
数据一致性与缓存性能:如何提升你的系统速度与可靠性?
数据一致性与缓存性能:如何提升你的系统速度与可靠性?
亲爱的读者朋友们,今天我们将一同深入探讨分布式系统中的一个长久以来被讨论的话题——双写一致性与缓存性能的关系。这不仅是性能优化的关键所在,更是提升用户体验的重要途径。在这篇文章中,我们会详尽分析相关的解决方案、策略和真实案例,帮助你掌握这些概念的应用和实践。
一、现代分布式系统概述
现代分布式系统的设计理念强调了跨多个服务器或者计算节点分担负载,并在此过程中实现高效的数据处理和存储。通过这种架构,企业能够处理更大规模的数据,提供更高的可用性和更快的响应速度。
在分布式系统中,数据库作为核心的数据存储工具,负责处理大量的数据读写请求,而缓存则作为一个临时存储层,用以加速数据访问。笔者在此引用一项研究,数据显示:在合理使用缓存的情况下,系统的响应速度可以提升60%以上。
使用数据库和缓存组合的关键在于如何保持数据的一致性与可靠性。这种数据一致性问题尤为重要,尤其是在高并发环境下。例如,当多个用户同时更改同一数据时,可能会导致缓存和数据库之间的数据不一致,影响用户体验和系统稳定。
更加重要的是,要采用有效的策略来确保双写一致性。这种一致性机制能确保在更新操作时,数据同时更新到缓存和数据库中,从而避免数据不一致的问题。
二、分布式系统中的缓存机制
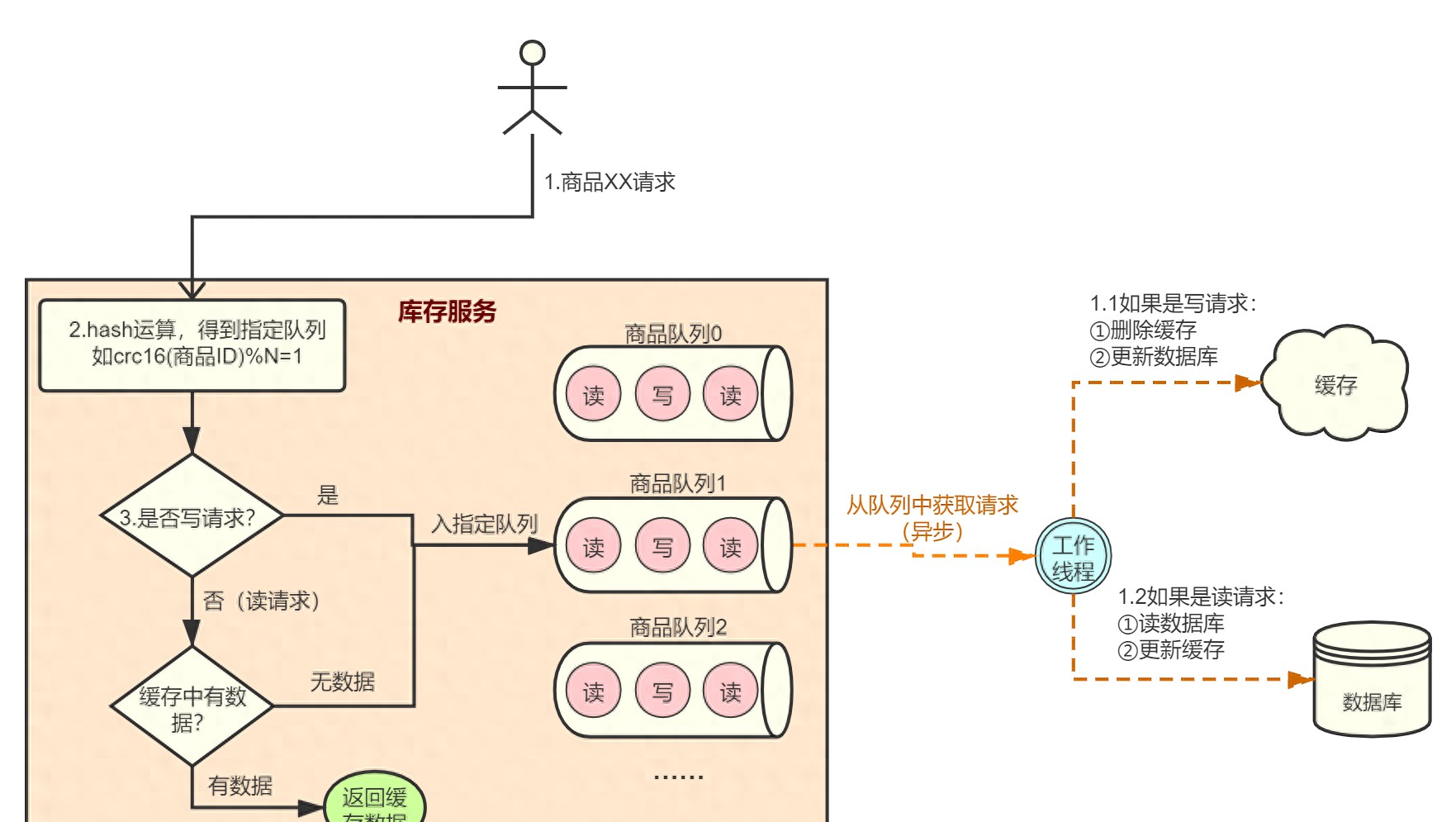
缓存的基本工作流程可以概述为:系统在接收到用户请求时,首先会检查缓存中是否存在所需数据。如果存在,则直接返回;如果不存在,再从数据库中检索,并更新缓存以便后续快速访问。通过这种“先缓存查找”的方式,大大提升了数据获取的效率。
双写一致性作为缓存机制中的核心概念,强调整个操作过程中如何确保缓存与数据库数据的同步。根据一项报告,60%的企业在实施双写一致性机制后,发现系统的整体稳定性和用户满意度得到了显著提高。
实现双写一致性的方法有多个,如通过结合使用乐观锁和悲观锁来减少并发问题。乐观锁在资源修改前不会进行加锁,而是在提交时才验证数据是否被更改。如果被更改,则拒绝当前操作,从而避免不必要的等待。反之,悲观锁则在资源被读取或修改时即加锁,确保其他操作无法并发进行。
三、缓存性能优势分析
3.1 内存访问速度
内存访问速度是缓存相比数据库的一大优势,通常可以达到纳秒级别的读取速度。而数据库一般依赖于磁盘进行存储,读取时间往往需要几毫秒乃至更长的时间。这种巨大的差距意味着,在处理频繁的数据访问时,缓存可以极大地减轻系统的负担。
以一个在线电商为例,假设有1000个用户同时浏览商品页面,如果仅依赖数据库,即使是轻量级的查询操作也可能造成数秒的延迟。然而,通过合理使用缓存,系统可以在瞬间响应用户请求,使得购买体验流畅无阻。
3.2 减少I/O操作
通过保障热点数据存储在缓存中,减少冗余的I/O操作,不仅提升了查询响应速度,也极大地减轻了数据库的负载。这也意味着,数据库能将更多的性能资源用于处理复杂的事务并确保数据安全。
以Netflix为例,Netflix利用缓存技术,全球服务器每年都能处理数十亿的流媒体请求,极少出现短暂的片源卡顿,因为它有效地将常用数据缓存在接近用户的位置。
3.3 本地化访问的优点
