BERT助力Bug定位,变更集秒速搞定!
基于BERT的变更集Bug定位技术探秘
在繁忙的软件开发周期中,Bug(缺陷)定位一直是一个让人头疼的问题。想象一下,一个复杂的软件项目里,成千上万行代码交织在一起,一个不起眼的小错误就可能让整个系统崩溃。而开发者们却像侦探一样,在茫茫代码海中寻找那些潜藏的“罪犯”。随着自然语言处理和深度学习技术的飞速发展,我们有了更高效的工具——BERT,它正逐渐改变着Bug定位的面貌。
BERT(Bidirectional Encoder Representations from Transformers)是近年来自然语言处理领域的一颗璀璨明星。它通过深度学习的方式,能够理解和生成人类语言,并在各种自然语言处理任务中取得了显著成效。而在软件工程中,BERT也被赋予了新的使命——基于变更集的Bug定位。
传统的Bug定位方法往往依赖于代码之间的直接文本相似度,但这种方法在面对复杂的软件项目时显得力不从心。而BERT则能够捕捉代码的语义信息,通过理解代码的意图和上下文来定位Bug。想象一下,如果一个Bug报告描述了一个功能异常,而某个变更集恰好修改了该功能的相关代码,那么BERT就能够将这两者关联起来,从而快速定位到Bug的源头。
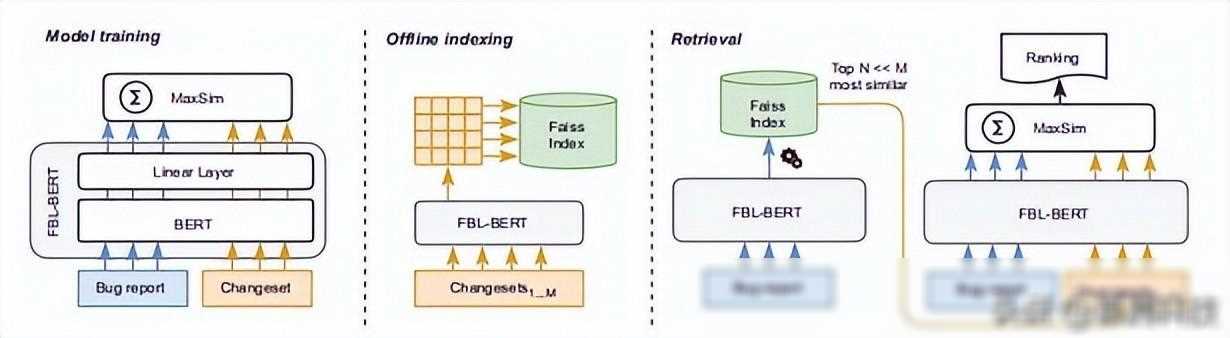
在基于BERT的变更集Bug定位中,检索架构的设计至关重要。我们可以将BERT模型看作是一个“翻译器”,它将Bug报告和变更集转化为高维向量空间中的表示。这些向量不仅包含了文本的语义信息,还能够捕捉代码的语法结构和功能逻辑。
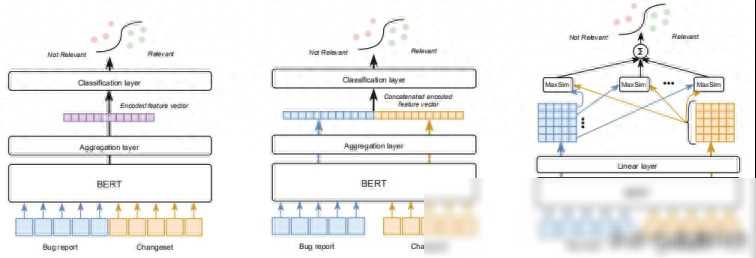
