
微软大模型助力,智能系统更懂你!提升满意度!
微软引领潮流:大语言模型重塑用户满意度评估
在人工智能(AI)日新月异的今天,对话系统已经成为我们生活中不可或缺的一部分。从智能助手到聊天机器人,再到语音助手,这些系统正在逐渐改变我们与技术的互动方式。如何确保这些系统能够真正理解我们的需求,并在适当的时候提供满意的回答,一直是技术界关注的焦点。微软的研究人员近期在《Interpretable User Satisfaction Estimation for Conversational Systems with Large Language Models》一文中提出了一种全新的方法,通过大语言模型(LLMs)分析用户满意度,让智能系统更加善解人意。
一、传统方法的局限性
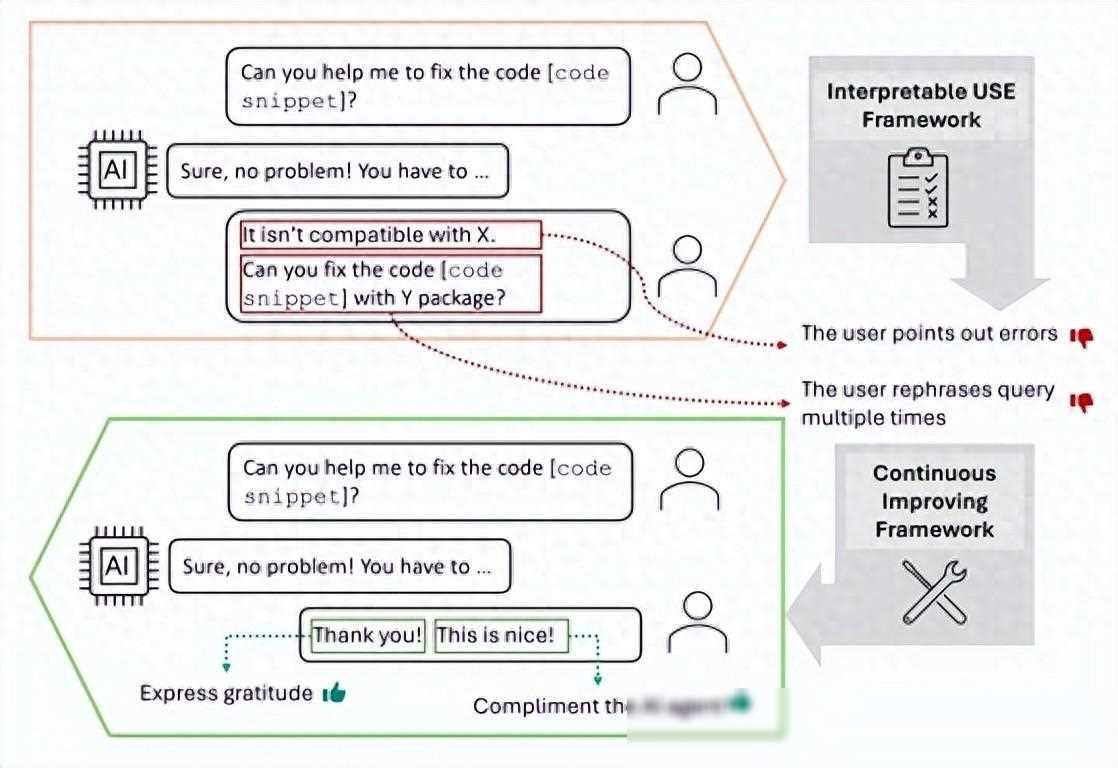
在过去,对话系统的用户满意度评估主要依赖于基于特征化机器学习模型或文本嵌入的方法。这些方法在提取模式和可解释性方面存在诸多限制。例如,基于表示学习的方法往往使用复杂的神经模型,这使得它们对于满意/不满意的对话模式洞察较少,且相对不透明。这些模型难以泛化到不同领域的对话系统中,因为它们往往依赖于特定领域的特征和规则。