在分布式系统中,缓存一般会被部署在接近应用程序的环境中,这意味着数据传输延迟将大幅减少。这种近距离的访问提升了数据传输效率,并进一步增强了用户体验。
以Facebook为例,用户在任何地方发布的内容几乎可以在瞬间展现给他们的朋友,得益于其全球多个分布式数据中心和高效的缓存策略。
四、实现双写一致性的步骤
4.1 更新数据库
在进行双写一致性操作时,确保在
在执行更新时,确保数据的完整性和安全性,及时处理异常情况。例如,使用 SQL 语句进行数据更新时,必须通过捕获异常来处理更新失败的情况,以避免数据的错误修改。
4.2 同步缓存数据
当数据库中的记录成功更新后,一定要同步更新缓存中的数据。通常,这可以通过向缓存系统发送命令进行,例如使用Redis的set命令。在这一步,若能够为常用的数据设置一个过期时间或者使用持久化机制,也能更好地保障数据的一致性。
缓存更新失败的风险也存在,因此最好在更新缓存之前先检查这个数据是否真的存在于缓存中,以免产生不必要的错误。
4.3 分布式事务与补偿机制
分布式系统中的操作往往涉及多个服务或者数据库,确保操作的原子性和一致性非常重要。这通常通过分布式事务来实现,例如使用两阶段提交(2PC)机制。
两阶段提交在性能上会存在一定的瓶颈。因此,很多企业更倾向于使用一种补偿机制。在操作失败时,可以通过回滚已完成的操作,保证数据最终一致性,而不必等待整个操作完成。例如,支付宝的分布式事务模型就是运用补偿机制确保交易的可靠性。
五、缓存更新策略
5.1 写后读(Write-Through)
写后读策略是指在数据被修改时,立即将修改的数据同步到缓存中。这种方式可以有效保持数据的一致性,但由于每次写操作都需要更新缓存,会导致性能下降。适合一些对数据一致性要求非常高的场景。
金融应用中的账户余额更新时,如此机制可有效防止在查询时获取到旧数据。
5.2 读后写(Write-Around)
读后写策略在数据变化时只更新数据库,而不对缓存进行操作。后续的读取命中缓存,将返回旧值;若未命中,则需要从数据库中重新加载并更新缓存。
优点在于可以降低写操作对缓存的频繁更新,从而提高缓存的命中率,但缺点是短期内缓存中可能存在陈旧数据,适合一些不太频繁读取但更新频繁的数据场景。
5.3 写旁路(Write-Behind)
写旁路策略会将更改记录到日志或队列中,然后异步地将这些更改应用到缓存中。此方式适合对性能要求极高但对一致性要求相对宽松的应用。它能够显著提升写操作的效率,但要注意在短期内可能导致一致性问题。
这一策略在内容发布系统中应用广泛,允许用户在进行内容修改时获得即时反馈,而后台进行相关缓存的更新。
六、电商网站实例分析
以电商平台为例,用户下单时涉及到商品库存与订单表的更新操作。这时,采用双写一致性策略会显得尤为重要。具体操作:
在订单提交过程中,首先在数据库的事务中同时更新数据库库存信息与订单数据,确保一致性。这一过程通过使用分布式事务来实现,并保障交易的可靠性。
最新的库存状态会被同步到缓存系统(如Redis)中,以便后续查询响应迅速。这样一来,即使在高峰时段,用户也能快速获得需要的信息,提升整体用户体验。
通过这个实例可以看到,合理应用双写一致性和缓存策略,不仅能保持整体系统的一致性,更能够在极大程度上提升访问速度和用户满意度。
欢迎大家在下方留言讨论,分享您的看法!