Fluid+Vineyard,Kubernetes中间数据管理新高度!
Fluid携手Vineyard:Kubernetes上高效中间数据管理的新篇章
随着云计算和大数据技术的飞速发展,Kubernetes已成为现代软件开发和运维的基石。特别是在AI/大数据领域,Kubernetes的普及极大地推动了业务场景的复杂化和多元化。随之而来的是一系列技术挑战,特别是在数据科学家面临研发效率和运行效率的新考验时。今天,我们就来聊聊Fluid和Vineyard如何携手解决这些问题,开启Kubernetes上高效中间数据管理的新篇章。
一、Kubernetes与AI/大数据的甜蜜邂逅

在AI/大数据的世界里,数据处理流程通常涉及多个环节和组件,从数据的采集、存储、处理到分析,每一个环节都至关重要。而Kubernetes凭借其强大的容器编排和自动化管理能力,为这些环节提供了统一的、可伸缩的底层支撑。数据科学家可以更加灵活地构建端到端的流水线,实现复杂的数据处理和分析任务。
随着业务场景的复杂化,数据科学家也面临着诸多挑战。比如,开发环境和生产环境的差异导致数据工作流的开发和调试变得复杂且低效;需要引入分布式存储实现中间临时数据交换,带来额外的开发、费用、运维成本;在大规模Kubernetes集群环境中,数据处理效率也受到限制。这些问题都制约了数据科学家的工作效率和项目的整体进展。
二、Fluid:Kubernetes上的数据编排与加速引擎

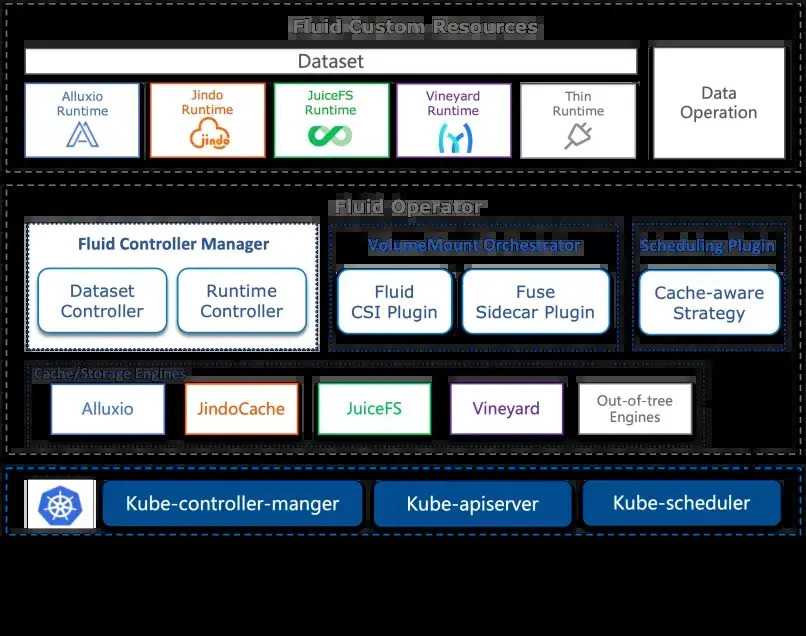
为了解决这些问题,Fluid应运而生。作为一个开源的Kubernetes原生分布式数据集编排和加速引擎,Fluid为云原生场景下的数据密集型应用提供了一站式解决方案。通过Kubernetes服务提供的数据层抽象,Fluid可以让数据像流体一样在存储源和计算节点之间灵活高效地移动、**、驱逐、转换和管理。
具体来说,Fluid提供了数据集编排和应用编排两大核心功能。数据集编排可以将指定数据集的数据缓存到具有特定特性的Kubernetes节点上,从而优化数据访问的效率和性能。应用编排则可以根据数据集的特性将应用调度到最适合的节点上执行,进一步提高计算资源的利用率和数据处理效率。
此外,Fluid还提供了丰富的数据集管理能力,包括安全性、版本管理和数据加速等。通过定义Runtime这样的执行引擎,Fluid可以实现数据集的多维度管理,确保数据的安全性和一致性。通过优化数据的存储和访问方式,Fluid还可以显著提升数据处理的效率和性能。
三、Vineyard:高效共享中间结果的数据管理引擎
