
迁移学习结合异常检测:如何打破技术瓶颈?
迁移学习结合异常检测:如何打破技术瓶颈?
亲爱的读者朋友们,面对当今数据科学的快速发展,我们不禁要问:在我们这个信息爆炸的时代,如何高效地识别异常数据?答案就在于—结合迁移学习的异常检测技术。本文将深入探讨这个领域,提供高昂的专业见解与实用的解决方案。
一、传统异常检测的挑战
样本稀缺是异常检测中最常见的问题,它通常影响到模型的训练能力。当我们面对一个具有极少标记异常样本的情况时,机器学习模型就无法学习到有效的特征,进而导致检测准确性下降。例如,在银行的反欺诈系统中,若历史数据中只有极少的欺诈交易记录,模型便难以识别新的欺诈行为。
数据分布不均同样是一个无法忽视的难题,尤其是在处理多源数据时,可能出现的偏差会影响模型的有效性。比如,在处理不同国家地区的消费数据时,各地的消费习惯、支付平台普及率等都有所不同,若将这些数据一并训练,模型可能会对某些地区的样本过拟合,从而无法在其他地区有效应用。
为了解决上述挑战,迁移学习提供了一种可行的解决方案。通过利用已有领域的知识,迁移学习能够在新领域中提升模型的泛化能力,减少对大量标注数据的依赖。
二、基于迁移学习的异常检测方法概述
核心原理中,迁移学习依赖于预训练模型的使用,这些模型通过在大型数据集上的训练已经学会了抽取通用特征。比如,在图像识别领域,使用在ImageNet数据集上预训练的模型可以显著提升我们的任务表现。此外,迁移学习通过知识迁移的机制,可以实现对源领域知识的再利用,帮助新领域的模型更快收敛,从而提高了异常检测的性能。
