
深度解析Fire-Flyer AI-HPC框架:高效、经济、低耗能的未来计算利器
深度解析Fire-Flyer AI-HPC框架:高效、经济、低耗能的未来计算利器
亲爱的读者朋友们,随着深度学习(DL)和大型语言模型(LLM)需求的疯涨,传统计算架构正面临着前所未有的挑战。如何在保证性能的同时降低成本和能耗,成为业界迫切需要解决的难题。今天,我们来深入探讨一项前沿技术——Fire-Flyer AI-HPC框架,它用实际案例为我们提供了低成本与高效能的完美平衡。
一、系统规格

Fire-Flyer II架构由1万台PCIe A100 GPU组成,迅速崛起为深度学习领域的佼佼者。这一架构不仅实现了接近NVIDIA DGX-A100的性能,而且还显著降低了成本与能耗。具体来看,使用此架构所需的资源成本下降了近50%,能源消耗降低了40%,这在当前能源短缺和环保要求日益严格的环境下,无疑是一个巨大的优势。
为了更好地理解这一系统的构成,我们可以将其看作一个强大的计算引擎,基于先进的硬件架构优化与智能调度算法,使得每个GPU的计算能力得以充分释放。特别是在大规模数据处理和模型训练流程中,其优秀的并行计算性能和快速的I/O能力,让人眼前一亮。
在基准测试中,Fire-Flyer II框架在TF32和FP16的性能表现上,能够达到NVIDIA DGX-A100的83%左右,这意味着尽管在硬件上投资相对较少,但性能几乎不打折扣。这种高效的资源利用率,使得Fire-Flyer II不仅仅是一个技术方案,更是一个机遇性的发展方向,改变了计算资源的使用模式。
二、硬件配置对比
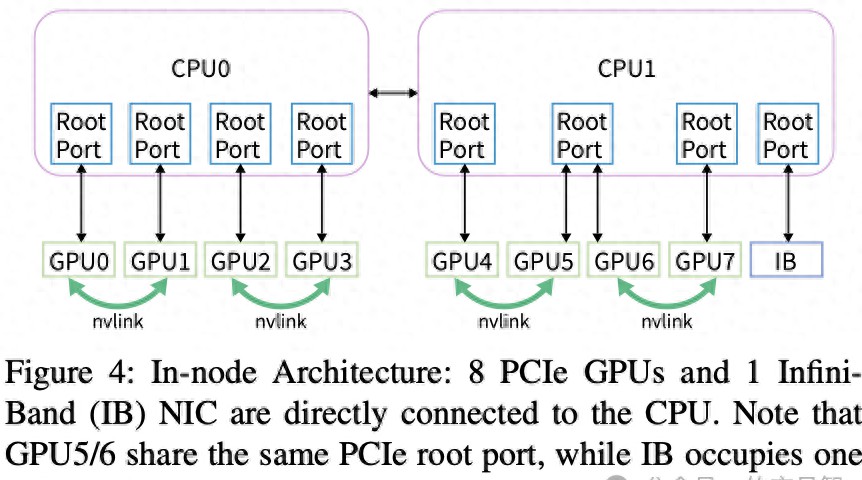
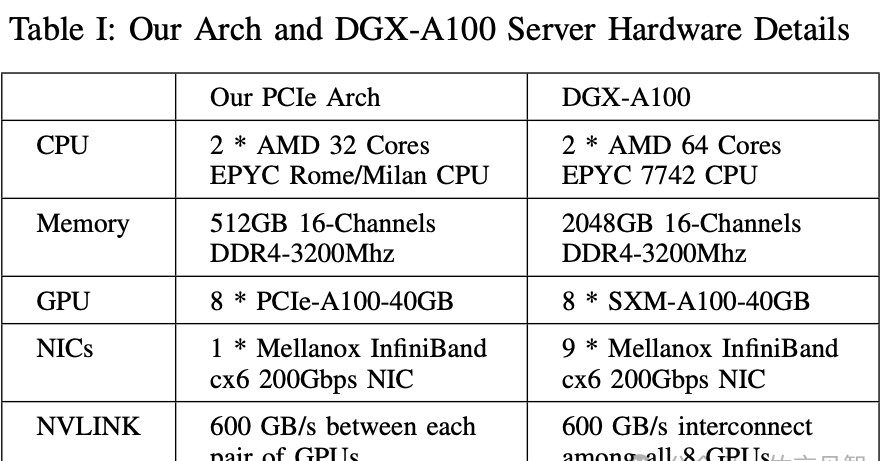
在硬件配置中,Fire-Flyer II与NVIDIA DGX-A100架构的比较,清晰地显示出其优势。Fire-Flyer II的PCIe A100架构在内存、网卡及其NVLink连接上具有明显不同。例如,DGX-A100架构中含有更多的NVLink连接,提供了更好的GPU间数据传输能力,但PCIe A100架构通过控制网络带宽与成本,更加适合资源受限的企业环境。
