
卷积神经网络的秘密:如何利用CNN构建高效的视觉智能!
卷积神经网络的秘密:如何利用CNN构建高效的视觉智能!
亲爱的读者朋友们,今天我们要深入探讨一个在现代人工智能和深度学习领域中极为重要的主题——卷积神经网络(CNN)!无论是在图像识别、目标检测,还是语音识别,CNN都扮演着关键角色。接下来,我们将一一拆解CNN的组成部分、工作流程,以及它在各个领域的实际应用,帮助大家更全面地了解这一强大工具。
一、卷积神经网络概述
卷积神经网络(CNN)是一种深度学习模型,它特别适用于处理具有网格结构的数据,例如图像和音频。作为深度学习的一个分支,CNN通过模拟人脑视觉皮层的运作机制,以层叠的方式提取和理解数据的特征。这种方法使得CNN在许多计算机视觉任务中如鱼得水。
CNN的发展迅猛,从最早的LeNet到如今的ResNet、EfficientNet,各种变种层出不穷。这些模型在图像分类、目标检测、语义分割等任务中取得了令人瞩目的成绩。例如,2015年的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)上,ResNet以3.57%的错误率打破了记录,令世界瞩目。
二、卷积神经网络的主要组成
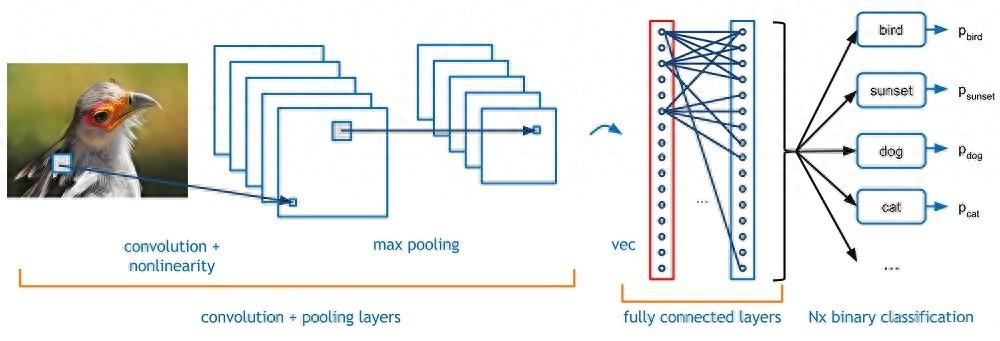
1. 卷积层(Convolution Layer)
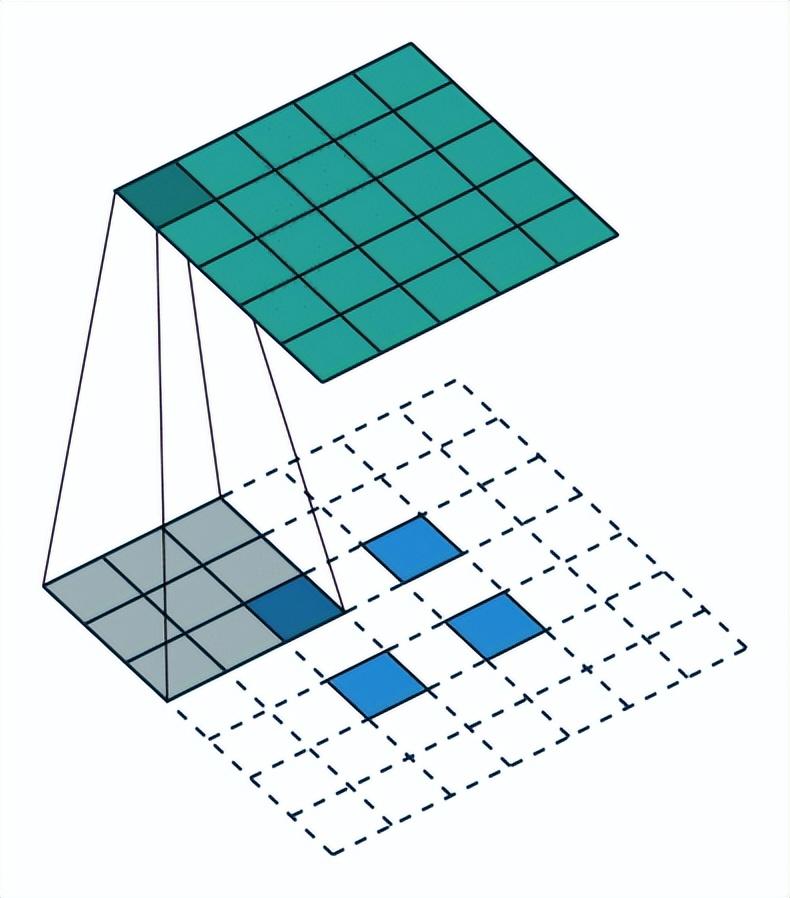
卷积层是CNN的核心组件,其主要功能是提取输入数据的特征。卷积操作是通过卷积核(或称滤波器)在输入数据上滑动实现的。假设我们有一个大小为\(5 \times 5\)的卷积核,对应于一个\(28 \times 28\)的图像,卷积操作会将卷积核中心对齐到图像的每个像素,并进行逐元素相乘后求和。
卷积核的设计使得它能够专注于特定的特征。例如,某些卷积核可能专门寻找图像的边缘,有的则可能识别纹理。研究表明,深层的卷积网络能自动学习越来越复杂的特征,进而提升模型的识别精度。
在处理彩色图像时,卷积核的通道数也与输入图像的通道数匹配,通常为三(RGB)。这样,卷积操作在每个通道上独立进行,然后将每个通道的结果相加以生成卷积输出。
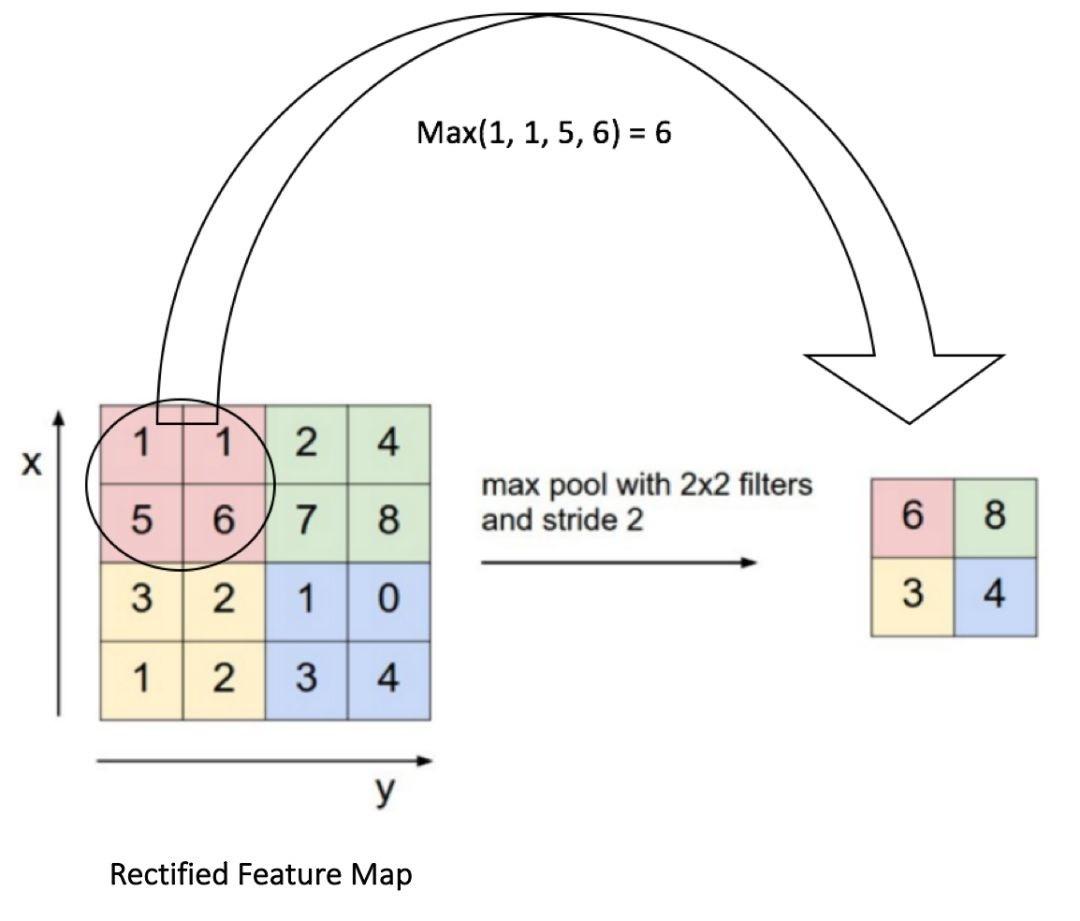
2. 池化层(Pooling Layer)
