
让你的AI更聪明:深入解析Transformer模型中的注意力机制!
让你的AI更聪明:深入解析Transformer模型中的注意力机制!
亲爱的读者朋友们,今天我们要一起走进深度学习的世界,特别是聚焦在Transformer模型中的注意力机制,这是现代语言模型如GPT和Llama的核心所在。希望通过本篇文章,能为你解锁这一强大工具的神秘面纱,提供丰富的知识和实用的操作步骤。
一、自注意力机制
1. 理论基础
自注意力机制的崛起可追溯至2017年发表的《Attention Is All You Need》论文。该论文提出了一种全新的架构,使得模型不再依赖递归神经网络(RNN),而是通过自注意力机制对输入序列进行处理。这一机制的关键在于它允许模型在处理每一个元素时,动态地关注整个输入序列的上下文,从而更好地理解词语之间的关系。
在处理自然语言时,往往上下文对于词义的判断至关重要。例如,“银行”一词可以指代金融机构,也可以指代河岸。自注意力机制通过分配权重,帮助模型聚焦在相关的词汇上,从而提高理解深度与准确性。
2. 操作过程
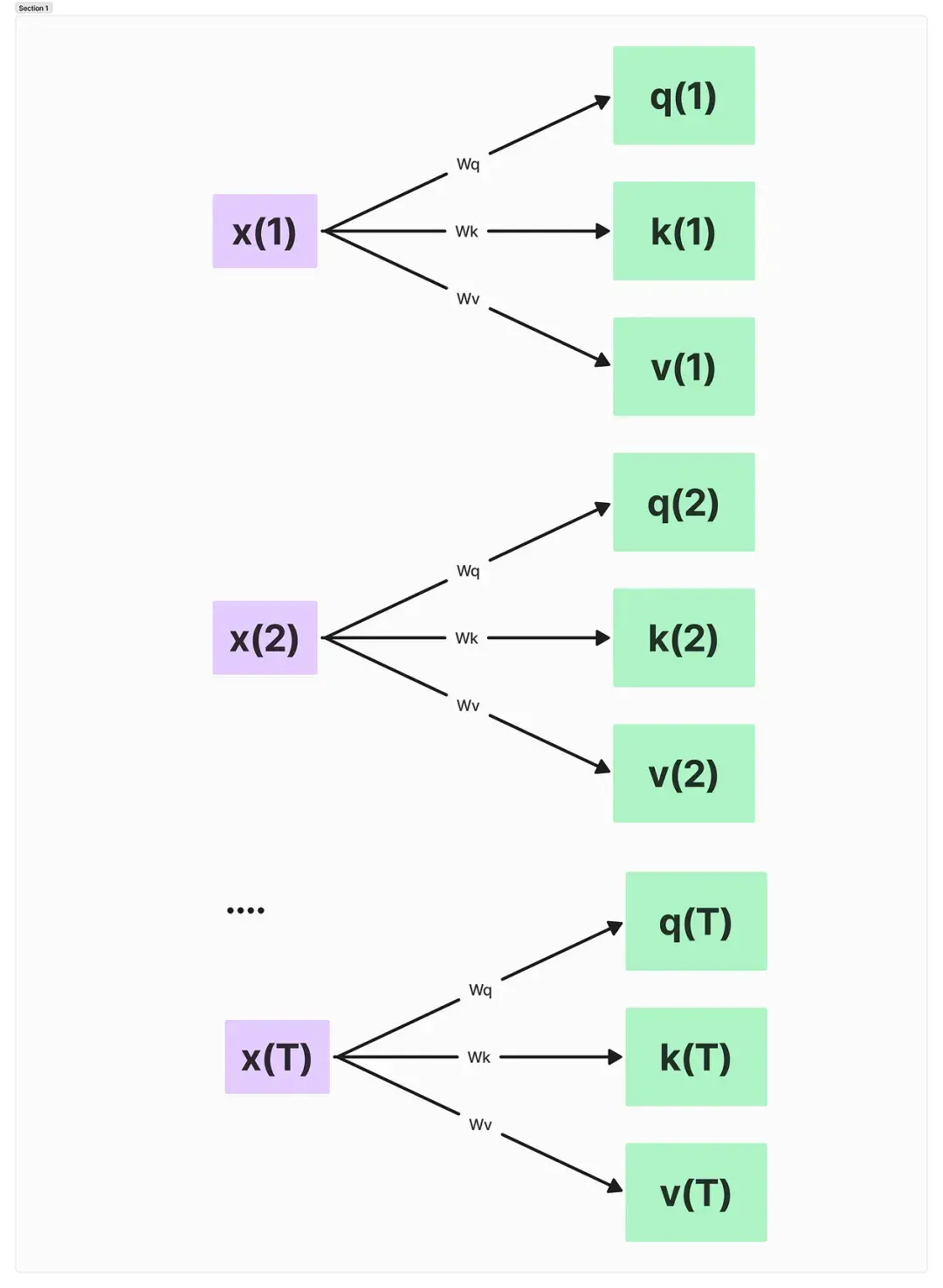
自注意力机制的核心是创建输入的嵌入向量。例如,在句子“The sun rises in the east”中,我们将每个单词转换为向量表示。接下来,我们通过权重矩阵将输入转化为查询(query)、键(key)和值(value)向量。计算非归一化注意力权重是一个重要步骤,通过查询与每个键的点积,得到各个单词之间的兼容性度量。
当我们将权重进行归一化处理后,生成的注意力权重可用于计算上下文向量,以此获得一个“上下文感知”的输入表示。这个上下文向量不仅包含当前单词的信息,还融入了与其相关的其他单词信息,从而实现更深层次的理解。
3. PyTorch实现
在PyTorch中,实现自注意力机制的过程相对简单。我建议从创建一个`SelfAttention`类开始,类中包含权重矩阵的初始化和前向传播(forward)逻辑。这里是一个简化的代码示例:
```python
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads

self.head_dim = embed_size // heads
assert (
self.head_dim heads == embed_size
), "Embedding size must be divisible by heads"
self.values = nn.Linear(embed_size, embed_size, bias=False)
self.keys = nn.Linear(embed_size, embed_size, bias=False)
self.queries = nn.Linear(embed_size, embed_size, bias=False)
self.fc_out = nn.Linear(embed_size, embed_size)

def forward(self, x):
N = x.shape[0]
seq_length = x.shape[1]
Split embedding into heads
values = self.values(x).view(N, seq_length, self.heads, self.head_dim)