在大数据处理流程中,中间结果的共享和传递是一个重要的环节。传统的做法是将中间结果存储到分布式文件系统或对象存储系统中,然后在不同的计算引擎之间进行数据传输和交换。这种做法不仅增加了数据处理的复杂度和成本,还可能导致数据访问的延迟和性能瓶颈。
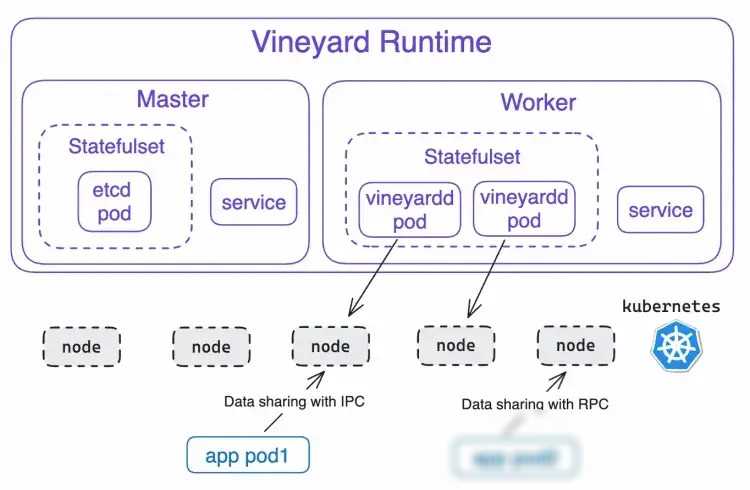
为了解决这个问题,Vineyard应运而生。作为一个专为云原生环境大数据分析工作流中不同任务之间高效共享中间结果而设计的数据管理引擎,Vineyard通过共享内存的方式实现了中间数据的零拷贝共享。这意味着不同的计算引擎可以直接访问共享内存中的中间数据,而无需进行额外的数据传输和转换操作。这不仅大大提高了数据访问的效率和性能,还降低了数据处理的复杂度和成本。
四、案例实战:Fluid与Vineyard的协同作战
为了更好地展示Fluid和Vineyard的协同作战能力,我们来看一个具体的案例。某金融科技公司为了提升风控能力,构建了一个端到端的风控作业数据操作流。该流程首先从数据库中导出订单相关数据,然后利用图计算引擎构建“用户-商品”关系图,并通过图算法初筛出潜在的作弊团伙。接下来,机器学习算**对这些潜在团伙进行作弊归因分析,筛选出更准确的结果。这些结果会经过人工筛查并最终做出业务处理。
在这个案例中,数据科学家面临了诸多挑战。开发环境和生产环境的差异导致数据工作流的开发和调试变得复杂且低效。需要引入分布式存储实现中间临时数据交换,带来了额外的开发、费用、运维成本。在大规模Kubernetes集群环境中,数据处理效率也受到了限制。
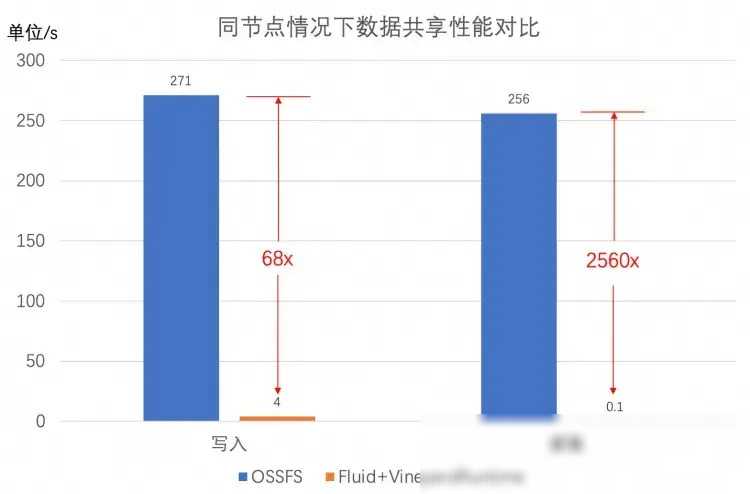
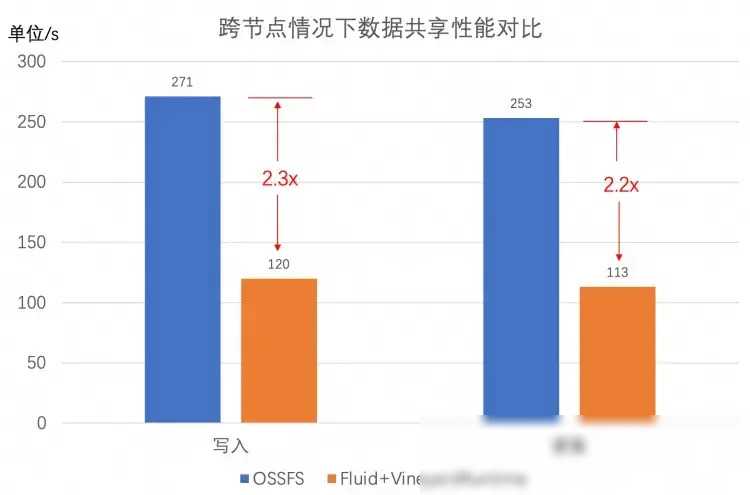
通过引入Fluid和Vineyard的解决方案,这些问题都得到了有效解决。Fluid通过数据集编排和应用编排功能优化了数据访问的效率和性能,使得数据可以在存储源和计算节点之间灵活高效地移动和管理。Vineyard通过共享内存的方式实现了中间数据的零拷贝共享,大大提高了数据访问的效率和性能。在Fluid和Vineyard的协同作用下,整个风控作业数据操作流的效率和性能都得到了显著提升。
具体来说,通过Fluid的数据集编排功能,数据科学家可以将订单相关数据缓存到具有高性能存储的Kubernetes节点上,从而优化数据访问的效率和性能。通过Vineyard的共享内存功能,图计算引擎和机器学习算法可以直接访问共享内存中的中间数据,无需进行额外的数据传输和转换操作。这不仅提高了数据处理的效率和性能,还降低了数据处理的复杂度和成本。
此外,在大规模Kubernetes集群环境中,Fluid还可以根据数据集的特性将应用调度到最适合的节点上执行。通过优化计算资源的利用率和数据处理