在检索过程中,我们可以采用两种常见的架构:单BERT和Siamese BERT。单BERT架构将Bug报告和变更集同时输入到BERT模型中,生成两个向量表示,并通过计算它们之间的相似度来排序变更集。而Siamese BERT架构则分别将Bug报告和变更集输入到两个独立的BERT模型中,生成各自的向量表示,然后再计算它们之间的相似度。
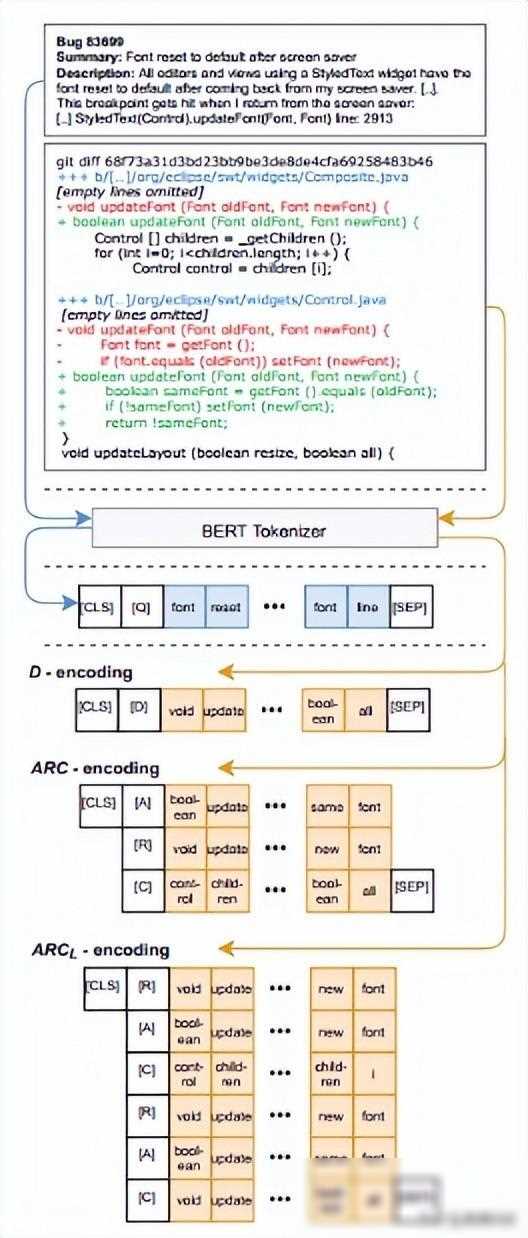
在利用BERT进行Bug定位时,我们需要面对一系列设计决策。其中一个重要的决策是如何对变更集进行编码。变更集通常包含了大量的代码修改和注释信息,我们需要将这些信息转化为BERT模型能够理解的格式。一种常见的做法是将变更集转化为一系列的代码块或代码片段,并将它们作为BERT模型的输入。
这种编码方式也面临着一些挑战。如果我们将整个变更集作为输入粒度,那么模型的性能可能会受到严重影响。因为变更集通常包含大量的代码和注释信息,这些信息可能并不都与Bug定位相关。因此,我们需要寻找一种更细粒度的输入数据,以提高检索质量。
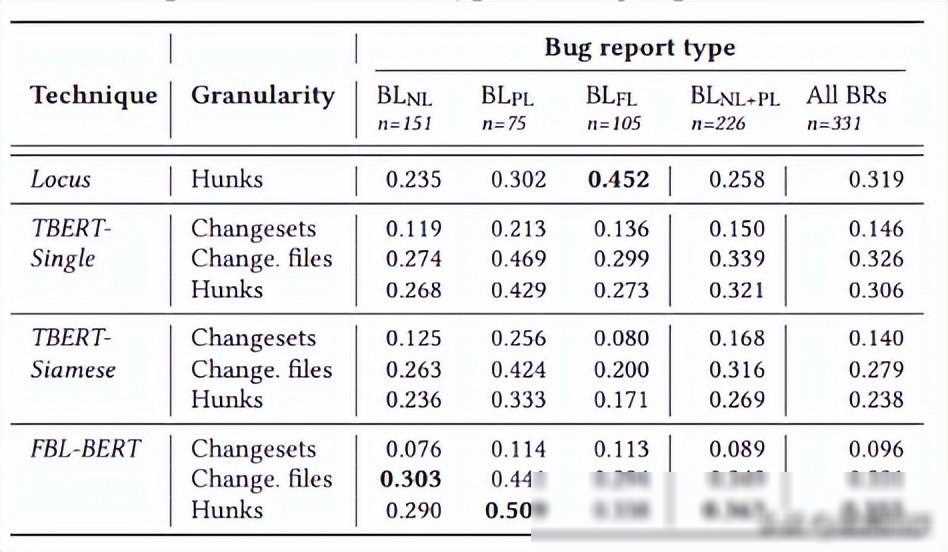
在我们的实验中,我们尝试了不同的编码策略和输入粒度,并对比了它们的性能表现。实验结果表明,利用更细粒度的输入数据(如代码块或代码片段)可以显著提高检索质量。我们还发现搜索空间的大小(即项目中变更集的数量)也会显著影响不同基于BERT的模型的检索延迟。在我们提出的模型中,这种影响相对较小,从而保证了模型的高效性和实用性。
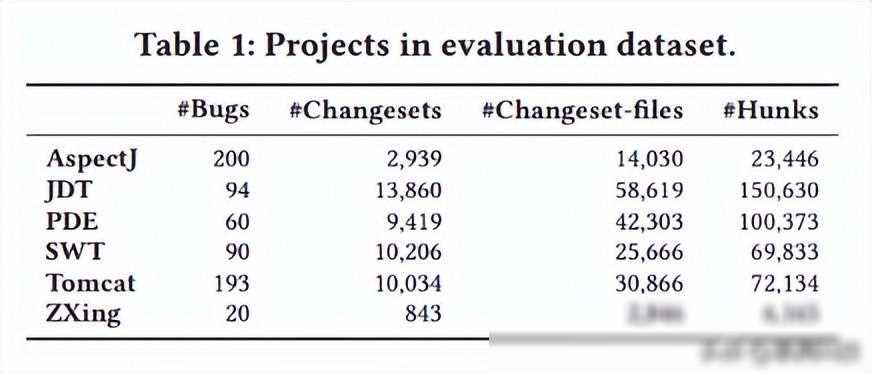