二、大语言模型的崛起
随着大语言模型的兴起,我们有机会打破这一僵局。大语言模型,如GPT-4,拥有强大的自然语言理解和推理能力,能够从用户的自然语言中提取出丰富的信息。这种能力使得大语言模型在对话系统的用户满意度评估方面具有巨大的潜力。微软的研究人员正是看中了这一点,他们提出了一种名为SPUR(监督提示用户满意度量表)的新方法,利用大语言模型来提高用户满意度估计的准确性和可解释性。
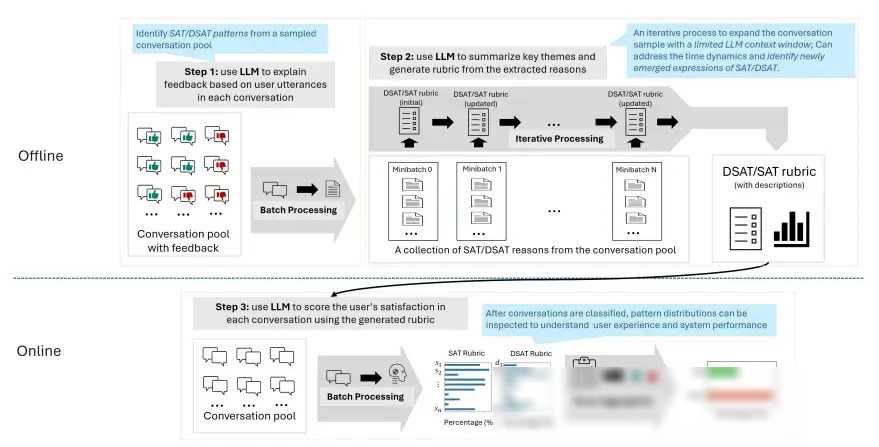
三、SPUR方法的奥秘
SPUR方法主要由三个步骤组成:监督式提取、规则总结和用户满意度评估。
监督式提取:在这一阶段,研究人员使用GPT-4等大语言模型从标记的训练集中提取用户满意度的信号。他们通过设计巧妙的提示,让模型从对话中识别出用户满意或不满意的表达,并将其归纳为最多三个理由。这些理由不仅具有代表性,而且能够揭示用户对话背后的真实意图。
规则总结:在提取出满意/不满意的模式后,研究人员需要进一步压缩这些模式,并识别出训练集中频繁出现的满意/不满意模式。这一过程需要一定的专业知识和经验,因为研究人员需要确保总结出的规则既具有普适性,又能够准确地反映用户的满意度。通过这一过程,研究人员建立了一个清晰的基于提取模式的USE评估标准。
