激活函数选对,模型性能飙升!17招高效训练秘诀!
激活函数:神经网络中的“调味剂”
在烹饪中,调味料的作用至关重要,它们为食材增添了丰富的味道,让人食欲大增。同样,在神经网络的“烹饪”过程中,激活函数就扮演着这样的“调味剂”角色,为网络模型增添了非线性特性,使其能够学习和适应复杂的模式。今天,我们就来聊聊这些激活函数,看看它们是如何让我们的神经网络“美味可口”的。
一、激活函数:神经网络的“灵魂”
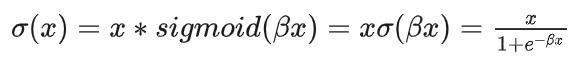
激活函数是神经网络中不可或缺的组成部分。没有它们,神经网络就只是一个线性模型,无法捕捉和模拟现实世界中的复杂关系。通过引入激活函数,我们可以为网络注入非线性特性,从而提升其表达能力和学习能力。
二、经典之选:饱和激活函数
Sigmoid函数
Sigmoid函数,也被称为逻辑函数,曾经风靡一时。它将输入映射到0和1之间,非常适合用于二分类问题的输出层。想象一下,当你需要判断一张图片是不是猫时,Sigmoid函数就能帮你输出一个概率值,告诉你这张图片是猫的可能性有多大。
Sigmoid函数也有它的缺点。当输入值非常大或非常小时,函数的梯度会接近于0,这会导致梯度消失问题,使得网络在训练过程中变得非常缓慢甚至停滞不前。
Tanh函数
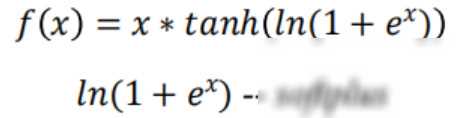
与Sigmoid函数相比,Tanh函数将输入映射到-1和1之间。它的中心点在零点,这使得它在某些情况下比Sigmoid函数表现更好。Tanh函数同样面临着梯度消失的问题。
三、新宠儿:非饱和激活函数
为了解决饱和激活函数带来的梯度消失问题,研究者们提出了一系列非饱和激活函数。
ReLU函数
ReLU(Rectified Linear Unit)函数是近年来深度学习领域最常用的激活函数之一。它非常简单且高效:在输入值大于0时,导数为1;小于0时,导数为0。这种特性使得网络能够有效地学习复杂的模式,并加速训练过程。
ReLU函数也有一个问题:当输入小于0时,其输出为0,这可能导致某些神经元在训练过程中“死亡”,即不再对网络的输出产生任何影响。
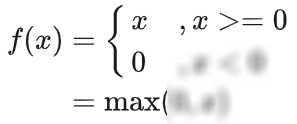
Leaky ReLU与PReLU函数
为了解决ReLU函数的“死亡”问题,研究者们提出了Leaky ReLU函数。它在输入小于0时给予一个小的正梯度,使得神经元在负输入时仍然能够学习。而PReLU函数则是Leaky ReLU的参数化版本,它允许网络在训练过程中学习这个小的正梯度值。
ELU函数
ELU(Exponential Linear Unit)函数结合了Sigmoid和Leaky ReLU的特点。在负数区域,它的导数接近于零但又不完全为零,这有助于缓解梯度消失问题。在正数区域它具有与ReLU相似的特性。
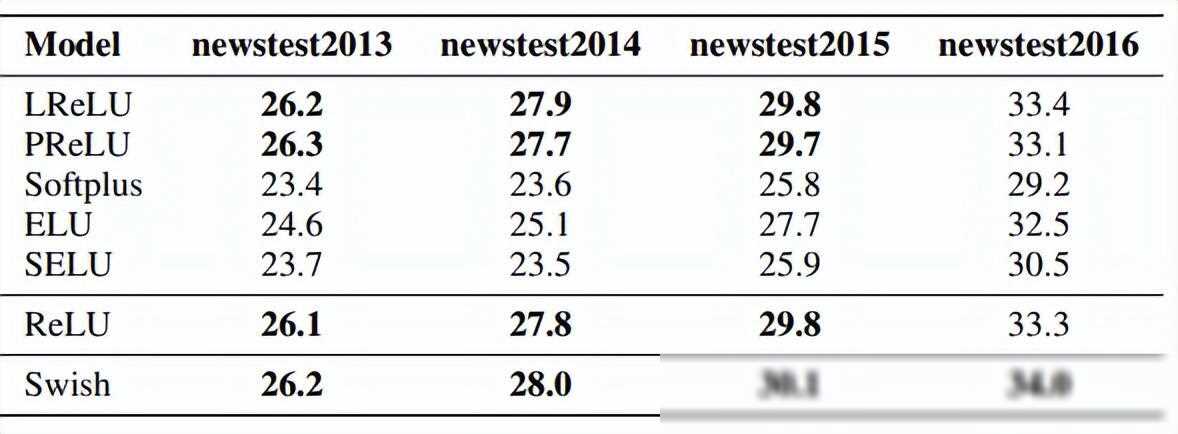
四、新兴之星:Swish激活函数
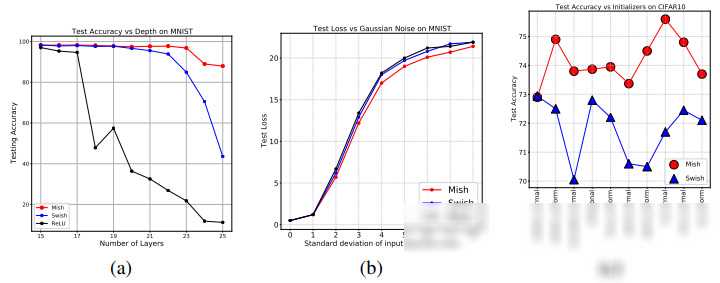
近年来通过机器学习技术发现了一种新型激活函数——Swish。Swish函数在处理负输入时表现出了比ReLU更好的性能。它由Swish的自门控属性启发而来,提供了一种自我调节、平滑且非单调的激活方式。这种特性使得神经网络在训练过程中能够更准确地捕捉数据中的复杂关系并提升泛化能力。
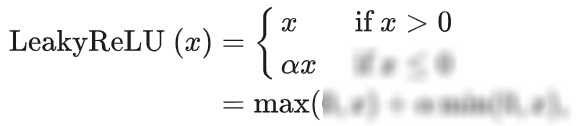
五、总结与展望
激活函数作为神经网络的“调味剂”,在提升网络性能方面发挥着至关重要的作用。从经典的饱和激活函数到新兴的非饱和激活函数以及最新的Swish函数,我们看到了激活函数不断发展和完善的历程。
未来随着深度学习技术的不断进步和应用场景的日益丰富多样,我们期待更多具有创新性和实用性的激活函数涌现出来为神经网络的发展注入新的活力!