池化层的功能主要在于降低数据的维度,同时保留重要信息,以提高计算效率和减少过拟合。最常见的池化方式是最大池化(Max-Pooling)和平均池化(Average-Pooling)。在最大池化操作中,假设池化窗口大小为\(2 \times 2\),它会在输入数据的每个区域内选择最大值作为输出,从而减少数据量。
池化操作不仅能帮助我们减少计算负担,还能提高模型的鲁棒性。由于池化层在抽取特征时只能得到局部区域的最高或平均特征,它对输入数据的小幅度变化,如平移或旋转,体现出很好的不敏感性。这意味着模型对图像的微小变化具有一定的免疫力,使得实际应用更加安全可靠。
3. 全连接层(Fully-Connected Layer)
全连接层连接方式非常直接,网络中的每个神经元与前一层的所有神经元相连。在经过卷积层和池化层提取特征后,数据会被展平为一维向量,并输入到全连接层。在这个过程中,神经元会结合前面提取的特征,进行加权和偏置运算,得出最终的输出。
全连接层主要用于分类或回归任务。例如,在图像分类任务中,全连接层会生成一个向量,每个值对应于不同类别的概率。深度学习中的交叉熵损失函数常被用以测量模型预测与真实值之间的差距,从而不断优化模型。
三、卷积神经网络的工作流程
在实际应用中,以图像分类为例,卷积神经网络的工作流程可以分为几个步骤:
1. 数据输入:首先,将图像数据输入到卷积层。图像经过预处理后,被转换成适合CNN处理的格式。
2. 特征提取:卷积层开始工作,从输入图像中提取多层次的特征。最初,模型可能只关注简单的边缘和角点,而随着层的加深,模型会逐步理解复杂的形状和模式。
3. 数据压缩:池化层紧随其后,对提取的特征图进行压缩,降低维度,增强计算效率。
4. 特征展平:经过多层卷积和池化后,数据被展平为一维向量,准备进入全连接层进行处理。
5. 分类输出:全连接层将特征进行综合,输出各类别的概率分布,最终实现对图像的分类。
这种分层的处理流程不仅加速了计算速度,也使得最终结果更具准确性。在真实案例中,如Google的Inception模型,通过这种方法将图像分类的准确率提升至惊人的94%以上。
四、卷积神经网络的优点
1. 参数共享(Parameter Sharing)
参数共享是卷积神经网络的一大优点。由于卷积核会在整个图像上滑动,相同的卷积核参数被用于提取不同位置的特征,这种机制大大减少了模型的参数数量。例如,这样的机制使得卷积层的参数数量仅需数千,而全连接层往往需要数百万的参数。这不仅显著降低了存储空间的需求,同时也提高了网络的训练速度。
