
颜水成程明明新突破!DiT训练速度飙升10倍!
Masked Diffusion Transformer:引领图像生成领域的新浪潮
在人工智能的浪潮中,图像生成技术一直是备受瞩目的焦点。从最初的简单像素生成到如今的高质量图像合成,每一步的进展都凝聚了无数研究者的智慧和汗水。而在这个领域中,Sora核心组件DiT以其惊艳的效果赢得了广泛的赞誉。随着模型规模的不断扩大,训练成本也呈现指数级增长,这成为了制约图像生成技术进一步发展的瓶颈。

正是在这样的背景下,颜水成和程明明研究团队提出了一种全新的解决方案——Masked Diffusion Transformer(MDT)。这一技术的诞生,不仅大幅提升了图像生成的训练速度,更在图像质量上实现了质的飞跃。今天,我们就来深入了解一下MDT的技术原理、优势以及它在图像生成领域的应用前景。
一、MDT的技术原理

MDT的核心理念在于利用mask modeling表征学习策略来加速Diffusion Transformer的训练过程。具体来说,MDT在保持扩散训练过程的引入了mask部分加噪声的图像token。通过这一机制,MDT能够显式地增强Diffusion Transformer对上下文语义信息的学习能力,并增强图像中物体之间语义信息的关联学习。
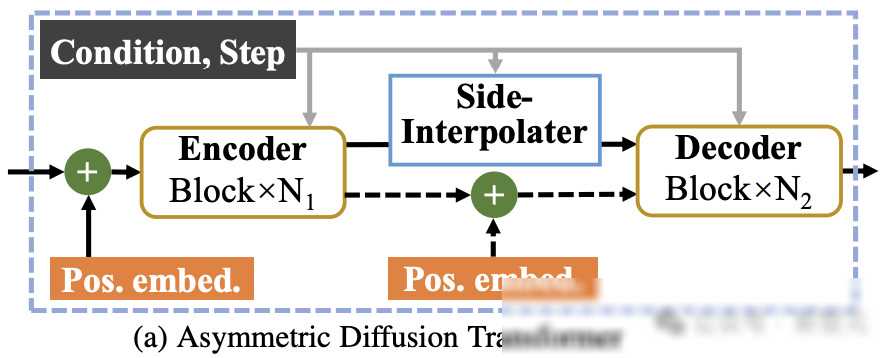
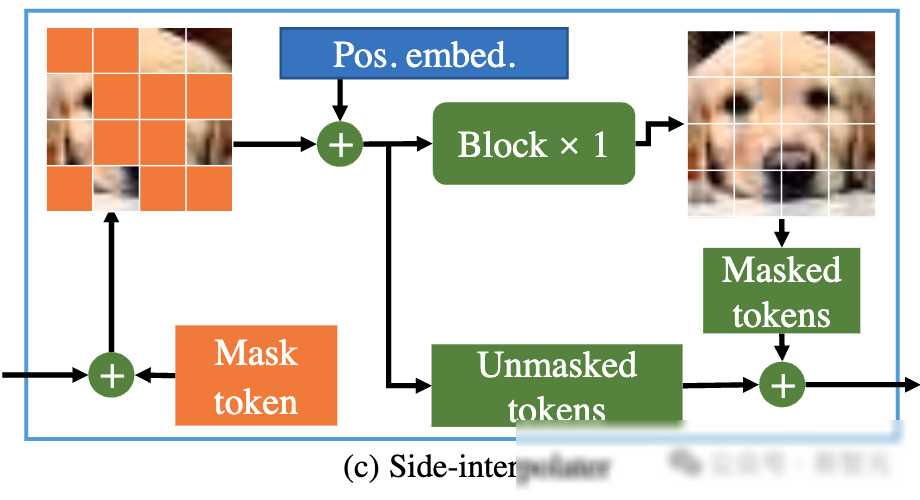
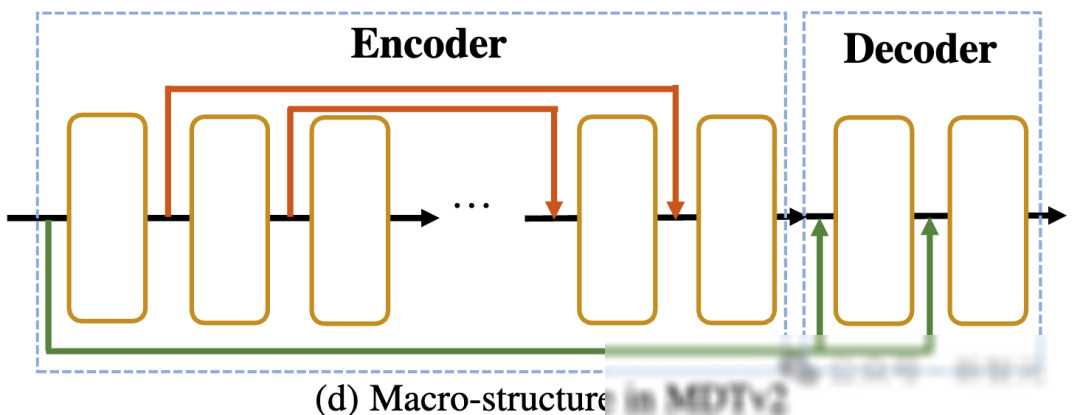
在训练过程中,MDT首先会对部分图像token进行mask处理,并将剩余的token送入Asymmetric Diffusion Transformer进行训练。这个非对称架构包括encoder、side-interpolater(辅助插值器)和decoder三个部分。其中,encoder只处理未被mask的token,而decoder则负责处理所有的token。为了保证在训练或推理阶段,decoder始终能处理所有的token,研究者们提出了一个巧妙的方案:在训练过程中,通过side-interpolater从encoder的输出中插值预测出被mask的token,并在推理阶段将其移除,从而不增加任何推理开销。
