
深入解析视频理解的AI技术:多模态模型的未来发展与应用
高质量视频理解数据集的创建与应用
一、引言
在数字化时代,视频数据的飞速增长使得视频理解的重要性愈发凸显。想想看,现在我们每天都在接触视频内容,无论是短视频平台上的搞笑视频,还是*******上的教育讲座,你有没有想过,背后是怎样的技术支持着这些视频的理解和处理?视频多模态模型(LMM)作为这一技术的核心,正逐渐成为推动人工智能发展的重要力量。然而,开发高效的视频理解模型面临着一个亟待解决的难题:数据获取的困难。
为了训练出优秀的视频理解模型,我们需要大量高质量的数据集。这些数据集不仅要涵盖不同类型的视频,还需具备丰富的标注信息,以便模型能够准确理解视频的内容和上下文。那么,怎样才能构建出一个既全面又高效的数据集呢?本文将探讨LLava-Video-178K数据集的构建过程,以及它在视频理解领域的应用潜力。
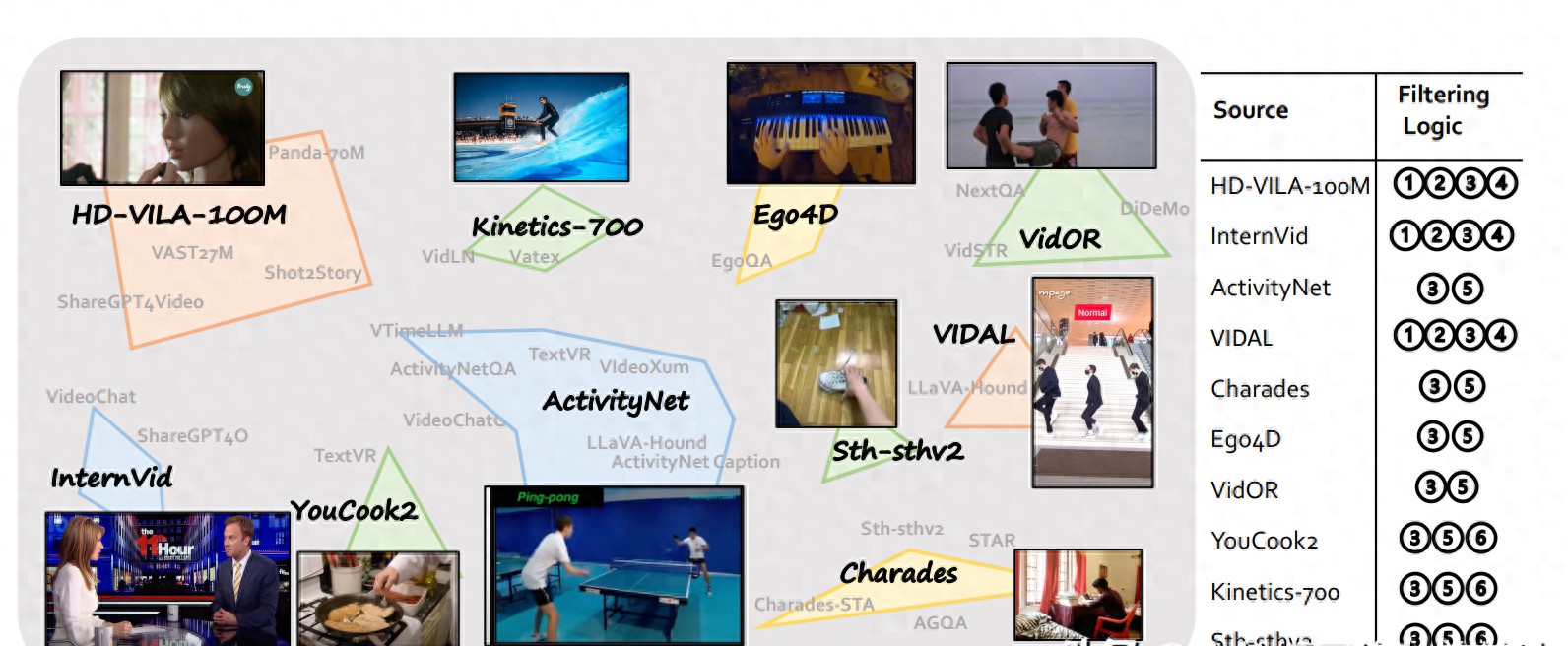
二、数据集的构建
2.1 数据来源选择
在构建LLava-Video-178K数据集时,数据的来源选择至关重要。为什么选择特定的数据源会影响最终数据集的质量?简单来说,数据的多样性和代表性直接关系到模型的训练效果。为了构建一个全面且平衡的数据集,我们从多个视频平台收集了178,000个视频,涵盖了多种类型与主题,比如娱乐、教育、新闻等。
以*******为例,该平台上有无数的视频资源,用户生成的内容丰富多彩。然而,仅仅依赖一个平台的数据是否足够?我们还从Vimeo、TikTok和公共视频库等多个来源收集数据,以确保数据集的多样性,最终形成了一个包含1.3百万个指令样本的数据集。这样的选择,能否让模型在处理不同类型的视频时表现得更为出色?