LeNet-5模型在其卷积层中仅使用了约60,000个参数,相比用于处理同样图像大小的全连接网络,节省了大量计算资源,允许更快的训练与更好的泛化能力。
2. 平移不变性(Translation Invariance)
卷积神经网络对输入图像的小幅度平移具有一定的不变性,意味着模型在图像发生小范围移动时,仍能有效识别图像中的同一特征。这是因为卷积核在图像的不同位置提取相似类型的特征,使得即便物**置略有变化,卷积网络也能保持良好的性能。
这种特性引领了多种实际应用,包括图像搜索和视频分析等复杂场景。研究显示,利用平移不变性,CNN模型在处理诸如人脸识别、自动驾驶等任务时,表现出了极高的准确率。
五、卷积神经网络的应用场景
1. 图像识别(Image Recognition)
卷积神经网络在图像识别领域的成功显而易见。比如,AlexNet、VGGNet和ResNet等模型在大规模数据集上的表现卓越,尤其是在ILSVRC竞赛中,获得了惊人的成绩。AlexNet的设计包含8层,其中5层是卷积层,使得它在2012年的竞赛中取得了53.6%的Top-5错误率,令世界震惊!
图像识别的应用场景贯穿了各个行业,如医疗影像分析、智能监控、社交媒体图片分析等领域。例如,通过训练,CNN能够在医疗影像中准确识别癌变图像,并辅助医生做出更科学的诊断。
2. 目标检测(Object Detection)
目标检测不仅是识别图像中的物体类别,还涉及到确定物体的具**置。比如,在智能安防系统中,通过图像识别可以高效监测可疑人物或物体。实现这一目标的模型包括Faster R-CNN和YOLO(You Only Look Once),它们使用卷积神经网络对整个图像进行处理,以同时预测目标的类别和位置。
YOLO模型从一张输入图像中生成多个边界框和类别概率,处理速度可以达到60帧每秒,广泛应用于安防监控、无人驾驶和机器人视觉等领域。
3. 语义分割(Semantic Segmentation)
语义分割是对图像中的每个像素进行分类的任务,用于更细粒度的信息提取。在自动驾驶领域,将汽车前方的场景分割为道路、行人、车辆、建筑物等不同类别,对于实现安全行驶至关重要。UNet是一个高效的卷积神经网络架构,在医疗影像分割任务中表现突出,通过对输入图像逐步进行编码和解码,实现像素级的精准分类。
这类应用潜力巨大,如城市规划、环境监测及航拍图像分析等,都能显著受益于语义分割提供的丰富数据。
欢迎大家在下方留言讨论,分享您的看法!无论是对卷积神经网络的运行机制,还是其实际应用,任何问题或经验都期待听到您的声音!