在具体的应用场景中,Fire-Flyer II展现出出色的性能,尤其是在并行计算和高带宽需求的任务中。例如在处理大规模数据集(如ImageNet)时,其稳定的计算速度让用户非常满意,缩短了训练模型所需的时间,大幅提高了整体生产力。
在选择适合自己需求的架构时,企业应该考虑自己的工作负载特征。如果是需要大量数据传输的深度学习任务,Fire-Flyer II无疑是一个值得关注的选择。
三、网络拓扑与计算存储集成
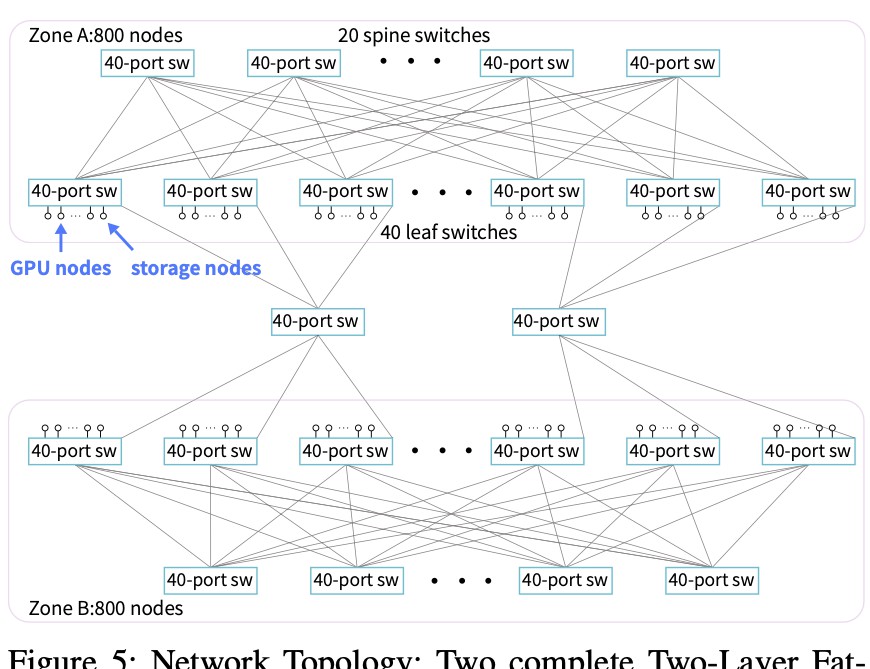
Fat-Tree拓扑选用的原因值得深入探讨。这种网络结构因其高对分带宽特性,在数据中心布局中表现尤为出色。其实,Fat-Tree拓扑通过将流量流向两层架构的交换机,允许多个服务器并行通信,这大大提高了流量利用率,并降低了网络拥塞的风险。在实现上,Fire-Flyer II使用了200Gbps的CX6 InfiniBand网卡,增强了计算和存储间的通信能力。这种高带宽连接使得GPU计算节点的协作愈加紧密,有效提升了整体性能。
进一步来说,多区域网络配置的选择同样至关重要。通过将计算节点分布在不同的区域,Fire-Flyer II能够在不增加系统整体复杂度的前提下,优化网络带宽和降低成本。这一构架不仅支持高效的数据流,还能充分利用存储服务器的能力,保证每个GPU计算节点都能够快速访问到数据,确保了快速且一致的计算体验。
值得一提的是,HAI Platform调度策略的引入,通过智能算法确保跨区域的计算任务得以高效调度,避免了任何一对节点间的数据过量传输,真是令架构的性能再上一个台阶。这种智能调度不仅提升了计算资源的利用率,还在显著降低了通信延迟。
四、HFReduce算法及其优化
HFReduce算法的推出,代表着在软硬件协同设计上的一大突破。这一算法的设计旨在解决传统allreduce通信的瓶颈,能够显著提高计算效率。通过减少PCIe带宽的使用和减少GPU Kernel的额外开销,HFReduce实现了节点内和节点间的高效通讯。