为了更好地说明基于BERT的变更集Bug定位技术的优势,我们选取了一个真实的软件项目作为实验案例。该项目是一个复杂的Web应用,包含了大量的代码文件和变更集。我们将该项目中的Bug报告和变更集作为数据集,并使用了我们提出的基于BERT的Bug定位方法进行了实验。
实验结果表明,与基线方法相比,我们的方法在检索准确率方面取得了显著的提升。特别是对于那些缺乏任何相关代码元素提示的Bug报告,我们的方法能够准确地定位到引起Bug的变更集。这不仅提高了Bug修复的效率,也降低了开发者的工作负担。
此外,我们还对比了不同基于BERT的模型的性能表现。实验数据显示,我们提出的模型在检索速度和准确性方面都表现优异。即使在面对大规模的搜索空间时,该模型仍然能够保持高效的检索性能。
随着BERT技术的不断发展和完善,它在软件工程领域的应用也将越来越广泛。除了基于变更集的Bug定位外,BERT还可以用于代码推荐、代码自动生成、代码注释生成等任务。这些应用将进一步提高软件开发的效率和质量,让开发者们能够更加轻松地应对复杂的软件项目挑战。
我们也需要关注BERT技术的局限性和挑战。例如,BERT模型在处理大规模数据集时可能会面临计算资源和时间的限制;如何将BERT模型与现有的软件工程工具和框架进行有效整合也是一个需要解决的问题。因此,我们需要在未来的研究中不断探索和创新,以推动BERT技术在软件工程领域的发展和应用。
总之,基于BERT的变更集Bug定位技术为软件开发者提供了一种高效、准确的Bug定位方法。通过深入理解代码的语义信息和上下文关系,BERT能够帮助开发者快速定位到Bug的源头,提高Bug修复的效率和质量。随着技术的不断发展和完善,相信BERT将在软件工程领域发挥越来越重要的作用。