2.2 视频描述生成
我们要探讨的是视频描述的生成。你是否想过,如何让机器理解视频中的每个细节?在LLava-Video-178K数据集中,我们使用了强大的人工智能模型GPT-4o来生成详细的视频描述。通过逐帧采样,每秒钟提取一帧进行描述,这样的方式为何能提升描述的准确性?
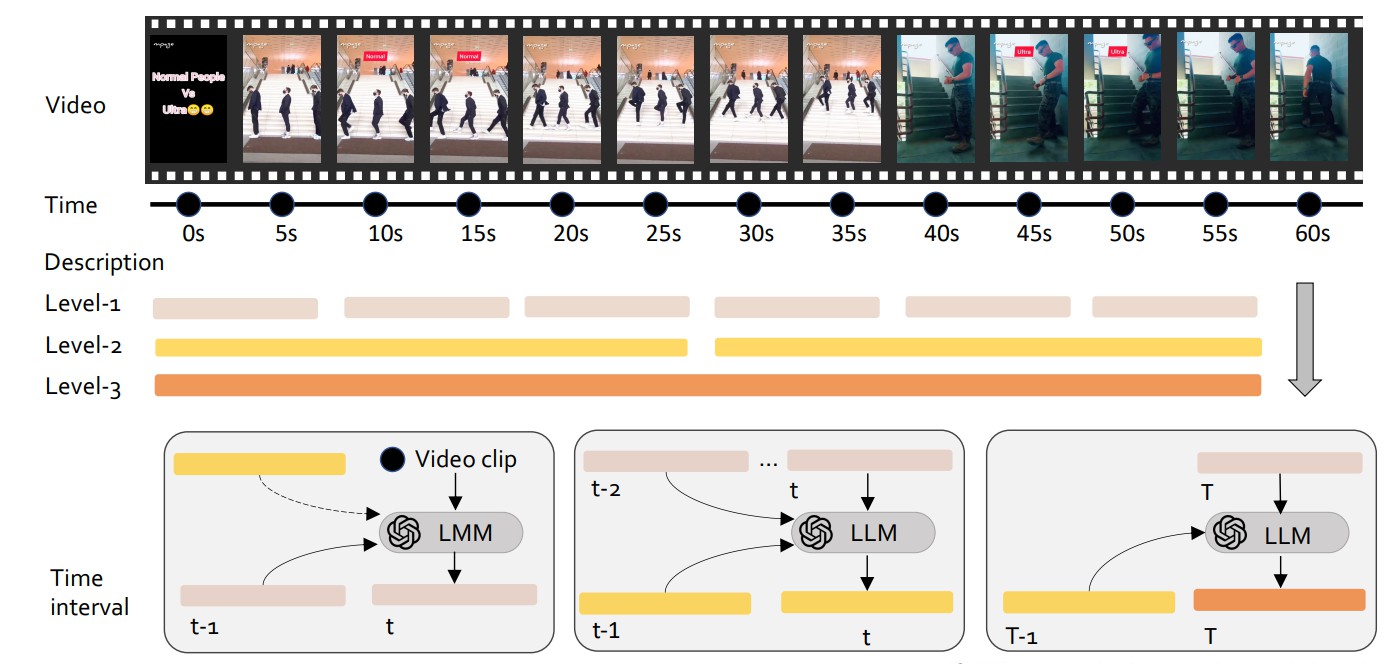
视频中的每个细节都被AI捕捉到,并且生成的描述分为三个级别:级别-1描述每10秒提供一次,级别-2描述每30秒提供一次,而级别-3描述则在视频结束时提供。这样的分层描述,不仅能让模型更好地理解视频的情节,还能让它把握视频的整体框架。这样的设计,是否能让模型在理解复杂场景时游刃有余?