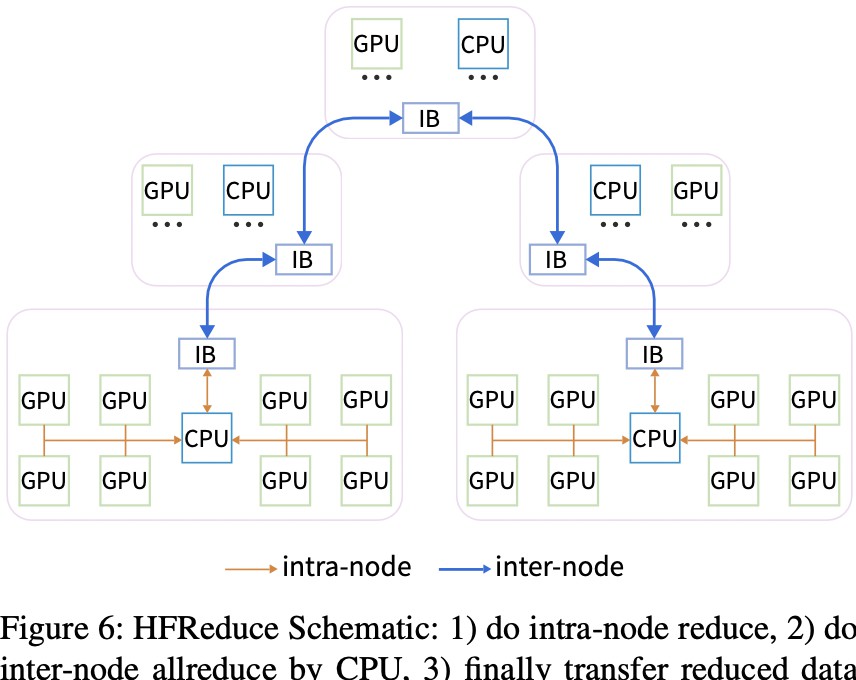
HFReduce的结构可以分为两个阶段:节点内reduce和节点间reduce。在节点内,CPU通过SIMD指令高效处理GPU上的梯度数据,可以使用GDRCopy或MemCpyAsync技术来优化数据传输。当数据到达内存后,CPU使用向量指令进行reduce操作,显著降低了延迟。
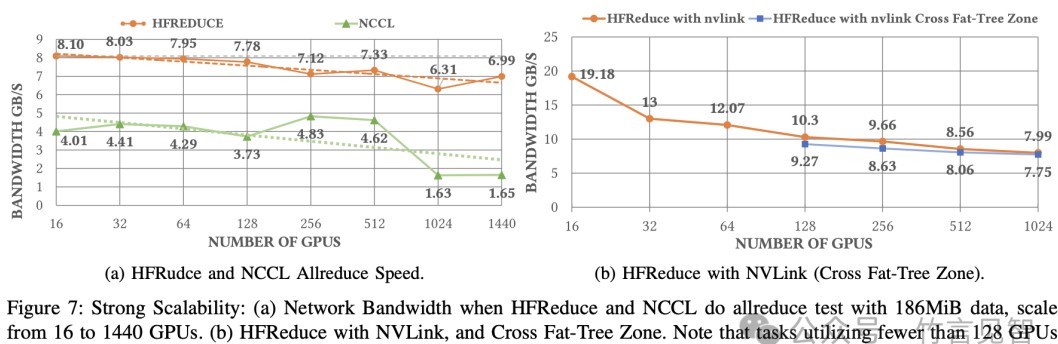
在节点间的reduce阶段,HFReduce通过双二叉树算法促进数据传输,相比于传统的NCCL,HFReduce能够实现6.3-8.1GB/s的节点间带宽,而NCCL的节点间带宽仅为1.6-4.8GB/s。这里类似的案例可以参考谷歌在TPU上的应用,通过类似的优化手段提高了训练速度。
HFReduce的引入,不仅仅是技术上的进步,它为大规模计算提供了非常适用的方案。尤其是在进行大规模模型训练时,能有效降低时间与成本,对于像Facebook、Google等大型互联网公司,无疑是一个显著的优势。
五、HAIScale及3FS支持的DL训练
HAIScale DDP训练工具是优化深度学习训练的重要组成部分,它专注于与HFReduce的黏合使用。在实际操作中,通过异步allreduce,HAIScale能够确保计算和通信同时进行,大大提高了训练效率。
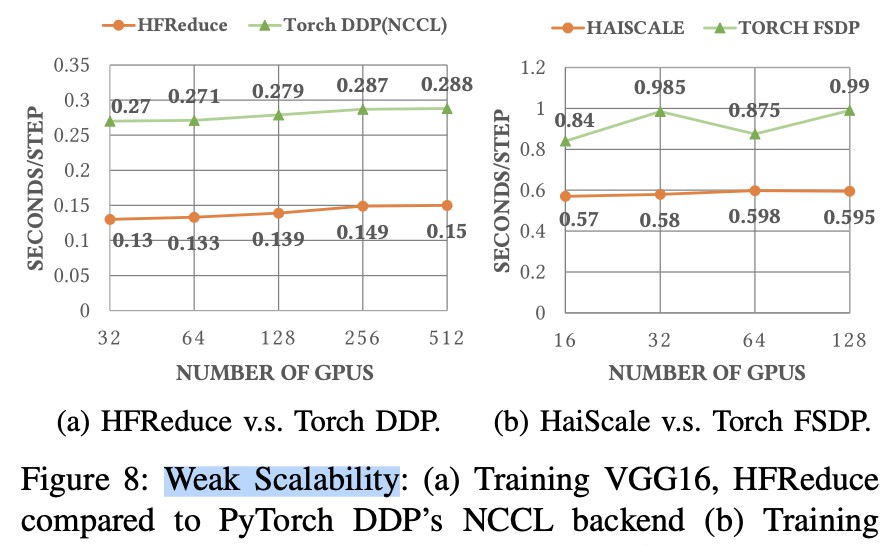
在性能对待上,通过HFReduce训练VGG16模型所需的时间仅为使用Torch DDP时的一半。这种高效性在为用户节省了显著的计算时间的同时,也使得测试与迭代变得更加迅速,尤其对需要频繁调整参数的深度学习任务尤为重要。
3FS高性能分布式文件系统同样不容忽视。3FS配备了180个存储节点,每个节点都配备了高速的PCIe NVMe SSD和Mellanox 200Gbps InfiniBand HCA。它的设计充分挖掘了NVMe SSD和RDMA网络的潜能,使得读写速度可以达到8TB/s,大幅度提高了数据的处理能力。对于需要海量数据存储的深度学习任务,3FS能够保证高速读取和写入,极大地提升了系统的整体效能。
