
提升大语言模型精炼能力的创新方案:MAGICORE框架揭秘
提升大语言模型精炼能力的创新方案:MAGICORE框架揭秘
亲爱的读者朋友们,今天我们将深入探讨一个当下备受关注的话题——大语言模型(LLM)的精炼过程,以及由此而来的创新方案——MAGICORE框架。我们将围绕MAGICORE的核心概念、关键挑战和解决方案展开讨论,特邀您一起探索其中的技术细节以及其背后的逻辑。
一、引言
大型语言模型的崛起让我们对人工智能的未来充满期待,它们在自然语言处理、文本生成、翻译等任务中展现出惊人的潜力。然而,LLM的推理能力仍面临诸多挑战,尤其是在参数选择和决策过程中,如何高效地获得准确的答案成了许多研究者的难题。现有的聚合策略虽然可以通过收集多个答案来提高模型准确性,但其限制在于,单纯的采样数量增加并不会一味地带来更好的效果,往往存在一旦达到某个点就不再改进的现象。
在这篇文章中,我们将详细解读MAGICORE框架的各个方面。通过理解这个框架如何在多个数据集上提升LLM的推理能力,我们能更深入地掌握大语言模型的潜力,并为自己在这一领域的实践提供参考。
二、MAGICORE框架概述

框架结构
MAGICORE,即多代理迭代框架,旨在通过有针对性的反馈来提高LLM的多步骤推理能力。本框架包含三个核心角色——Solver、Reviewer和Refiner,形成了一个完备的反馈闭环。Solver负责生成初始解决方案,Reviewer则在此基础上为生成的推理链提供针对性的反馈,而Refiner则利用这些反馈不断精炼推理链,从而不断提高输出的质量。
模型评估器