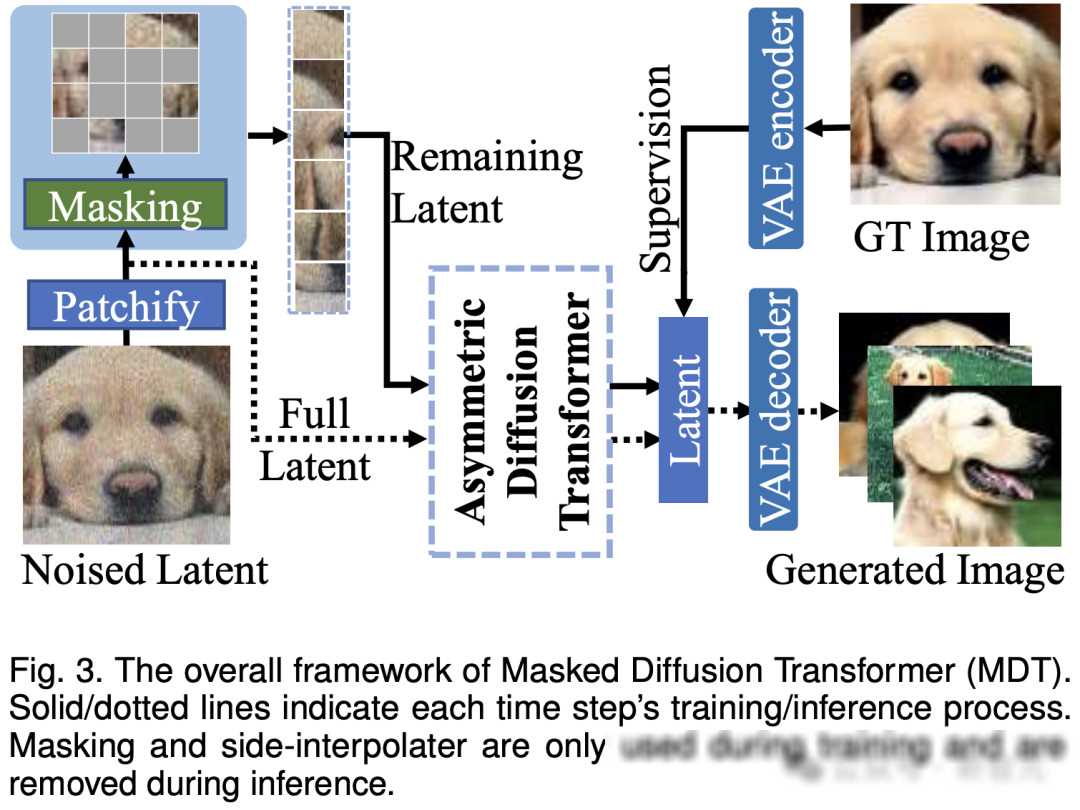
这样的设计使得MDT在训练过程中能够同时实现mask modeling和扩散训练两个过程。通过mask modeling,MDT能够学习到图像中物体各部分之间的语义关系,从而提高模型的收敛速度和生成质量。而扩散训练则保证了模型对图像细节的生成能力。
二、MDT的优势
训练速度提升:相比DiT,MDT的训练速度提升了10倍以上。这意味着在相同的时间内,MDT能够完成更多的训练迭代,从而更快地收敛到最优解。这不仅降低了训练成本,还加快了新模型的研发速度。
图像质量提升:MDT在ImageNet benchmark上实现了1.58的FID score,这一成绩在图像生成领域处于领先地位。MDT生成的图像质量更高、细节更丰富、语义关系更准确。这得益于MDT对上下文语义信息的强学习能力以及物体之间语义信息的关联学习。
灵活性:MDT的设计使其能够灵活地适应不同的任务和数据集。无论是简单的图像生成任务还是复杂的场景合成任务,MDT都能够通过调整模型参数和训练策略来达到最佳效果。

三、MDT在图像生成领域的应用前景
MDT的出色表现使其在图像生成领域具有广阔的应用前景。在娱乐产业中,MDT可以应用于游戏开发、虚拟现实等领域,为玩家带来更加逼真的视觉体验。在广告营销领域,MDT可以生成高质量的广告图片和视频素材,提高广告的吸引力和传播效果。此外,MDT还可以应用于医学影像处理、安防监控等领域,为医疗和公共安全事业提供有力支持。
随着技术的不断发展,MDT还有望与其他先进技术进行融合和创新。例如,将MDT与生成对抗网络(GAN)相结合,可以进一步提升图像生成的质量和多样性;将MDT应用于自然语言处理领域,可以实现文本到图像的自动生成等。这些创新应用将不断拓宽MDT的应用领域和市场前景。
四、结语
Masked Diffusion Transformer作为一种全新的图像生成技术,以其独特的优势在人工智能领域引起了广泛关注。它的出现不仅解决了传统扩散模型在训练速度和图像质量方面的不足,更为图像生成技术的发展开辟了新的道路。随着技术的不断进步和应用场景的不断拓展,我们有理由相信MDT将在未来发挥更加重要的作用为人工智能领域的发展贡献更多的智慧和力量。