
人脸识别技术大揭秘:提升准确度的Transformer方法,你知道吗?
人脸识别技术大揭秘:提升准确度的Transformer方法,你知道吗?
亲爱的读者朋友们,本文将带你进入一个令人兴奋的技术世界,探索人脸识别技术如何通过Transformer框架实现机遇性的突破!近年来,随着图像识别和计算机视觉领域的迅速发展,人脸识别技术的应用开始深入到我们生活的方方面面。然而,尽管技术已经取得了显著进步,很多人仍然对其背后的原理和未来的发展方向感到困惑与好奇。本篇文章将深入浅出地纠正这些困惑,与大家一起解锁人脸识别的奥秘。
一、引言
1. 1.1 背景概述
在人脸识别技术飞速发展的时代,技术的应用范围已经遍及无人超市、智能门锁、金融支付、公共安全等多个领域。市场研究数据显示,预计2024年人脸识别市场规模将达到约78亿美元,这一数字无疑显示了技术的重要性和价值。
面临的数据隐私和伦理问题依然挑战着技术的可持续发展。技术的精准度与应用成本是人们关注的两个主要问题。为了提高人脸识别的准确性并降低成本,新的技术框架呼之欲出,这就是我们今天要讲述的——Transformer技术。
二、技术回顾——Transformer
1. 2.1 卷积神经网络(CNN)局限性分析
卷积神经网络(CNN)自诞生以来,主导了计算机视觉的许多领域。然而,其设计上的局限性也逐渐显现。主要表现在其<控制性偏见>方面, 尤其是在数据量较大时,这种偏见可能导致模型表达能力的下降。
CNN采用卷积核设计来专注于局部特征,但在处理复杂的图像时,局部特征并不能涵盖所有信息。许多研究表明,在大规模数据集中,CNN逐渐暴露出以下问题:
- 对于长距离依赖的信息建模能力不足;
- 计算资源消耗在训练和推导中居高不下,尤其是在处理高清长视频数据时。
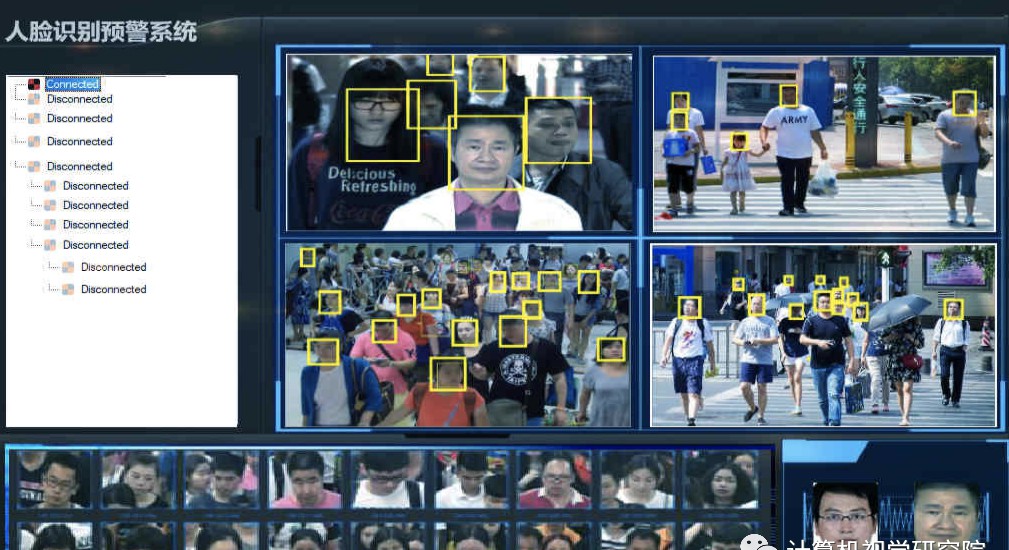
而这些正是
2. 2.2 Transformer的优势
Transformer模型引入了自注意力机制,能够在特征提取过程中<直接衡量所有时空位置之间的关系>。这一特性使得Transformer在处理长距离依赖和全局特征时,表现得尤为出色。此外,研究表明,Transformer的训练速度比CNN更快,这一优势为科研人员在进行人脸识别时开辟了新的可能。
