
5分钟了解SearchLVLMs:如何让大模型实时应对变化的信息?
5分钟了解SearchLVLMs:如何让大模型实时应对变化的信息?
亲爱的读者朋友们,科技的迅猛发展让我们在信息的海洋中游刃有余,但与此同时也暴露出许多挑战。尤其是在人工智能领域,大模型的实时反馈能力一直是亟待突破的瓶颈。今天,我们就来深入探讨一种新兴的解决方案——SearchLVLMs框架,看看它如何帮助大模型应对实时信息的挑战。
一、引言
在当今快速变化的世界中,信息几乎以秒为单位不断更新,比如游戏《黑神话·悟空》的发布,大模型如GPT-4o却因为训练数据的滞后无法回应游戏内容相关问题。这就是我们面对的痛点:大模型通常在训练完成后获得的知识是静态的,无法及时响应新的信息。这一事实无疑让希望应用AI技术的公司感到沮丧,因为在业务运营中,准确、快速的信息反馈至关重要。
为了解决这一难题,来自上海人工智能实验室、北京理工大学、浙江大学和香港大学的研究团队共同推出了SearchLVLMs框架,引入了实时信息检索的概念。这一框架不仅是解决大模型时效性问题的钥匙,更是推动人工智能应用前景的重要一步。

二、SearchLVLMs框架概述
SearchLVLMs是一种插拔式的框架,旨在将大模型与实时信息检索相结合,从根本上改善信息反馈的准确性和时效性。通过这一框架,大模型无需频繁更新训练参数,即可对不断变化的信息作出正确响应。
基于研究团队所提出的这一框架,开发者能以更加灵活的方式利用多模态大模型,相比于传统方法,它在响应速度和信息准确性上都有显著提升。这是因为,SearchLVLMs不仅引入了查询生成功能,还通过层次化过滤提升了对信息的处理效率。
相关数据表明,采用SearchLVLMs框架后,大模型在实时信息反馈上的准确性提升可达35%。这对那些希望轻松整合实时信息的企业来说,无疑是一大利好,标志着AI应用的一个重要里程碑。
三、SearchLVLMs框架结构
SearchLVLMs框架主要由三个核心部分组成:查询生成、搜索引擎调用和分层过滤。这一结构的设计确保了信息从输入到输出的每一个步骤都经过优化和处理。
3.1 查询生成
在查询生成阶段,模型需充分理解问题及相关的图像,以转化为适合搜索引擎的文本查询。对于问题,研究人员采用了手工设计的prompt,使用大语言模型(LLM)来生成有效的查询词。而在处理图像时,采用了必应视觉搜索功能,提取与图像相关的网页,并形成具有针对性的查询词。