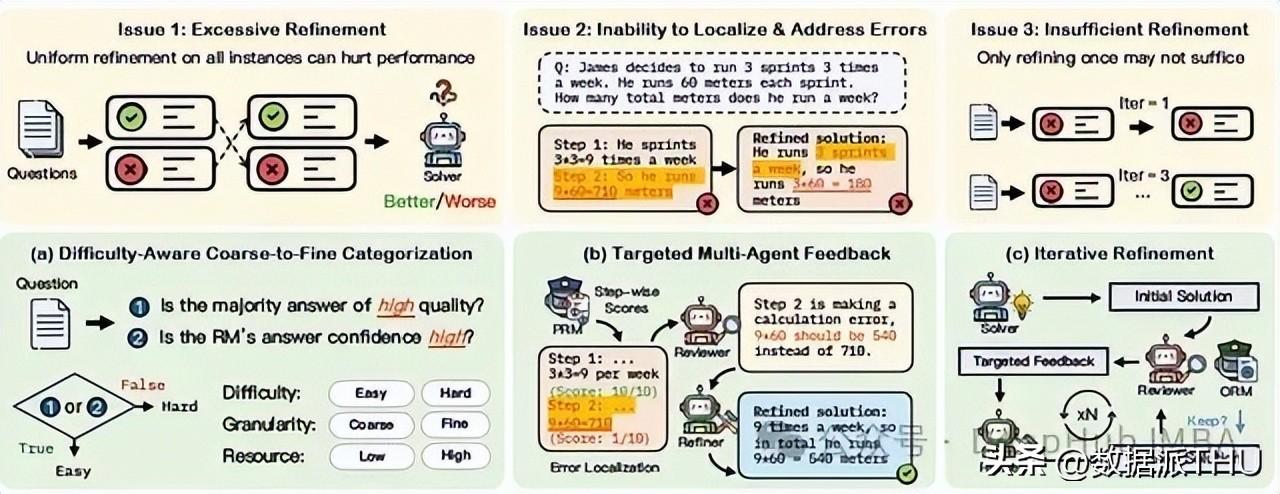
MAGICORE引入两种奖励模型:结果奖励模型(ORM)和过程奖励模型(PRM)。ORM用于评估整体解决方案的正确性,而PRM则负责监控逐步过程中的准确性。通过这种双重评估机制,MAGICORE不仅提高了模型的自我纠错能力,还增强了推理过程的透明性,让用户可以更容易地追踪到模型的决策链,确保算法执行的可信度。
三、精炼过程中的关键挑战
过度精炼
从字面上看,精炼似乎是提升模型输出的关键。然而,盲目追求精炼往往会导致过度校正,即把正确的解决方案调整成错误的结果。研究指出,这种情况在对所有实例进行统一精炼时尤其明显,因为模型可能会忽视那些本没有问题的答案,反而将其调整得面目全非。为了防止这种情况的发生,MAGICORE采用了粗到细的精炼策略,促使模型在精炼时考虑具体的上下文和问题的复杂程度。
无法定位和解决错误
另一问题是LLM的自我纠错能力有限。在推理过程中,很多模型不能有效识别出自身的错误并在后续步骤中进行纠正。这就需要引入多代理设置,通过Reviewer对推理链中每一步的细致检查,确保任何潜在的错误都能被及时发现并加以修正。通过这样的反馈回路,MAGICORE能智能地识别并解决错误,进而提升答案的质量和可信度。
精炼不足
有效的精炼应该是一个迭代过程,而不仅仅是一次性改进。过早停止精炼可能导致错误没有被纠正,从而影响结果的有效性。MAGICORE设计了多个精炼轮次,自适应地识别何时需要进一步精炼。这种通过不断迭代来寻找最佳方案的策略,确保了不仅能维持高效的推理过程,同时也能最大限度降低出错率。
