
你知道RAG系统能如何彻底改变你的AI应用吗?5天快速掌握的完整指南!
你知道RAG系统能如何彻底改变你的AI应用吗?5天快速掌握的完整指南!
亲爱的读者朋友们,今天我们将深入探讨一个变化迅猛且备受关注的话题:RAG系统(Retrieval Augmented Generation)的应用与实现。许多朋友在使用大语言模型(LLM)时,可能会遇到困扰,比如幻觉现象及知识过时。那么,如何利用RAG系统来提高我们的应用效果呢?这篇文章将帮助您在短短5天内掌握这一技能,步步深入。
一、RAG的定义与背景
RAG即Retrieval Augmented Generation,是一种将检索与生成结合的强大技术。在当前自然语言处理(NLP)领域,RAG以其独特的优势吸引了众多研究人员和技术人员的关注。大语言模型,如gpt,虽然表现优秀,但往往会产生所谓的“幻觉”,即生成的内容不够准确或过时。
为了解决这一问题,RAG引入了一种策略,通过检索机制引入外部知识,从而加强生成模型的准确性与丰富性。简单来说,RAG是让机器不仅会生成文字,还能“记得”更多的信息,确保它说的每句话都充满可能性和现实基础。
当你询问某个问题时,传统的LLM可能凭借内存和训练数据生成答案,但这些答案可能是片面的。而采用RAG后,它会同时检索最新的相关信息,再生成一个更加全面的回答,这一点对于需要及时更新知识的领域尤为重要。
二、RAG的基本框架
1. RAG的核心组成部分
- 检索(Retrieval):负责从大量外部知识库中快速找到与用户查询相关的信息。这是RAG的基础,它确保生成模型所依据的信息是最新且相关的。
- 增强(Augmented):通过把检索内容引入生成模型,提供更强的上下文,确保生成内容的连贯性和真实性。
- 生成(Generation):使用像GPT这样的语言模型,对检索到的信息进行加工,最终生成用户需要的内容。
2. RAG的工作流程
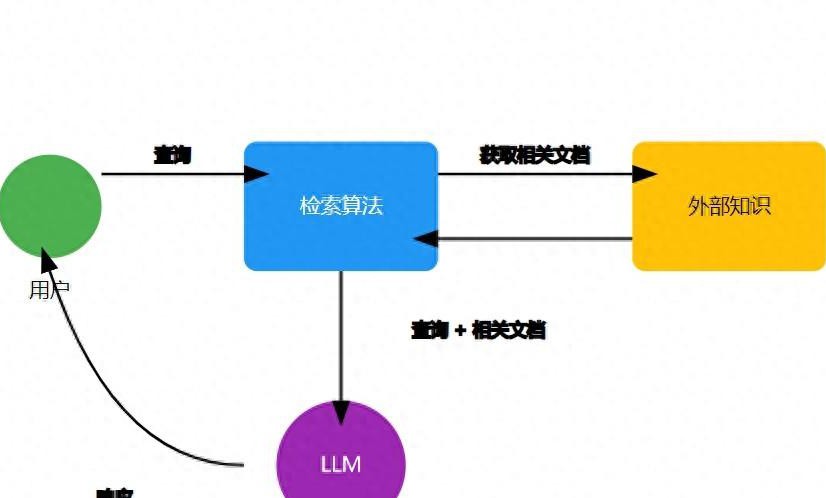
有关RAG的工作流程简而言之分为以下几个步骤:
- 用户提出问题或查询;
- 查询被传送至检索算法;
- 检索算法在外部知识库中寻找相关文档;
- 找到的文档与查询一起被发送给语言模型(LLM);
- LLM综合检索结果生成响应;
- 最终,响应反馈给用户。
3. RAG系统的优势
RAG的魅力在于它的结合能力。通过将检索与生成相结合,不仅提升了生成内容的准确性,也让用户体验更流畅。这种优势在法律、医学、科技等需要大量专业知识的领域表现得尤为明显。例如,在法律文书生成中,RAG能够检索实时的法律条文,确保生成的文章符合现行法律规定。
三、第一天:理解RAG的原理
在学习RAG的过程中,第一天的目的是要从高层次理解RAG的工作原理及其关键组成部分。
1. RAG的整体概述
从宏观来看,RAG在现代自然语言处理中的地位不可或缺。它的主要优势在于快速引入上下文信息,提升生成模型的性能,为各种应用场景提供支持。尤其是在用户输入问题时,能够实时从广泛的数据源中查找信息。
2. 核心组成部分的详细分析
- 检索方法:如DPR(Dense Passage Retrieval)和BM25等技术。DPR通过深度学习实现信息的匹配,而BM25则利用词频等传统方法快速选取相关文件,适用于初步的信息过滤。