keys = self.keys(x).view(N, seq_length, self.heads, self.head_dim)
queries = self.queries(x).view(N, seq_length, self.heads, self.head_dim)
Implement attention scoring logic here...
return x Placeholder for actual output
Sample input
x = torch.rand(10, 5, 256) (batch_size, seq_len, embed_size)
attention = SelfAttention(256, 8)
output = attention(x)
```
在这个过程中,值得注意的是,权重矩阵的初始化是模型学习的关键,它们的准确性将直接影响模型的性能。
二、多头注意力机制
1. 概念介绍
多头注意力机制被引入以增强自注意力机制的表现力。不同的注意力头可以聚焦于输入序列中的不同部分,捕捉信息的不同子空间。比如一个头可能专注于句子中的主语,另一个则可能关注动词及其后续内容,这种多样性使得模型在理解上更为细致。
通过并行化多个头的处理,模型能够在相同的计算资源下提取更多的信息。同时,多个头为不同类型的信息提取提供了灵活性和独立性。实际上,知名模型Llama 2就使用多达32个注意力头,提升其对复杂关系的捕捉能力。
2. 实现细节
在实现多头注意力时,可以将多个自注意力层的输出进行拼接和线性变换,从而得到最终的输出。这样的处理不仅提升了模型的学习能力,同时也有效避免了因为单个头过拟合的问题。
以下是多头注意力的简单实现逻辑:
```python
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.heads = heads
self.head_dim = embed_size // heads
self.values = nn.Linear(embed_size, embed_size, bias=False)
self.keys = nn.Linear(embed_size, embed_size, bias=False)
self.queries = nn.Linear(embed_size, embed_size, bias=False)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, x):
N = x.shape[0]
seq_length = x.shape[1]
values = self.values(x).view(N, seq_length, self.heads, self.head_dim)
keys = self.keys(x).view(N, seq_length, self.heads, self.head_dim)
queries = self.queries(x).view(N, seq_length, self.heads, self.head_dim)
Spliting heads and performing scaled dot product attention...