用户满意度评估:在得到USE评估标准后,研究人员将生成的规则作为指令集成到GPT-4等模型中,用于评分用户满意度。对于每个规则项,模型都会做出二元决策,判断给定对话是否展示了所描述的行为。如果答案是“是”,则模型会进一步评估该行为对用户整体满意/不满意的影响,并给出一个1-10的评分。所有规则项的得分将被聚合为一个代表给定对话中用户整体满意度的SAT得分。
四、SPUR方法的优势
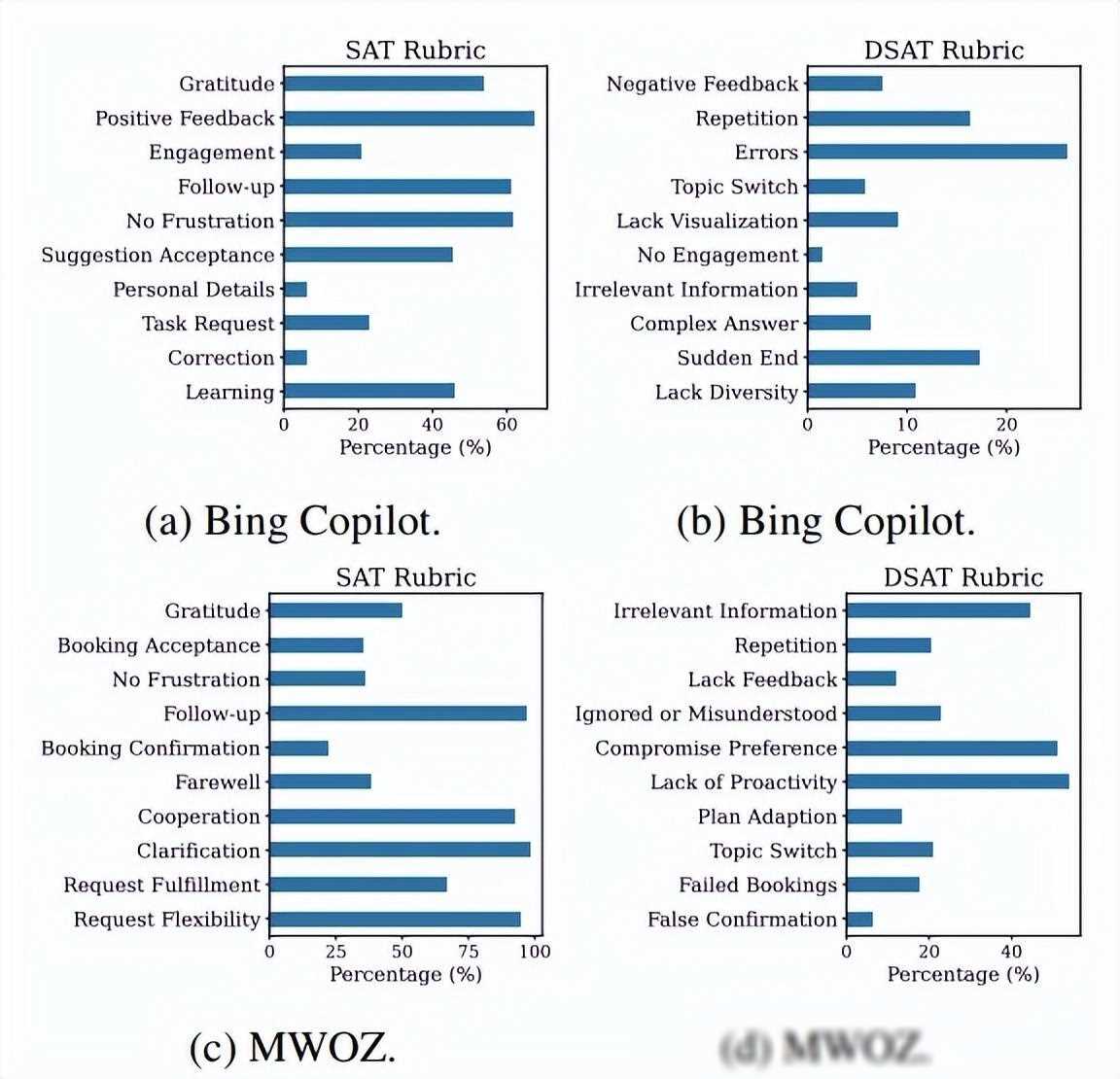
与传统的基于特征化机器学习模型或文本嵌入的方法相比,SPUR方法具有以下几个显著的优势:
更高的准确性:由于大语言模型具有强大的自然语言理解和推理能力,因此SPUR方法能够更准确地从用户的自然语言中提取出满意度的信号。
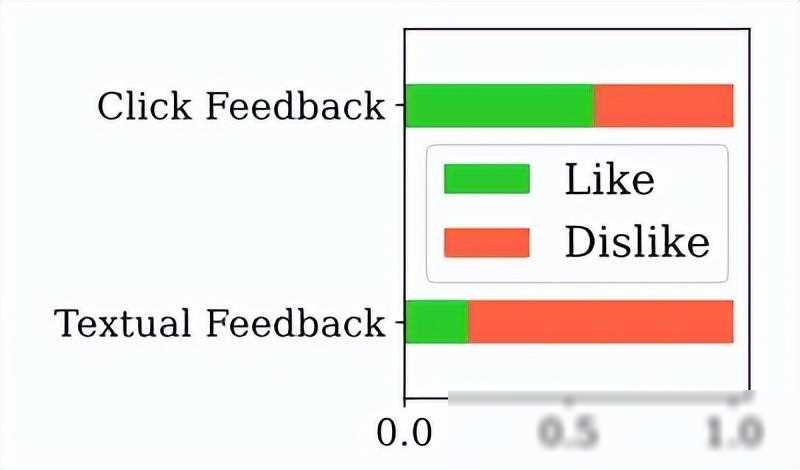
更强的可解释性:通过监督式提取和规则总结的过程,SPUR方法能够建立清晰的USE评估标准,这使得模型在评估用户满意度时更具解释性。
