
LabVIEW数组字符串神技!词频统计轻松搞定!
LabVIEW中的词频统计:从文本到智慧的转换
在信息爆炸的时代,文本数据无处不在,如何有效地从海量文本中提炼出有价值的信息,成为了许多领域研究者关注的焦点。词频统计,作为一种基础的文本分析技术,可以帮助我们快速了解文本的主题分布、关键词提取等,对于文本数据的深入挖掘具有重要意义。今天,我们就来探讨一下如何在LabVIEW这一强大的工程软件中,实现英文词频统计的过程,并分享一些实用的技巧和心得。

一、词频统计的基本概念
词频(Term Frequency,简称TF)是信息检索和文本挖掘领域中的常用概念,它指的是一个词语在文本中出现的频率。通常,词频越高,表示该词语在文本中的重要性越大。词频的计算公式为:词频 = 词语出现的次数 / 文本的总词语数。这个简单的比值,却蕴含着丰富的信息。
二、LabVIEW中的词频统计实现
LabVIEW是一款由美国国家仪器(National Instruments)公司开发的工程仿真系统,广泛应用于自动化、测试与测量等领域。虽然LabVIEW主要用于工程领域,但其强大的数据处理能力和灵活的编程环境,也让它成为了文本处理领域的得力助手。
在LabVIEW中实现词频统计,主要涉及到以下几个步骤:
1. 文本预处理
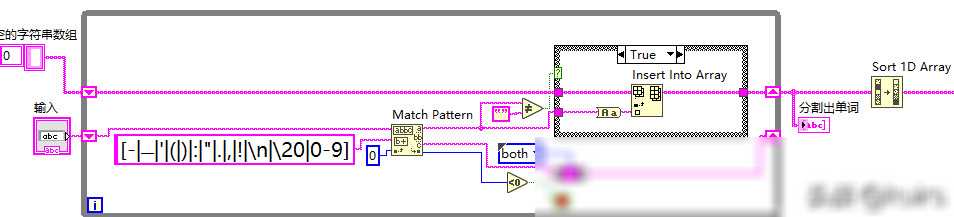
文本预处理是词频统计的第一步,也是非常重要的一步。预处理的主要目的是去除文本中的噪声信息,如标点符号、数字、换行符等,同时还需要将文本分割成单词或词组。在LabVIEW中,我们可以利用字符串函数和正则表达式来实现这些操作。例如,使用Match Pattern函数可以方便地匹配和替换文本中的特定字符;使用字符串分割函数可以将文本分割成单词或词组。
2. 单词分词

分词是文本处理中的一个重要环节,它将连续的文本切分成一个个独立的单词或词组。在英文文本中,单词之间通常使用空格进行分隔,因此分词相对简单。在LabVIEW中,我们可以使用字符串分割函数,将文本按照空格进行分割,得到一个个单词。为了提高分词的准确性,我们还可以结合正则表达式进行更复杂的匹配和替换操作。
3. 词频统计

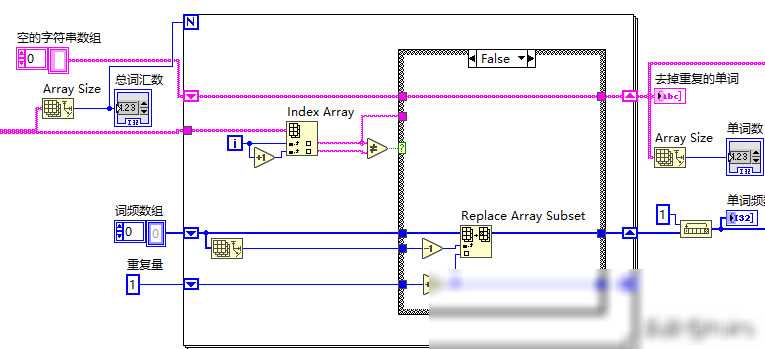
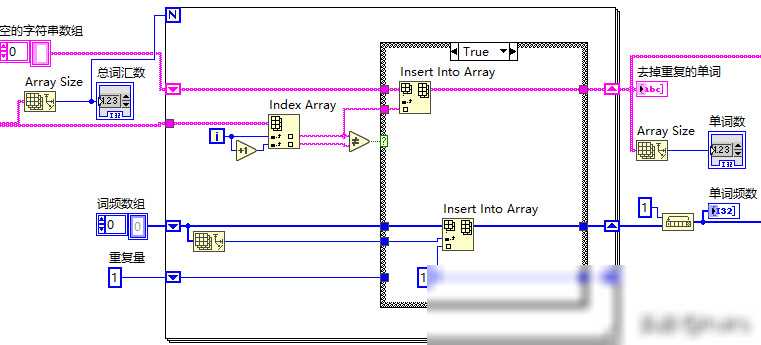
在得到分词后的单词列表后,我们就可以开始统计每个单词的词频了。在LabVIEW中,我们可以使用数组函数来实现这一功能。我们需要创建一个空的数组来存储单词和对应的词频;然后,遍历分词后的单词列表,对于每个单词,检查它是否已经在数组中出现过。如果出现过,则将其对应的词频加1;如果没有出现过,则将其添加到数组中,并设置词频为1。这样,我们就可以得到一个包含所有单词及其词频的数组。
需要注意的是,在统计词频时,我们还需要考虑一些特殊情况。例如,有些单词可能是缩写、缩写词或者不同的词形(如单复数、时态等),这些单词在词频统计时应该被视为同一个单词。为了解决这个问题,我们可以使用词干提取技术(Stemming)或者词形还原技术(Lemmatization)来将不同的词形还原为相同的词根形式。在LabVIEW中,虽然没有直接提供这些功能的函数或VI(Virtual Instrument),但我们可以借助其他编程语言(如Python、MATLAB等)来实现这些功能,并将结果导入到LabVIEW中进行后续处理。

4. 结果展示与分析
在得到词频统计结果后,我们需要将其以合适的方式展示出来。在LabVIEW中,我们可以使用图表、表格等可视化工具来展示词频统计结果。例如,我们可以使用柱状图来展示每个单词的词频分布;使用表格来展示每个单词及其对应的词频信息。我们还可以对词频统计结果进行进一步的分析和挖掘。例如,我们可以根据词频的高低来提取文本的主题关键词;根据关键词的共现情况来分析文本的主题结构等。这些分析结果可以为我们提供更深入的了解文本内容和结构的依据。
三、实战案例与经验分享
为了更好地说明LabVIEW在词频统计中的应用和技巧,我将结合一个实战案例来进行说明。假设我们有一篇关于机器学习技术的英文论文,我们想要通过词频统计来分析这篇论文的主题分布和关键词提取。
我们需要对论文文本进行预处理和分词操作。在这个过程中,我们需要注意一些特殊情况的处理。例如,论文中可能包含一些缩写词和专有名词(如算法名称、数据集名称等),这些词语在分词时应该被保留下来而不是被分割成多个单词。为了解决这个问题,我们可以使用正则表达式来匹配和保留这些特殊词语。
接下来,我们进行词频统计操作。在这个过程中,我们需要注意一些细节问题。例如,有些单词可能是无意义的停用词(如“the”、“and”、“a”等),这些单词在词频统计时应该被忽略掉。我们还需要注意一些单词的词形变化问题。例如,“running”和“