为了优化操作,3FS采用了链式**与元数据存储策略,这在快速并发访问上得到了极大的提升。这种灵活性不仅让用户在处理海量数据时如鱼得水,还能保证数据的持久性与一致性。

六、系统鲁棒性与稳定性保障
检查点管理与恢复系统是保证Fire-Flyer II稳定性的重要手段。针对神经网络训练过程中可能发生的故障,通过检查点管理技术,用户不仅可以快速完成训练过程中的数据保存,也能在发生故障时迅速恢复到最近的计算状态。这种措施不仅降低每日的修复时间,还为用户节省了大量资源。

验证工具的使用同样不可忽视,它确保了设备的正常功能和稳定性。为此,系统会定期对每个节点进行检测,如检查链路速度、测试存储带宽、监控GPU内存使用情境等等,尽第一个时间消除潜在故障。这种严密的保障手段,让人倍感安心,从而将用户的注意力聚焦在创新与优化上。
需要注意的是,硬件故障的识别与处理也至关重要。每当数据中心遇到可能的硬件故障时,系统通过记录相关日志与错误监测,能够快速分析出问题来源,帮助用户在最短时间内进行系统维护,保证业务的高速运转。
七、系统与DGX A100的对比
在对比Fire-Flyer II与NVIDIA DGX A100架构时,我们看到了两者在性能、互联及成本上的差异。也许最明显的就是Fire-Flyer II对成本的精准控制,它凭借少量交换机便能支持相同规模的计算,而在数据互联上,Fire-Flyer II通过选用的角色及服务分布,做到了性能的最大化。
尤其在当前GPU资源紧缺的环境下,Fire-Flyer II为中小企业提供了一种新的解决方案,不再需要庞大的资金投入便可以实现高效的深度学习训练。这种适应性不仅提升了计算资源的可得性,更大幅度降低了整体运营成本,对资源有限的机构无疑是一个福音。
Fire-Flyer II还有可能随着技术的不断进步,推出更多可搭载的计算组件与替代方案,进一步优化网络架构与计算性能。用户在选择系统时需要结合自身需求,关注新技术应用的尝试和实际成效。
欢迎大家在下方留言讨论,分享您的看法!希望本文能帮助大家更好地理解Fire-Flyer AI-HPC框架,提升自身在深度学习领域的决策能力。