的是划分前后数据集纯度的提升程度。具体来说,就是计算划分前数据集的熵(不确定性度量)和划分后各子集熵的加权平均值之差。差值越大,说明划分后的子集纯度提升越多,因此该特征就越适合作为划分依据。
三、决策树的构建过程
构建决策树的过程可以看作是一个不断递归的过程。算**遍历数据集的所有特征,计算每个特征的信息增益(或其他衡量指标),并选择信息增益最大的特征作为根节点的划分依据。然后,对于根节点划分后的每个子集,算**递归地执行上述过程,直到满足停止条件为止。
停止条件通常包括以下几种情况:
子集中的所有数据点都属于同一类别,此时无需再划分,直接将该子集作为叶节点。
子集中的数据点数量少于某个阈值(如5个),此时也无法再划分,同样将该子集作为叶节点。
树的深度达到了预设的最大值,此时需要停止划分以防止过拟合。
四、决策树的预测过程
当决策树构建完成后,就可以用它来对新的数据进行预测了。预测的过程非常简单,只需要从根节点开始,根据新数据的特征值沿着树结构进行遍历即可。在每个节点上,算**将新数据的特征值与节点的划分阈值进行比较,并根据比较结果选择进入左子树还是右子树。最终,当遍历到叶节点时,叶节点所代表的类别或预测值就是新数据的预测结果。
五、决策树的优缺点
决策树作为一种简单而强大的机器学习算法,具有许多优点:
可解释性强:决策树的结构清晰易懂,易于向非技术人员解释和展示。
易于实现:决策树的构建和预测过程都比较简单,易于编程实现。
鲁棒性强:决策树对噪声和异常值具有一定的容忍度,能够在各种数据集上取得较好的效果。
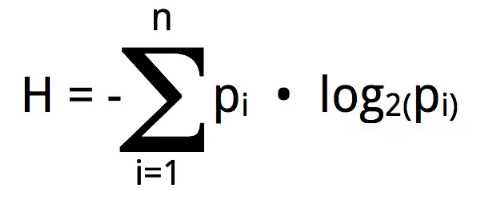
决策树也存在一些缺点:
容易过拟合:当决策树的深度过大时,容易对训练数据过度拟合而忽略数据的真实分布规律。为了避免这种情况,通常需要采用一些剪枝技术来限制树的深度或复杂度。
不适用于连续型数据:决策树在处理连续型数据时需要进行离散化处理(如划分区间),这可能会丢失一些有用的信息。因此,在处理连续型数据时,可能需要考虑其他算法(如回归树、随机森林等)。
六、决策树的应用场景
决策树在实际应用中有着广泛的应用场景,包括但不限于以下几个方面:
金融行业:用于信用评分、欺诈检测、风险评估等任务。例如,银行可以根据客户的个人信息和交易记录构建决策树模型来预测客户是否可能违约或欺诈。
医疗行业:用于疾病诊断、治疗方案推荐等任务。医生可以根据患者的症状和体征构建决策树模型来辅助诊断疾病或推荐合适的治疗方案。
电商行业:用于用户画像分析、商品推荐等任务。电商平台可以根据用户的浏览记录、购买记录等信息构建决策树模型来预测用户的购物偏好和兴趣点从而进行精准的商品推荐。
七、总结
决策树作为一种简单而强大的机器学习算法,在各个领域都有着广泛的应用。通过了解决策树的工作原理、计算方法以及应用场景我们可以更好地掌握这一算法并灵活运用它来解决实际问题。当然在实际应用中我们还需要注意避免决策树的缺点并结合其他算法和技术来提高模型的性能和鲁棒性。