- 生成模型:熟悉如GPT、BART和T5等预训练模型能够给我们在特定应用下的生成增强提供良好基础。
四、第二天:建立基础的检索系统
第二天的课程目标是让大家能够搭建一个基础的检索系统。
1. 深入检索模型的概念
不同的检索模型有各自的优势与劣势:
- 密集检索:如DPR和ColBERT,能够识别上下文的复杂性,但对计算资源要求高。
- 稀疏检索:如BM25和TF-IDF,处理速度快且易于实现,尤其适用初级用户。
2. 检索的实现技术
实施检索系统可以使用开源库,如elasticsearch和faiss。elasticsearch可以轻松进行文本搜索和分析,而faiss则可以进行高效的相似性搜索。实现基础检索时,用户只需简单配置这些工具即可启动检索。
3. 知识库的构建与应用
设计知识库时,应注意标签、结构和数据来源。准备数据时,需对语料库进行预处理,确保包含的内容切合实际应用,如去除冗余信息,标准化格式。
五、第三天:微调生成模型
进入第三天的学习,我们将聚焦在微调生成模型,并分析其在RAG中的作用。
1. 生成模型的深入研究
生成模型在深度学习中的重要性不言而喻,尤其是针对特定任务的微调过程能显著提升模型的精确度与适用性。
2. 实践操作:生成模型的应用
使用Hugging Face提供的transformers库,可以轻松微调T5或BART等模型。通过实际案例,您可以在小型数据集上进行实验,以便观察生成效果。
3. 检索与生成的互动探索
生成模型在引入检索数据后,尤为重要的是其接收方式与处理手段。能直观观察到,通过反馈机制,检索数据如何提升生成响应的精确度。
六、第四天:实现完整的RAG系统
第四天着重介绍如何将检索与生成系统结合,形成一个完整的RAG系统。
1. 结合检索与生成
最重要的一步是将检索和生成组件无缝衔接。在这一点上,实现检索输出与生成模型的实时数据交互至关重要。
2. 使用LlamaIndex构建RAG管道
LlamaIndex具备强大的文档处理与调度能力,学习其使用方法能让您在项目中如鱼得水。通过使用其文档,您可以实现高效的RAG模型。
3. 动手实验:参数调整与优化
尝试不同的参数组合对系统性能产生影响,例如调整检索文档数量、生成的束搜索策略等,能强化对模型理解和应用的认知。
七、第五天:高级模型的创建与评估
在最后一天,我们聚焦于创建一个更强大的RAG模型,并学习如何评估其性能。
1. 高级微调技巧
针对特定领域的任务进行优化,能大幅提升生成与检索组件的协同工作能力,从而改善模型整体表现。
2. 系统扩展
可通过引入大型知识库及更复杂的结构来扩展RAG系统,例如结合外部数据源,提升模型向外界的信息吸收能力。
3. 性能优化策略
了解GPU加速如何配合faiss,以提高检索速度和内存使用效率,确保系统运行流畅。
4. 模型评估技术

运用评价指标,如BLEU、ROUGE等,帮助您更好地理解模型在实际应用中的表现。这些指标可以有效反映生成内容的质量,确保在使用中可获得直接反馈。
欢迎大家在下方留言讨论,分享您的看法!希望这篇文章能帮助你更深刻地理解RAG系统,并在实际应用中获得成功。