
轻松配置Ollama服务,助力LangChain-ChatChat等应用!
在LangChain、ChatChat和Flowise中优雅配置Ollama服务
在如今的人工智能和机器学习领域,大型语言模型(LLMs)的应用越来越广泛。随着这些模型的不断增大和复杂化,如何在有限的硬件资源上高效运行多个大模型应用,成为了我们不得不面对的问题。今天,我们就来聊聊如何在LangChain、ChatChat和Flowise等应用中,优雅地配置Ollama服务,让我们的机器“轻装上阵”,同时保持高性能。
想象一下,你的机器上安装了多个大模型应用,每个应用都需要占用大量的显存和计算资源。如果这些应用都运行在Local模式下,那么你的机器很快就会变得不堪重负,资源利用率低下。为了解决这个问题,我们可以考虑将大模型服务化,也就是将模型部署为服务,供多个应用共享使用。这样不仅可以减少显存占用,还可以提高资源的整体利用率。
在众多开源工具中,Ollama是一个备受瞩目的选择。Ollama是一个用于构建和部署大型语言模型服务的框架,它提供了丰富的功能和灵活的配置选项,让我们能够轻松地在大模型和应用之间建立桥梁。接下来,我们就来详细了解一下如何在LangChain、ChatChat和Flowise等应用中配置Ollama服务。
Ollama是一个强大的大模型服务化工具,它支持多种流行的模型格式,包括TensorFlow、PyTorch和Hugging Face Transformers等。通过使用Ollama,我们可以轻松地将模型部署为RESTful API或GRPC服务,供多个应用调用。此外,Ollama还提供了丰富的性能优化和扩展性选项,让我们能够根据实际需求调整服务配置。
与其他类似工具相比,Ollama具有以下几个优势:
灵活性:Ollama支持多种模型格式和部署方式,可以根据具体需求进行选择。

易用性:Ollama提供了简洁明了的配置选项和详细的文档支持,让我们能够快速上手并部署服务。
高性能:Ollama通过一系列优化技术,如批量处理、并发控制和异步执行等,实现了高效的大模型服务化。
在配置Ollama服务之前,我们需要先准备好相关的模型和依赖库。然后,按照以下步骤进行操作:
安装Ollama:我们需要从Ollama的官方仓库中下载并安装最新版本的Ollama。安装过程相对简单,只需要按照官方文档中的指引进行操作即可。
准备模型:将需要服务化的模型转换为Ollama支持的格式,并放置在指定的目录下。通常,我们需要将模型文件和相关配置文件一起放置在同一个目录下,以便Ollama能够正确加载和识别模型。
配置服务:在Ollama的配置文件中,我们需要指定模型的路径、服务端口、并发数等参数。这些参数可以根据具体需求进行调整。此外,我们还可以根据需要启用或禁用一些高级功能,如负载均衡、模型缓存等。
启动服务:完成配置后,我们就可以启动Ollama服务了。在命令行中输入相应的命令即可启动服务。此时,我们的模型就已经被成功部署为服务了,并可以通过指定的端口进行访问。
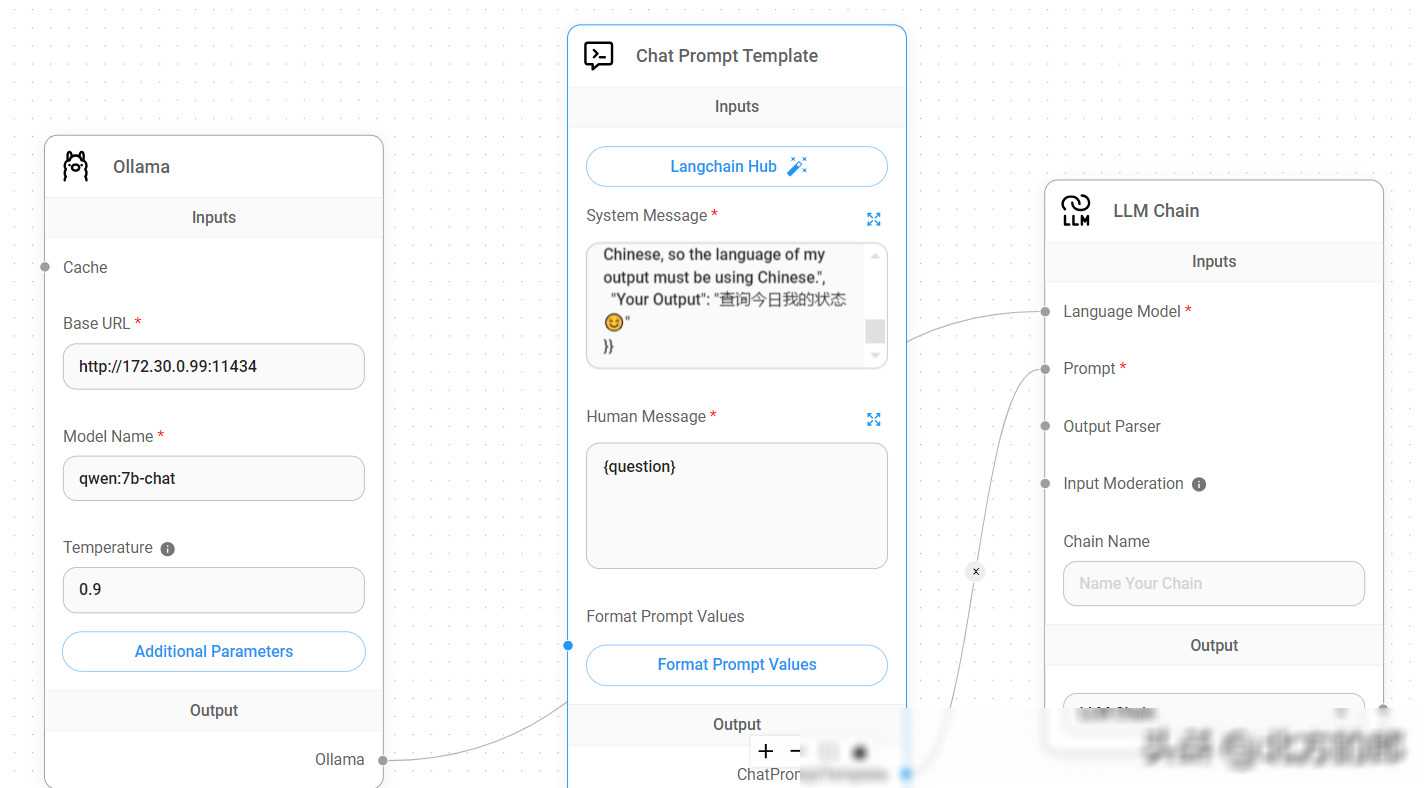
在配置过程中,我们可能会遇到一些问题或困惑。为了解决这个问题,我们可以参考Ollama的官方文档和社区支持。官方文档提供了详细的配置指南和常见问题解答,而社区支持则可以帮助我们快速找到解决方案并与其他开发者交流经验。
在将Ollama服务集成到LangChain、ChatChat和Flowise等应用中时,我们需要进行一些额外的设置和配置。具体来说,我们需要指定服务的访问地址和端口号,并在应用中添加相应的调用代码。
在集成过程中,我们可能会遇到一些问题或挑战。例如,服务启动失败、模型加载失败、性能瓶颈等。为了解决这些问题,我们可以采取以下措施:
检查配置文件:我们需要仔细检查Ollama的配置文件,确保所有参数都设置正确。特别是模型的路径和端口号等关键参数,一定要仔细核对。
查看日志信息:如果服务启动失败或模型加载失败,我们可以查看Ollama的日志信息来获取更详细的错误信息。这些信息通常可以帮助我们快速定位问题所在。
优化性能:如果服务在运行过程中出现性能瓶颈,我们可以考虑调整并发数、批量处理大小等参数来优化性能。此外,我们还可以考虑使用负载均衡和模型缓存等技术来提高服务的扩展性和响应速度。
社区支持:如果以上方法都无法解决问题,我们可以向Ollama的社区寻求帮助。在社区中,我们可以与其他开发者交流经验、分享解决方案并获取官方支持。
通过以上的介绍和实践经验分享,我们相信你已经对如何在LangChain、Chat