在应用领域方面,迁移学习已经在许多行业得到了广泛应用。在金融风险控制中,模型可以从过去的数据中学习到异常模式,而在网络安全领域,可以通过模型迁移对新出现的攻击方式进行快速响应。工业生产与交通监控同样受益于此技术,通过实时数据监测,及时发现生产故障或交通异常,提高效率。
三、当前面临的问题与挑战
迁移学习与异常检测的融合并非一帆风顺。在知识差异的影响方面,源领域与目标领域的差异可能导致迁移学习的效果打折扣。例如,假设我们训练的模型是在电子商务领域,而现在要应用到医疗数据中,由于数据特征的根本不同,模型可能无法有效适应。
数据不平衡问题同样不容小觑。在许多应用场景中,异常样本的比例极低,这使得模型在训练时会出现极度偏向正常样本的情况。解决这一类问题的一个常用方法是采用重采样技术,或者合成新异常样本,从而在一定程度上平衡数据分布。
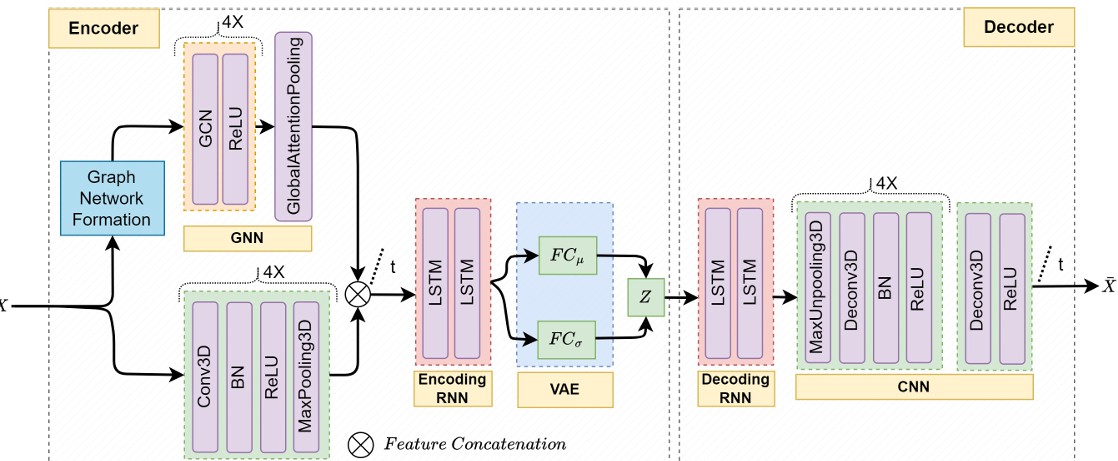
四、前沿研究成果分析
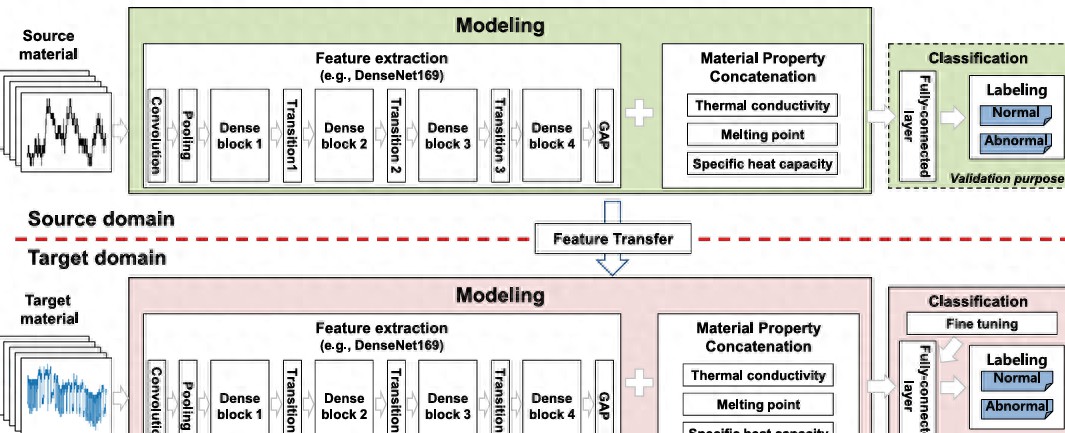
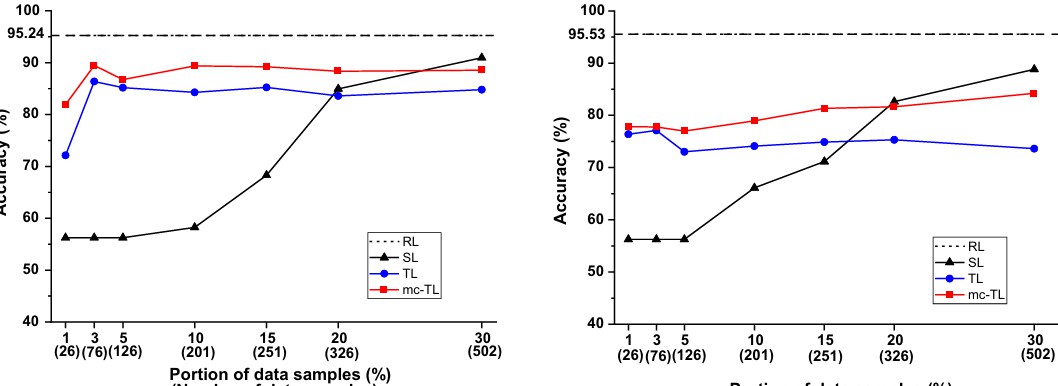