Google在其研究中发现,Transformer模型在处理静态图像任务时,训练所需的时间和计算资源比CNN降低了约50%。这意味着研究人员可以用相同的资源去训练更强大的模型,实现更高的准确度和性能。
3. 2.3 Transformer在计算机视觉中的应用探索
对Transformer在计算机视觉方面的研究初露端倪,许多研究者开始将目光放在其应用于人脸识别上。研究发现Transformer在此领域的潜力相当巨大。例如,Facebook AI团队通过对Transformer进行修改与优化,使其能够处理复杂的人脸图像数据,并在公开基础数据集上展现出远超传统CNN的性能。
最近的研究指出,Transformer有可能成为处理人脸识别的新标准,特别是在面对诸如遮挡、光照变化等挑战时。无论是在大规模数据库中的训练表现,还是在实际应用中的有效性,Transformer模型都显示出极为显著的优势。
三、FACE TRANSFORMER
1. 3.1 网络框架设计
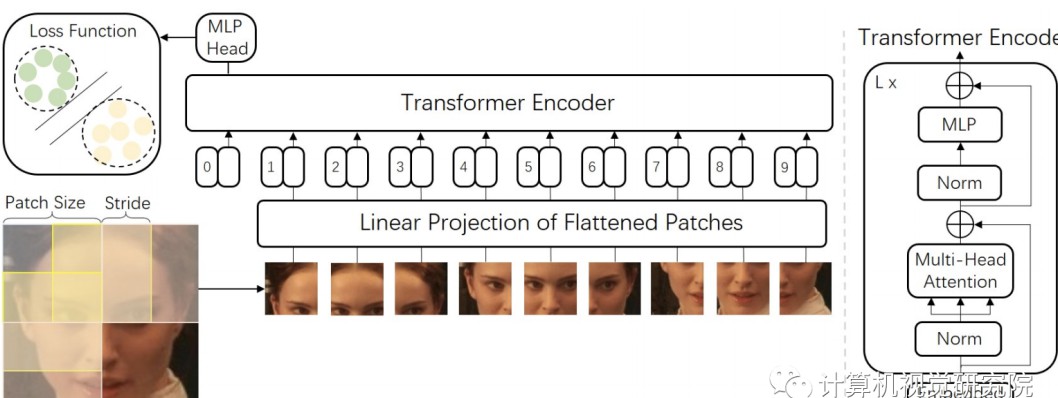
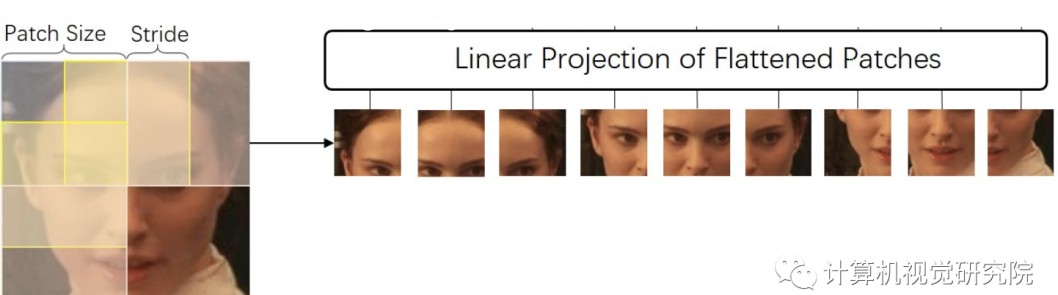
在FACE TRANSFORMER 模型中,研究者在ViT(Vision Transformer)基础上构建了新的网络框架,旨在更好地捕捉人脸特征。具体来说,通过采用滑动块方法,该模型对图像的划分方式进行了改进,这种设计不仅能够更有效地嵌入局部与全局信息,还能够显著提高模型的准确性和鲁棒性。
在实际操作中,原始图像会被划分为重叠的块,这样能够更好地捕捉块与块之间的关系和信息。例如,如果一张图像的分辨率为(512, 512),那么通过设置块的大小为(16, 16)并采用步幅(8),可以生成多个重叠的图像块,每个块都会被转化为一个特征向量。这种方法有效地扩展了模型的视野,使其能够从更多维度理解和处理人脸特征。
2. 3.2 损失函数的设定
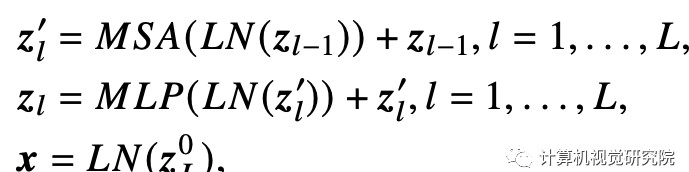