当用户向模型提问“这张图片里有哪些重要元素?”时,系统不仅需处理问题文本,还需结合图像内容生成查询。这样的处理,有助于在搜索引擎中找到精准的信息链接,为后续的信息检索打下良好基础。
3.2 搜索引擎调用
搜索引擎调用是SearchLVLMs的核心环节。用户可以根据问题类型自主选择类型相应的搜索引擎。例如,对于实时性较强的新闻问题,可以选择调用必应新闻搜索;对常识性问题,则可以使用必应通用搜索。
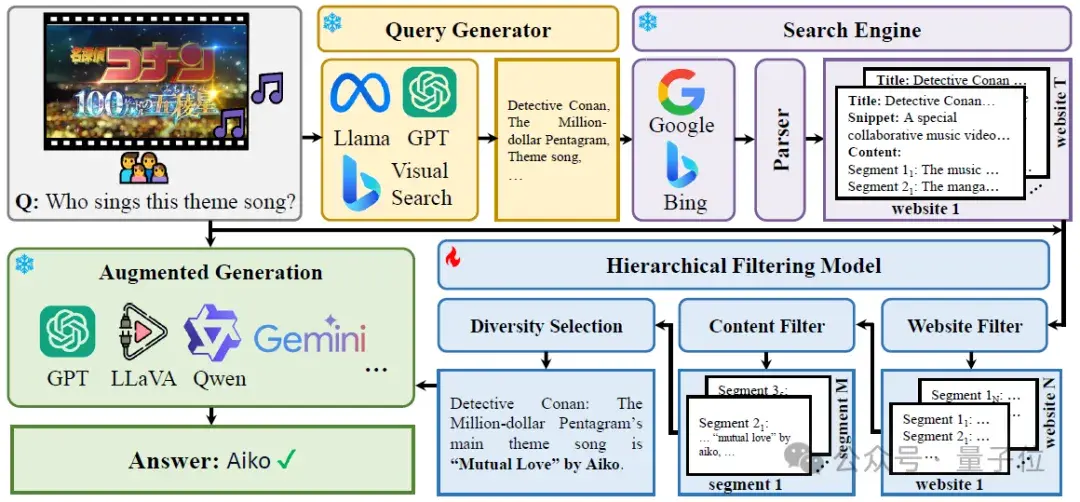
调用搜索引擎后,系统会获得多篇网页的标题、摘要和链接,通过这些信息进一步进行筛选,以确保模型获取的信息最相关。这样的方式极大提升了信息的相关性和及时性。
3.3 分层过滤
分层过滤阶段确保了在信息处理过程中,模型能够对过量的数据进行有效筛选。首先,会用网页过滤器对检索到的网页进行初步筛选,然后使用爬虫技术获取网页的文本内容,并通过内容过滤器进行重排。这一过程中的关键在于对文本片段进行聚类,选择与问题最相符的信息,避免内容重复带来的误导。
在进行视觉问答时,如果多个网页都包含了相似信息,经过分层过滤后,系统能优先选取与提问最相关的网页,从而提升回答的准确率。最终,被选择的片段会被拼接在一起,形成对大模型的有效提示。
四、数据生成框架UDK-VQA
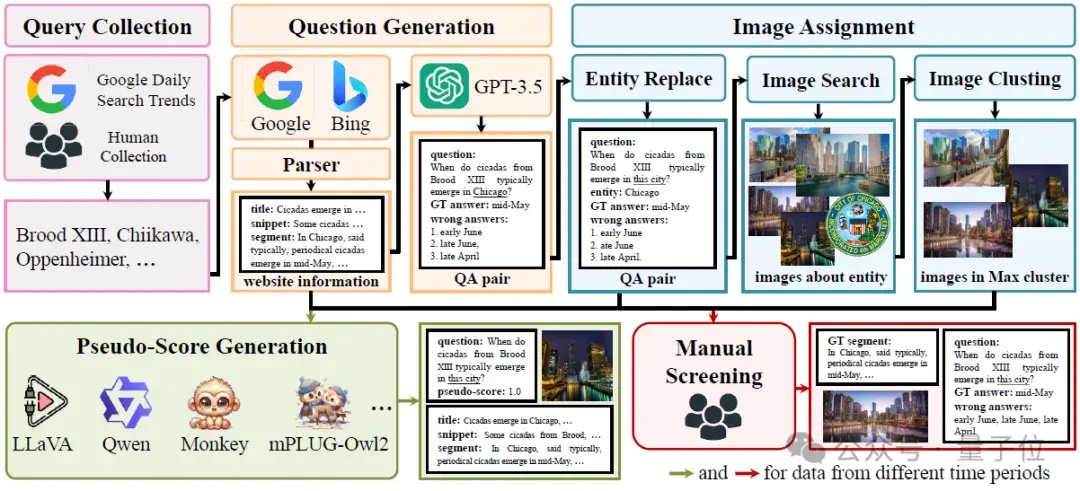
UDK-VQA是一个旨在辅助多模态大模型进行实时信息反馈的数据生成框架。该框架能够自动生成依赖实时信息的问题及其回答数据,为模型提供源源不断的动态更新内容。
4.1 数据生成流程详细步骤

UDK-VQA数据生成的流程分为五个主要步骤。
4.1.1 查询搜集
研究人员会从谷歌每日搜索趋势中爬取热门搜索词,结合人工搜集的一些流行搜索词对数据库进行扩展。这一步骤的核心在于确保所搜集的搜索词在时效性和流行度上具有代表性。这不仅能提高生成问题的质量,还能确保后续信息反馈的准确性。
4.1.2 问题生成
根据搜集到的热门搜索词,研究团队使用搜索引擎获取相关的新闻内容,并对切分出来的内容进行分析。为确保问答质量,研究人员利用GPT生成问答对,确保数据的广泛性和有效性。
4.1.3 图像分配