output = self.fc_out(x) Linear projection of concatenated heads
return output
```
在多头注意力的实现过程中,注意合理划分和管理各个头的输出;每个头应当有相对独立的参数,以确保学习过程的有效性和灵活性。
3. PyTorch实现
通过定义一个`MultiHeadAttention`类,我们可以封装上述逻辑并进行训练。这样的设计使得我们在后期使用时可以方便地调用,同时也极大地提升了代码的整洁度和可维护性。
三、交叉注意力机制
1. 定义与特点
交叉注意力是一种强大的变体,允许模型在处理两个不同的输入序列时,将一个序列的信息引导给另一个序列。这种机制在理解语言翻译、图像描述生成等大型AI任务时尤其重要。例如,在机器翻译中,模型在生成目标语言句子时需要合理整合源语言的信息;在图像生成任务中,生成的每个词都需要关注相应图像的部分。
交叉注意力的运用不仅限于语言模型,更在多模态应用中展现出巨大的潜力。例如,Stable Diffusion模型利用这一机制将文本提示与图像特征关联,实现文本驱动的图像生成。
2. 实现过程
在交叉注意力的实现中,查询(query)来自一个输入序列,而键(key)和值(value)则来自另一个输入序列。这种设计理念使得模型能够有效地整合来自不同来源的信息,从而在进行复杂任务时表现得更为出色。
以下是交叉注意力的主要实现步骤:
```python
class CrossAttention(nn.Module):
def __init__(self, embed_size):
super(CrossAttention, self).__init__()
self.values = nn.Linear(embed_size, embed_size)
self.keys = nn.Linear(embed_size, embed_size)
self.queries = nn.Linear(embed_size, embed_size)
def forward(self, x1, x2):
values = self.values(x2)
keys = self.keys(x2)
queries = self.queries(x1)
Scaled dot-product attention calculation...
return context_vector
```
这种设计保证了灵活性,允许交叉注意力处理不同长度的输入序列,为模型提供了更大的自由度。用户应注意的是,保持两个序列的一致维度是实施交叉注意力的前提。
3. PyTorch实现

通过实现一个`CrossAttention`类,开发者可以实现高效的多模态信息处理。以下是交叉注意力模块的使用示例:
```python
cross_attention = CrossAttention(256)
context = cross_attention(input_sequence1, input_sequence2)
```
确保在模型架构中合理地使用交叉注意力,有助于实现深度学习模型多模态的信息联结。

四、因果自注意力机制
1. 机制解析
因果自注意力机制专门为解码器风格的大型语言模型设计,能够确保在生成文本时,模型仅依赖当前和之前的词,而不考虑未来的词。这一特点显著增强了文本生成的连贯性,确保了生成的内容具备良好的上下文关联性。
在句子“The cat sits on the mat”中,当处理“sits”时,只能访问“the”和“cat”这两个词的信息,而不能暴露未来的词“on”、“the”和“mat”。这种策略使得生成的文本更加合理。

2. 过程详解
要实现因果自注意力,我们需要在注意力权重中应用掩码。掩码的作用是将未来的token“屏蔽”,确保模型在预测时不会使用到未见的信息。整个过程包括对输入序列进行感知、计算各个token之间的注意力评分,并在后续的处理过程中应用掩码。
实现代码如下:
```python
class CausalSelfAttention(nn.Module):
def __init__(self, embed_size):
super(CausalSelfAttention, self).__init__()
self.values = nn.Linear(embed_size, embed_size)
self.keys = nn.Linear(embed_size, embed_size)
self.queries = nn.Linear(embed_size, embed_size)
def forward(self, x):
Shape: (batch_size, seq_length, embed_size)
attention = self.calculate_attention(x)
return attention
def calculate_attention(self, x):
Attention score masking and calculation logic...
return masked_attention_scores
```
要注意的是,掩码的实现可以通过在注意力权重矩阵中的未来位置上赋予一个小的负值(如-∞),在应用softmax时,后续的关注度将完全被消除。
3. PyTorch实现
在PyTorch中实现因果自注意力机制,用户可以创建一个`CausalSelfAttention`类,方便高效地进行文本生成。在生成每个token时,通过更新模型状态并进行限制,在保证上下文一致性的基础上,积极引导生成顺序。
最后
通过对自注意力、多头注意力、交叉注意力及因果自注意力的深入分析与实现解析,希望能为您的机器学习旅程提供有力的助推。如您在使用这些机制时遇到任何问题,欢迎大家在下方留言讨论,分享您的看法!