在材料自适应异常检测中,众多研究者提出了一种新方法,通过属性连接的迁移学习,从源材料中导出基于CNN的模型并成功地应用到目标材料中。例如,在金属的熔化与固化过程中,研究者们通过结合材料的具体属性与图像特征,显著提高了异常检测的精确度。研究人员还通过大量实验数据表明,这种方法在数据稀缺条件下表现优异。
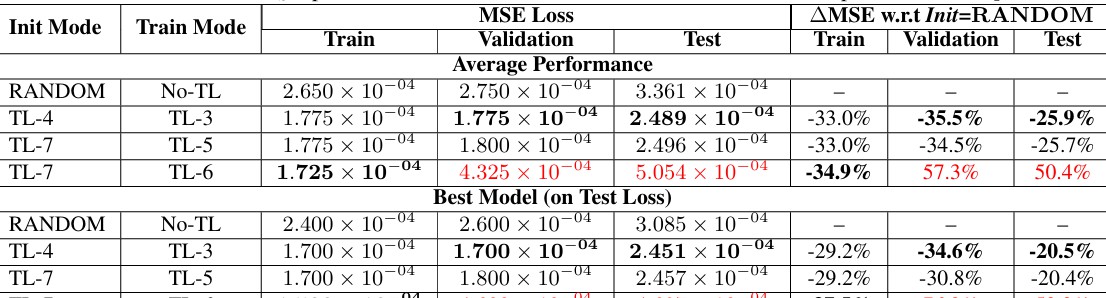
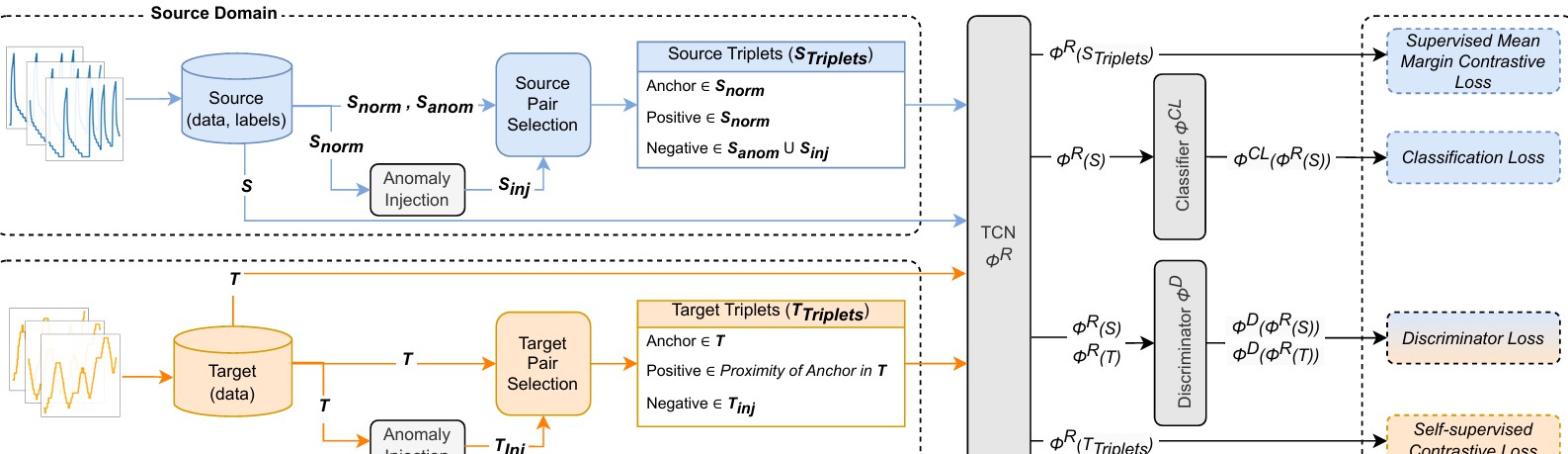
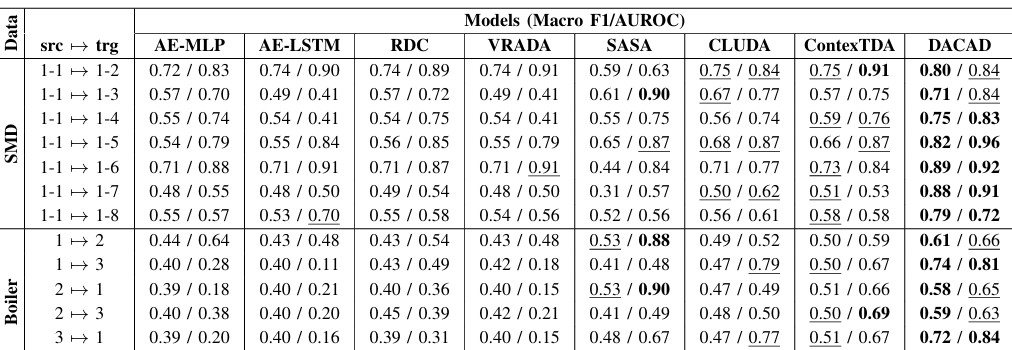
多变量时间序列的异常检测也在不断发展中,据相关论文指出,DACAD方法使用了监督对比损失及自监督对比三元损失,确保了特征表示学习的全面性。这种方法确保了在复杂的时间序列数据中,模型仍能准确识别出异常模式,为我们今后的应用提供了宝贵的参考。
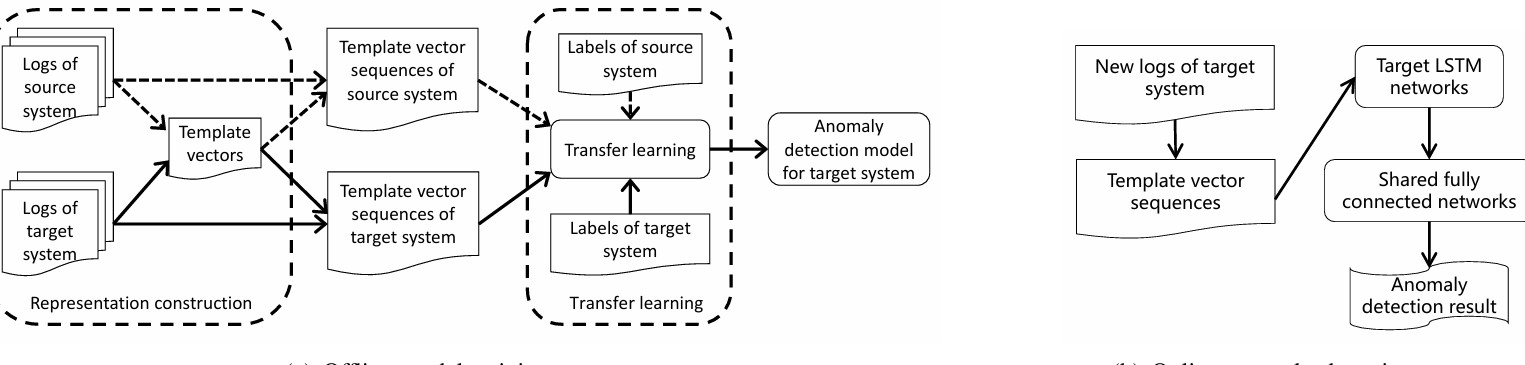
这种方法的核心在于构建了一个新的对比学习框架,其中结合了无监督领域适应性与对比学习,相比传统方法显著提升了模型在不同领域的适应性。结合深度一类分类器的中心熵分类器设计,使得在几乎所有的应用场景中都具备良好的表现。

五、结尾
感谢各位读者朋友们的耐心阅读,希望能通过本文了解迁移学习与异常检测的种种应用与挑战。如果您对此话题有更深入的看法或建议,欢迎在下方留言讨论,分享您的看法!