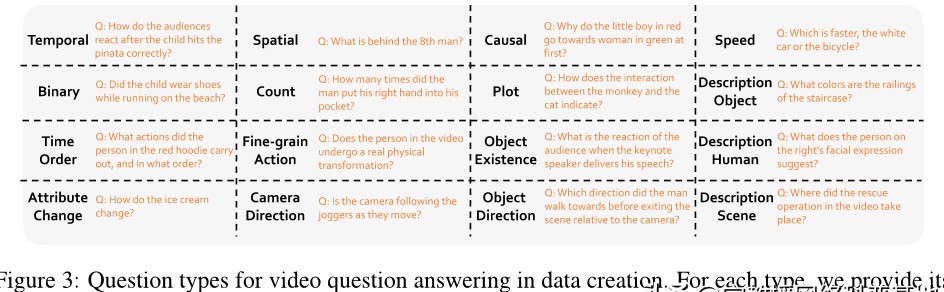
2.3 问题答案对的生成
除了视频描述,问题答案对的生成同样至关重要。你有没有想过,如何让模型能够回答用户的真实问题?在LLava-Video-178K中,我们参考了多个公共视频问答基准,将问题分为16个具体类别。这种分类是否能够提升模型的理解能力?
在生成问题答案对时,我们同样使用了GPT-4o。针对每个类别的问题,模型会根据视频的详细描述自动生成一个问题及其答案。想象一下,用户在观看视频时提出的问题,可以通过AI迅速得到答案,这样的互动是否能提升用户体验?
三、数据集的创新点
3.1 多样性的提升
LLava-Video-178K数据集的一个显著特点是它的多样性。为什么多样性如此重要?简单来说,数据集的多样性直接影响到模型的泛化能力。如果数据集中只有少数特定类型的视频,模型在面对新类型的视频时,可能会无从下手。通过提供开放式问题与多项选择题,我们的目标是训练出一个能够应对各种查询的视频理解模型。
在教育视频中,学生可能会问“这个概念的实际应用是什么?”而在娱乐视频中,观众可能会问“这个场景中的演员是谁?”这样的多样化问题,是否能让模型在不同场景中都表现得游刃有余?
3.2 详细描述管道
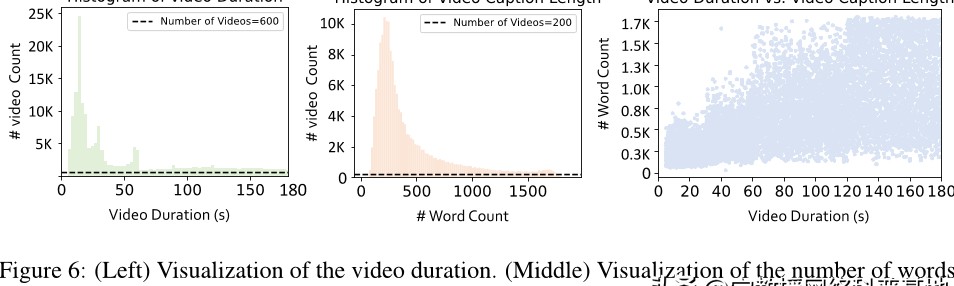
在视频描述的生成过程中,我们构建了一个详细描述管道。你能想象一个系统,能够在任何长度的视频上生成详细的描述吗?通过密集采样策略,我们的模型能够每秒采集一帧,从而确保样本的丰富性。这样的策略是否能让视频的情节更加完整而真实?
