
Pandas神助攻!数据分析利器详解与应用!
Pandas:数据分析的得力助手
在数字时代,数据如同无形的财富,而数据分析则是解锁这份财富的钥匙。在众多数据分析工具中,Pandas以其强大的功能和简单易用的特性,成为了数据分析师和数据科学家的得力助手。今天,就让我们一起走进Pandas的世界,探索它如何助力我们破解数据奥秘。
一、Pandas:数据江湖中的剑客
在数据分析的江湖中,Pandas就像是一位身怀绝技的剑客。它手持一把名为“DataFrame”的利剑,可以轻松应对各种数据类型,无论是时间序列数据、结构化数据还是非结构化数据,Pandas都能游刃有余地处理。与此Pandas还与NumPy这位江湖中的前辈高手紧密合作,共同为数据分析提供强大的支持。
Pandas的强大之处不仅仅在于其处理数据的能力,更在于其易用性。通过简单的几行代码,我们就可以实现数据的读取、清洗、转换和可视化等操作。这种高效的工作方式让数据分析师能够更专注于分析本身,而不是花费大量时间在数据预处理上。
二、Pandas的独门绝技
Pandas之所以能够在数据分析领域独领**,离不开其一系列独门绝技。下面,我们就来一起看看Pandas的这些绝技是如何帮助我们进行数据分析的。
DataFrame:数据的舞台
DataFrame是Pandas中的核心数据结构,它就像一个舞台,承载着数据的表演。DataFrame可以看作是一个二维的表格,其中行表示不同的样本,列表示不同的特征。通过DataFrame,我们可以对数据进行各种操作,如筛选、排序、分组、聚合等。DataFrame还支持与Matplotlib等可视化库的无缝集成,让我们能够轻松地将数据可视化展示出来。
时间序列数据处理
在数据分析中,时间序列数据是一类非常重要的数据类型。Pandas提供了专门的时间序列功能,可以轻松地对日期和时间数据进行操作。无论是日期的加减、格式化还是时间间隔的计算,Pandas都能轻松应对。这使得我们在处理时间序列数据时更加得心应手。
数据清洗
数据清洗是数据分析中一个非常重要的环节。Pandas提供了多种方法来处理缺失值和重复数据等脏数据。例如,我们可以使用fillna方法将缺失值填充为某个值(如0或平均值),或者使用drop_duplicates方法删除重复的行。通过数据清洗,我们可以得到一个干净、整洁的数据集,为后续的分析打下坚实的基础。
数据分组与聚合
在实际的数据分析中,我们经常需要对数据进行分组并应用各种聚合函数。Pandas的groupby方法可以帮助我们轻松实现这一功能。通过groupby方法,我们可以按照某个或多个列对数据进行分组,并对每个组应用各种聚合函数(如求和、平均值、最大值等)。这样,我们就可以快速地得到每个组的统计信息,为后续的分析提供有力支持。
三、Pandas实战案例
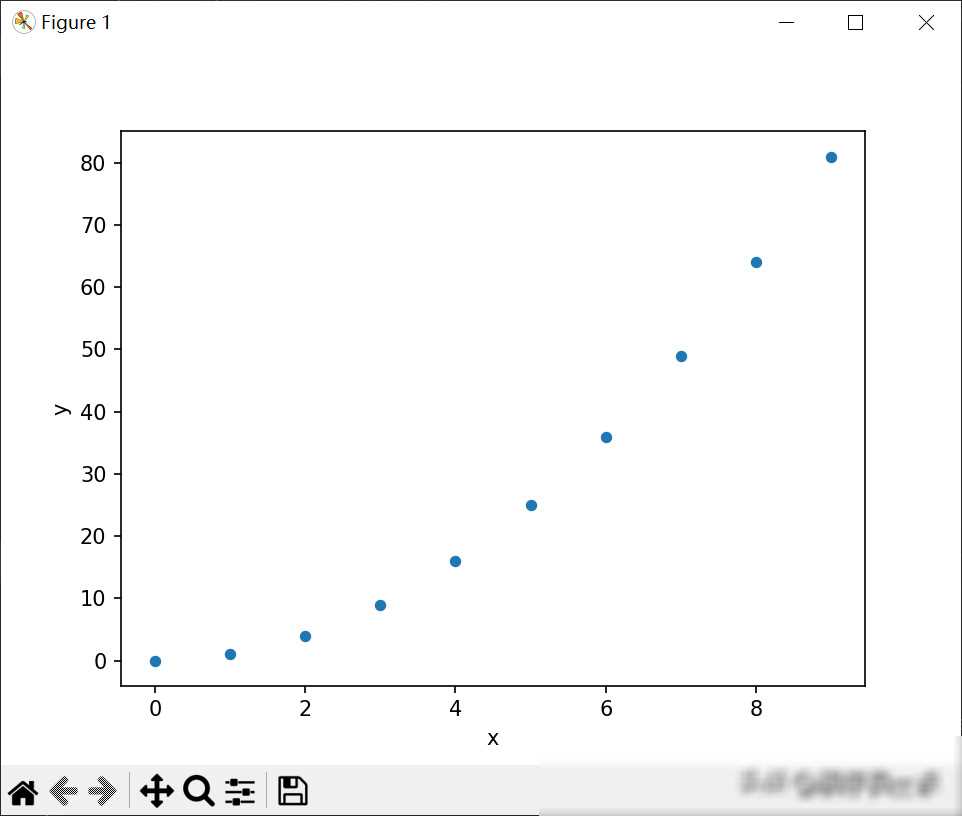
为了更好地展示Pandas在数据分析中的实际应用,下面我们将通过一个具体的案例来进行说明。
假设我们是一家电商公司的数据分析师,现在需要分析公司的销售数据。我们使用Pandas读取了销售数据的CSV文件,并将其存储在一个DataFrame中。接着,我们对数据进行了清洗和预处理,删除了缺失值和重复数据。然后,我们按照商品类别对销售数据进行了分组,并计算了每个类别的销售额和销量。我们使用Matplotlib将销售额和销量的数据可视化展示出来,以便更直观地了解销售情况。
通过这个过程,我们可以看到Pandas在数据分析中的强大功能。无论是数据的读取、清洗、分组还是可视化展示,Pandas都能提供简单易用的操作方式。这使得我们能够更加高效地进行数据分析,为公司的发展提供有力支持。
四、Pandas的未来发展
随着大数据和人工智能技术的不断发展,数据分析领域也面临着越来越多的挑战和机遇。作为数据分析领域的重要工具之一,Pandas也在不断地发展和完善自己。未来,我们可以期待Pandas在以下几个方面取得更大的突破:
性能优化:随着数据量的不断增长,对数据分析工具的性能要求也越来越高。Pandas将继续优化其算法和数据结构,提高数据处理的速度和效率。
扩展性增强:为了更好地支持各种数据类型和分析需求,Pandas将不断扩展其功能。例如,加强对非结构化数据的处理能力、提供更多样化的可视化展示方式等。
集成性提升:数据分析往往需要与其他工具和技术进行集成。Pandas将加强与其他工具和技术的集成能力,如机器学习库、数据库等,为用户提供更加便捷的数据分析解决方案。
总之,Pandas作为数据分析领域的重要工具之一,将继续发挥其强大的功能和易用性特点,为数据分析师和数据科学家提供有力的支持。让我们期待Pandas在未来的发展中取得更大的突破和成就!