对于人脸识别任务而言,损失函数的选择具有举足轻重的影响力。FACE TRANSFORMER采用了基于Softmax的损失函数,结合了大边距(large margin)技术,目的是在模型训练中充分降低误识别率和提高识别精度。
大边距技术旨在扩大类别之间的距离,从而使得相似样本之间的距离尽可能远。具体来说,模型将识别过程转化为高维空间中的角度比较。通过最大化相同类别样本之间的角度相似性,同时最小化不同类别样本之间的角度相似性,模型最终能够形成更加清晰的特征边界。
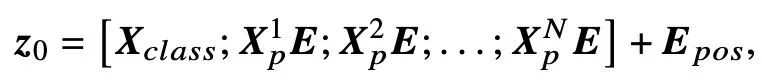
为了解决特定的挑战,训练时可以引入对抗性样本,通过调整损失函数,使得模型在数据多样性变化中依旧保持稳定性。研究发现,这样的优化训练方法能够让FACE TRANSFORMER在多个竞赛基准上取得与传统CNN相媲美的效果。
四、实验及可视化
1. 4.1 模型参数及设置
在进行FACE TRANSFORMER的实验时,模型的参数设定是一个至关重要的环节。通常,研究人员采用以下设置:
- 模型层数:通常为20层;
- 头数(attention heads):设定为8;
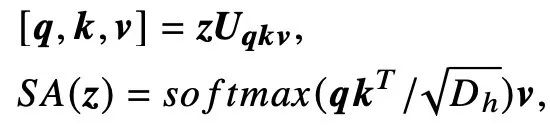
- 隐藏层大小:512;
- MLP(多层感知器)大小:2048。
不同模型的具体参数可以通过不断的实验调优,使性能进一步优化。
2. 4.2 Transformer模型的注意力机制分析
为了深入分析Transformer模型的人脸关注区域,研究者采用了Attention Rollout技术。该技术揭示了Transformer在处理图像时,如何有效地关注于人脸区域而忽略不相关的背景。这一过程不仅提高了模型对关键特征的学习能力,还有效降低了对数据冗余的依赖。
研究者通过可视化注意矩阵,可以直观看到模型在不同层次及不同注意头的关注结果。例如,在处理有遮挡的人脸时,模型表现出对眼睛和鼻子区域的高度关注,而对背景的注意力有所降低。这样的策略显著提升了对复杂环境的适应能力。
五、结论
欢迎大家在下方留言讨论,分享您的看法!希望本文能够为你对人脸识别技术及Transformer方法的理解提供帮助,同时激发你在这一领域探索的热情。随着技术的不断发展,未来我们或许能在日常生活中看到更多基于此技术构建的创新应用与解决方案。