图像分配环节同样重要,研究人员通过图片搜索引擎获取查询中提到的实体对应的图片。比如,如果搜索 query 涉及“巴黎”,系统会自动提取与“巴黎”相关的图片,并将实体单词替换为其上分位词,从而综合成一个完整的视觉问答样本。
4.1.4 伪标注生成
为提高网页过滤器和内容过滤器的准确性,研究团队根据两个原则对网页进行打分:一是如果样本源自网页/片段,其分数为1.0;若非源自,则通过五个开源模型进行答案验证,根据模型的正确率进行评分。这种方法确保训练样本的质量,进而构建80万样本的数据集。
4.1.5 人为验证
人为验证在测试集的构建中具有重要作用,研究者通过对视觉问答样本进行人为筛选,确保测试样本的准确性。同时,为避免训练和测试数据相似,团队在样本构建时使用不同时间区间的谷歌每日搜索趋势,确保样本的时效性与有效性。这一环节为UDK-VQA的高效性提供了有力保障。
五、实验与结果
在UDK-VQA上进行的实验验证了SearchLVLMs的有效性。研究者们使用了超过15个开源和闭源模型,包括GPT-4o、Gemini 1.5 Pro、InternVL-1.5等,评估数据集上回答的准确率。
5.1 性能评估与结果对比
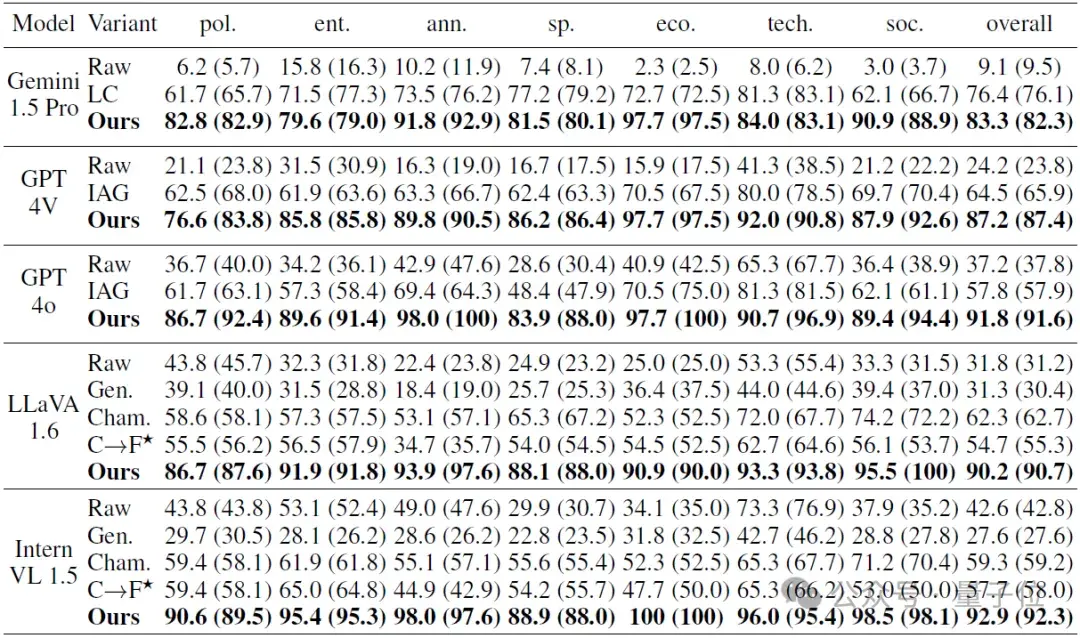
使用SearchLVLMs的模型在准确率上对比未启用检索增强的模型,提升幅度超过35%。例如,在实验中,InternVL-1.5模型在结合SearchLVLMs后,其准确率提升至92.9%,相较于未整合的GPT-4o(仅为57.8%)相差甚远。
通过在长上下文输入的情况下,模型也显示出较优的性能。然而,需要注意的是,长上下文同时会引入额外的计算耗时,这一问题在实际应用中需评估平衡。系统的分层过滤有效避免了反复出现的信息,减少了模型在处理信息时的负担。
六、未来潜力与前景
SearchLVLMs框架所展现的潜力是巨大的。这一框架不仅整合了多模态大模型,更为企业在信息处理和实时反馈方面赋能。随着技术的发展,未来可以结合更多的应用场景,比如在金融市场的快速响应分析、医疗信息的即时处理等领域通过更智能的算法实现高效的数据驱动决策。
在这个日益动态的环境中,SearchLVLMs不仅是技术的进步,更是对信息处理理念的全新诠释。它预示着未来人工智能的广泛应用,无论您是科研人员、企业决策者还是技术开发者,这一框架都将为您开启新的视野。
欢迎大家在下方留言讨论,分享您的看法!