四、MAGICORE的解决方案
粗到细的精炼策略
MAGICORE框架的核心在于根据问题的难度自动调整处理策略。如果一个问题被标记为简单,模型将使用粗粒度聚合方法,快速输出结果。而对于那些更为棘手的问题,聚合后将引入细粒度的多代理精炼。这种精炼方式不仅提高了模型的适应性,也避免了对简单问题的过度优化。
多代理设置的优势
在MAGICORE中,使用多个代理的设置使得整个推理过程更为灵活。Solver负责生成多个解答,Reviewer则根据ORM和PRM对每个解答评分,以此确保每个解答的质量,Refiner则在此基础上进行细致的改进。这样的多层次协作降低了单一代理可能带来的误差,提高了整体推理的准确性。
迭代精炼过程的细节
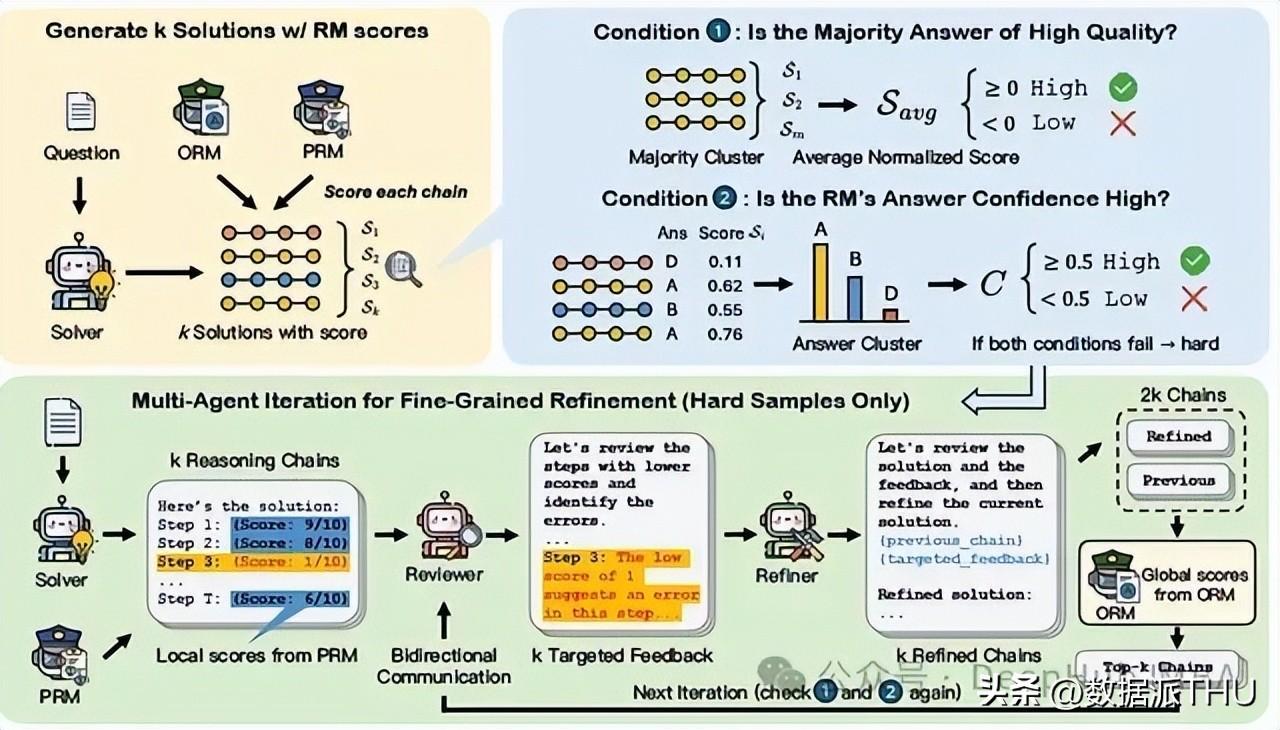
在迭代精炼过程中,每一轮的回馈都会为下轮的解答提供新的视角。比如,当Refiner根据Reviewer的反馈对推理链进行改进时,便利用了大量的反馈信息,从而实现了目标导向的优化。通过不断的迭代,MAGICORE确保无论是在简单问题还是复杂问题面前,模型都能够进行有效的自我调整和优化。
五、性能评估与实验结果
方法的表现对比
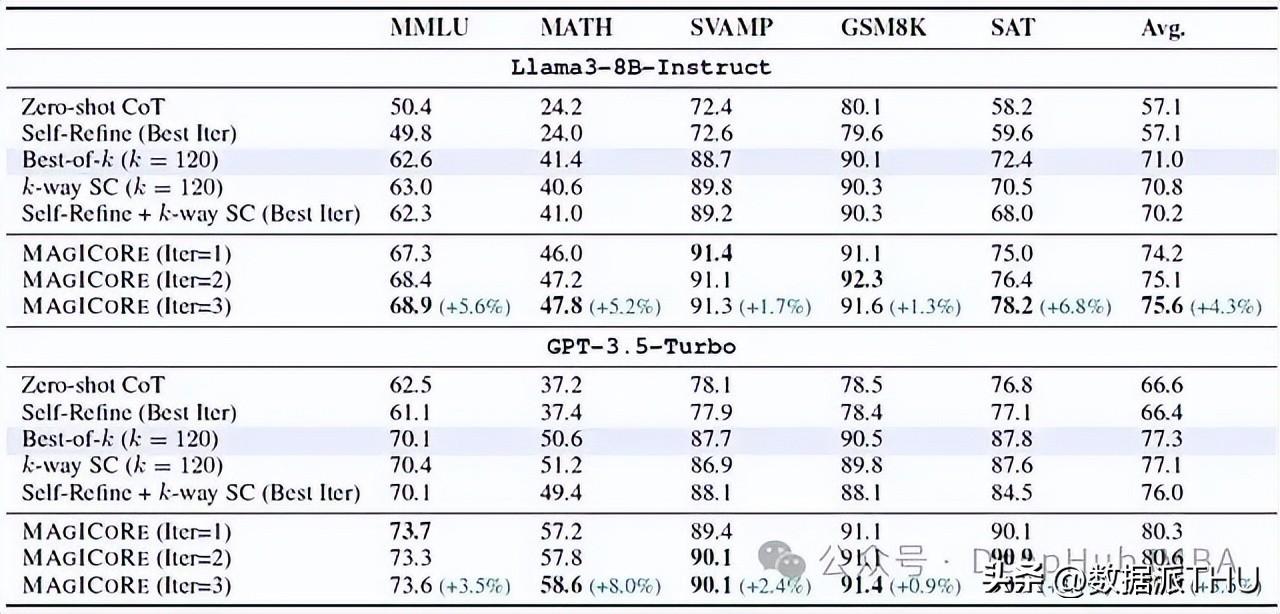
MAGICORE在多组测试中相较于传统的聚合策略和单一的精炼方法展现出了显著的优势。例如,在Llama-3-8B模型上,MAGICORE方法的平均提升达到了3.2%,而在部分困难问题上,改进的幅度则更为明显。这无疑为MAGICORE的有效性提供了坚实的数据支撑。