更好的泛化能力:SPUR方法不依赖于特定领域的特征和规则,因此它可以轻松地泛化到不同领域的对话系统中。

五、实际应用与未来展望
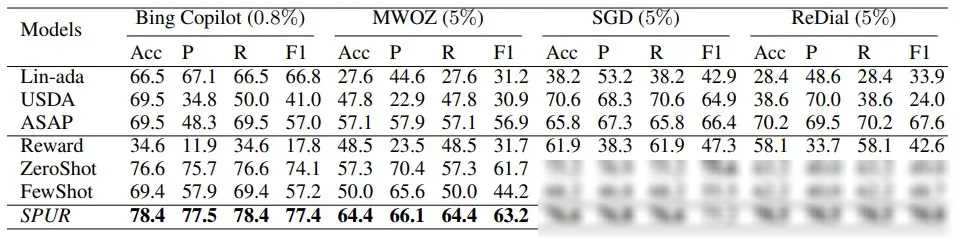
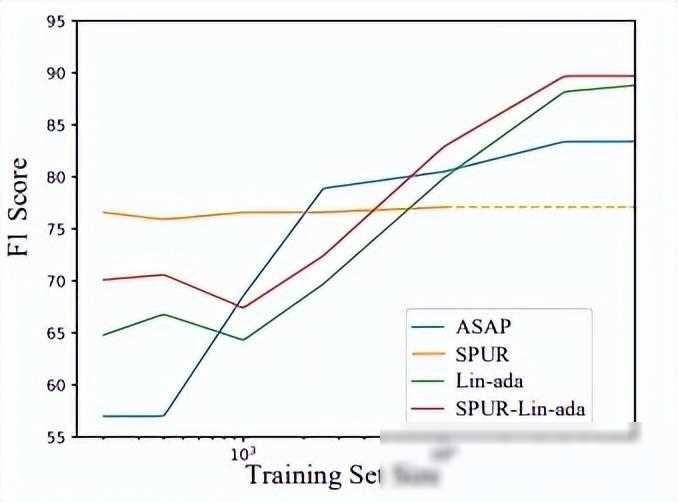
微软的研究人员已经在多个数据集上验证了SPUR方法的有效性。无论是通用型的对话系统(如gpt和Bing Copilot),还是任务导向型的对话系统(如客服聊天机器人),SPUR方法都能够显著提高用户满意度估计的准确性和可解释性。
展望未来,随着大语言模型技术的不断发展,我们有理由相信用户满意度评估将迎来更多的创新和突破。例如,我们可以将SPUR方法与其他先进技术相结合,如情感分析、意图识别等,以进一步提高对话系统的智能水平和用户体验。我们也需要关注如何平衡用户隐私与数据利用之间的关系,确保在为用户提供更优质服务的保护他们的合法权益。
总之,微软的研究人员通过大语言模型技术为用户满意度评估带来了全新的解决方案。SPUR方法不仅提高了评估的准确性和可解释性,还为对话系统的持续改进提供了有力支持。随着技术的不断进步和应用场景的不断拓展,我们有理由相信用户满意度评估将在未来发挥更加重要的作用。