在一段关于烹饪的视频中,模型不仅能描述每个步骤,还能捕捉到烹饪过程中食材的变化。这种细腻的描述,是否能让观众在观看时更有代入感?

3.3 质量与性能对比
为了验证数据集的质量,我们进行了多项对比实验。数据集的质量如何影响模型的性能?我们发现,当逐步添加不同的数据集时,模型的性能呈现出明显的提升。这是否意味着,数据的质量是影响模型表现的关键因素?
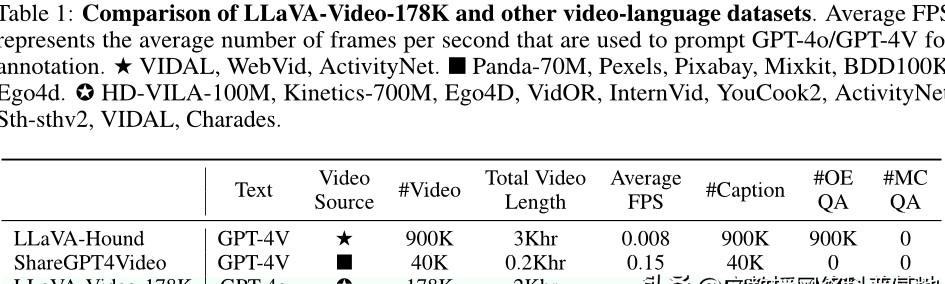
在对比实验中,我们还发现LLava-Video-178K的数据质量优于其他数据集。这是因为它的****更加丰富多样,并且在动态视频的采样率上也更高。这种优势是否能够让模型更好地捕捉完整的情节,从而提升视频理解的准确性?
四、LLaVA-Video模型的开发与实验
4.1 模型概述

在LLava-Video-178K数据集的基础上,我们开发了LLaVA-Video模型。这个模型的设计思路是什么?简单来说,LLaVA-Video旨在通过结合丰富的数据集与先进的技术,实现更高效的视频理解。它与现有的视频语言模型相比,有哪些独特的优势?
LLaVA-Video在处理复杂视频场景时,能够结合多种信息源,从而提升理解能力。这是否意味着,未来的视频理解将不再局限于简单的文本描述,而是能够深入到视频的每个细节?

4.2 实验设计与结果
为了验证LLaVA-Video模型的性能,我们进行了多个实验。在整体性能测试中,模型在ActivityNet-QA、LongVideoBench等多个基准数据集上表现如何?是否能与商业封闭源模型Gemini-1.5-Flash相媲美?
实验结果表明,LLaVA-Video模型在大多数数据集上都取得了优异的成绩。你是否也对这种开源努力感到惊讶?而且,使用更大数据集训练的LLaVA-Video-7B模型在许多数据集上更是展现了更强的性能,这是否意味着,未来我们能期待更多的开源技术带来更优秀的结果?
在对比实验中,我们还发现,随着数据集数量的增加,模型性能逐渐提高。这是否说明,数据的丰富程度对模型训练的重要性不可小觑?
五、结论与未来展望
5.1 研究总结
LLava-Video-178K数据集为视频理解模型的训练提供了高质量、多样化和丰富的数据资源。这些资源是否真的能显著提升模型的性能和泛化能力?我们坚信,答案是肯定的。
LLaVA-Video模型在多个实验中表现出色,验证了数据集的重要性和创新性。这是否意味着,未来我们在视频理解领域将会看到更多的突破?
5.2 未来研究方向
未来的研究方向将围绕着几个关键点展开。首先,如何扩展数据集的规模?随着视频数量和质量的提高,增加更多的视频源与任务类型是否能进一步提升模型的能力?
发展更加高效的视频表示技术也尤为重要。是否有可能通过新的技术手段,进一步优化模型的表现?
我们应该探索视频指令跟随在不同应用场景下的效果。比如,在教育、娱乐等领域,如何更好地应用这些技术,是否会带来意想不到的惊喜?
在这个快速发展的领域,LLava-Video-178K数据集的出现不仅是一次技术的突破,更是对未来视频理解研究的启示。你准备好迎接这一波革新了吗?