数据集与模型表现
MAGICORE经过五个不同数学数据集的测试均表现优异,从MMLU到MATH,各项成绩均超出传统方法。这证明了其在多样化数据处理上的适应性与优势。经过严格的实验设计与数据分析,MAGICORE不仅稳定地解决了复杂的推理任务,更达成了高质量的输出,这在现代算法竞赛中极具参考价值。
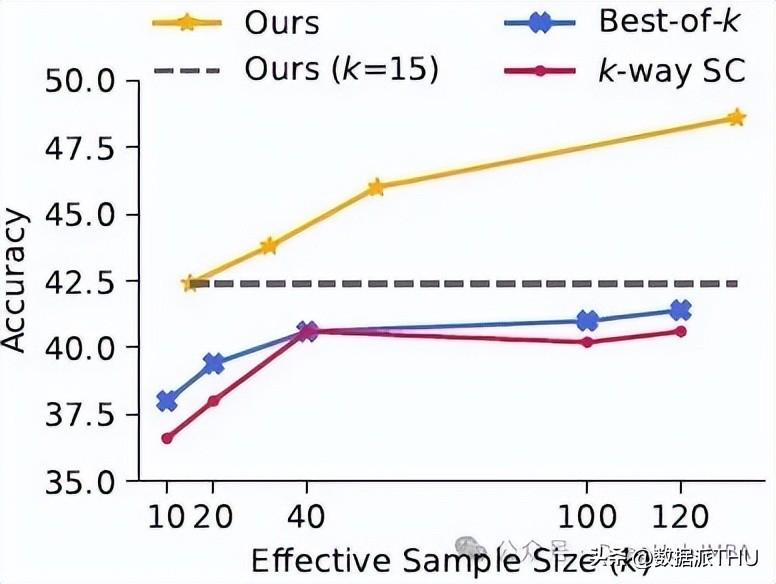
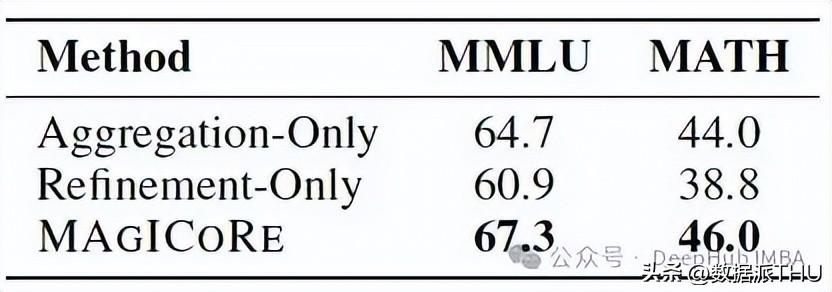
关键指标分析
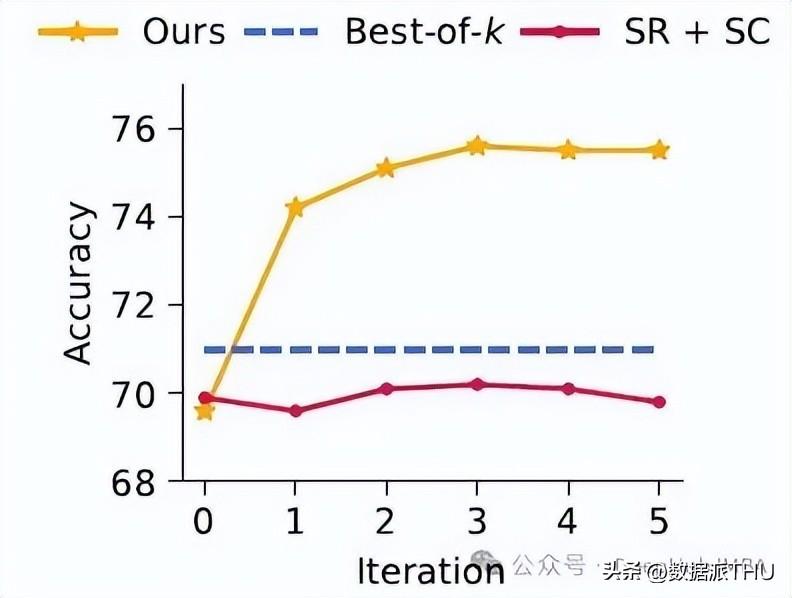
通过多维度的考察,MAGICORE展现出了良好的样本效率和迭代改进能力。在使用8倍少的样本情况下,MAGICORE依旧优于一般的k-way SC。这意味着,无论在资源如何受限的情况下,MAGICORE都能够找到更优的解决方案,极大地提高了LLM的应用价值。这也为其他领域的模型设计提供了借鉴。
六、实践建议
在应用MAGICORE框架时,可以考虑以下意见。首先,选择合适的数据集进行初步实验,观察模型在特定种类问题上的表现。其次,监控每一轮精炼的效果,确保通过ORM和PRM所提供的反馈能够准确指引Refiner进行有效改进。最后,建议持续对模型进行调试和优化,这样能够更好地适应实时变化的任务需求。

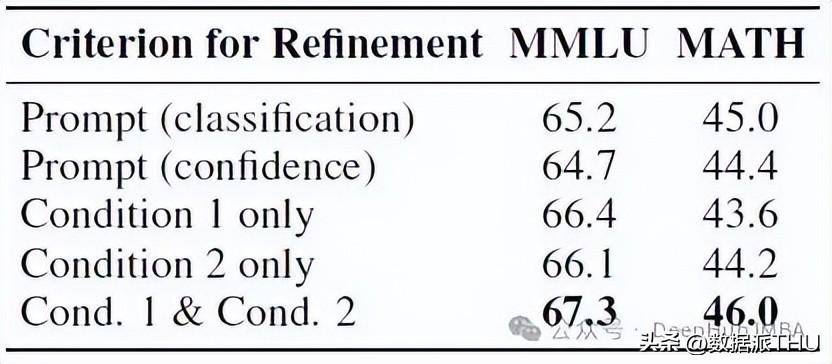
欢迎大家在下方留言讨论,分享您对MAGICORE框架的看法以及在使用大语言模型过程中的独特见解!