
Jina ColBERT风靡AI圈,RAG领域新宠来袭!
在信息爆炸的时代,如何高效、准确地从海量数据中检索出所需信息,成为了许多领域面临的共同挑战。在RAG(检索增强生成)领域,选对向量模型至关重要,它直接决定了RAG系统的性能上限。近期,Jina AI在Hugging Face上推出的Jina-ColBERT模型,凭借其卓越的性能和独特的多向量搜索技术,在AI圈引起了广泛的关注。本文将深入解析Jina-ColBERT模型,带您领略其技术魅力。
Jina-ColBERT模型以其能够处理高达8192 Token的强大能力,为搜索领域带来了更多的可能性。在Twitter等社交媒体平台上,关于Jina-ColBERT的讨论热度持续攀升,业内人士纷纷对其表示赞赏。相较于市场上的其他向量模型,Jina-ColBERT采用了多向量搜索技术,使得其在处理长文档数据集时表现尤为出色。
传统的单向量模型将整个文档或段落编码成一个单一向量,然后基于余弦相似度进行匹配。这种方法在处理长文本时往往效果不佳,因为单一向量无法充分表达文本的丰富信息。相比之下,多向量模型如Jina-ColBERT,则是将文本中的每个词编码成独立向量,通过迟交互计算相似度。这种方法能够更好地捕捉文本的细粒度信息,提高搜索的准确性和效率。
与ColBERTv2相比,Jina-ColBERT在各项测试中都展现了顶尖的性能。特别是在处理长文档数据集时,其表现更是显著优于ColBERTv2。这一性能提升主要得益于Jina-ColBERT所采用的多向量搜索技术和jina-bert-v2-base-en基础模型。这些技术使得Jina-ColBERT能够轻松应对各种长度的文本,无论是短小精悍的文本还是长篇大论、需要深度理解的搜索任务,都能轻松应对。
ColBERT是基于BERT模型开发的,而BERT作为自然语言处理领域的明星模型,已经广泛应用于各种NLP任务中。ColBERT并非一开始就备受瞩目。在传统搜索(文本匹配)过渡到向量检索的过程中,大家都忙着折腾单向量模型,而ColBERT这位和BERT同门的“小弟”却被忽略了。直到ColBERT升级到v2版本,补齐了v1版本在存储和扩展性上的短板,并显著提升了性能,才重新进入了人们的视野。
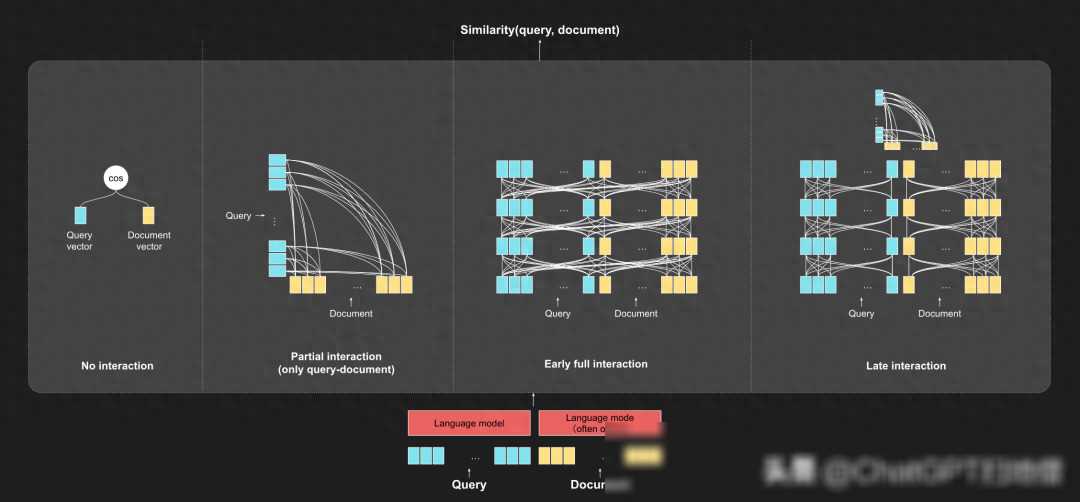
ColBERT采用了一种独特的Late Interaction(迟交互)机制。与传统的query-doc全交互型BERT及目前流行的Embeddings模型相比,ColBERT的迟交互机制具有显著的优势。具体来说,ColBERT首先将查询和文档在词粒度上逐项编码,然后在后续阶段计算查询和文档Token Embedding之间的交互。这种方法既考虑了匹配效率,又充分利用了上下文信息,使得ColBERT既能作为一个强大的召回模型,也可以用作召回之后的重排工具。
迟交互机制为ColBERT带来了两大好处。逐token编码提供了更细粒度的表征,使得在in-domain(同领域)场景下具有很高的MRR@10(头部排序能力)和Recall@1k(腰尾部召回能力)。迟交互机制提供了更好的可解释性。在token-level匹配之后,我们能够解释查询中哪个词与文档中的哪个词最匹配。这种可解释性对于许多应用场景来说至关重要,因为它能够帮助用户更好地理解搜索结果并做出决策。
Jina-ColBERT是Jina AI对原有ColBERT模型进行升级打磨后的成果。其核心改进在于采用了jina-bert-v2-base-en作为基础模型,从而支持一口气处理长达8192 token的文本。这一改进使得Jina-ColBERT在处理长文本时具有更大的优势。无论是处理学术论文、专利文档还是网络新闻等长文本内容,Jina-ColBERT都能轻松应对并给出准确的搜索结果。
此外,Jina-ColBERT还继承了ColBERT的迟交互机制和多向量搜索技术。这使得Jina-ColBERT在保持高准确性的还具备了出色的可解释性和泛化能力。在处理跨领域或长尾查询时,Jina-ColBERT同样能够展现出优秀的性能表现。
Jina-ColBERT作为RAG领域的新星,凭借其卓越的性能和独特的技术优势,正在逐步改变搜索领域的格局。随着技术的不断发展和应用场景的不断拓展,我们有理由相信Jina-ColBERT将会在未来发挥更加重要的作用。
对于开发者而言,了解并掌握Jina-ColBERT的技术原理