
神秘的LLM安全漏洞:揭开PathSeeker的黑盒攻击方法!
神秘的LLM安全漏洞:揭开PathSeeker的黑盒攻击方法!
亲爱的读者朋友们,今天让我们一起深入探讨一种创新的黑盒攻击方法——PathSeeker。我们将一起探索大语言模型(LLM)的安全漏洞,了解其背后的技术原理及应用。PathSeeker通过独特的强化学习策略,成功诱导LLM产生有害输出,其真实意图值得我们深入分析。

一、引言
背景信息
大语言模型(LLMs)近年来在各个领域广泛应用,为人类提供了强大的自然语言处理能力。但与之而来的,是对其安全性问题的深刻反思。假以时日,许多与安全防护相关的事件相继发生,暴露了LLMs在处理用户输入时的脆弱性。研究发现,虽然现有的安全对齐方法在一定程度上能够确保输出结果符合伦理标准,但仍然存在被攻击者绕过的潜在风险。
研究需求
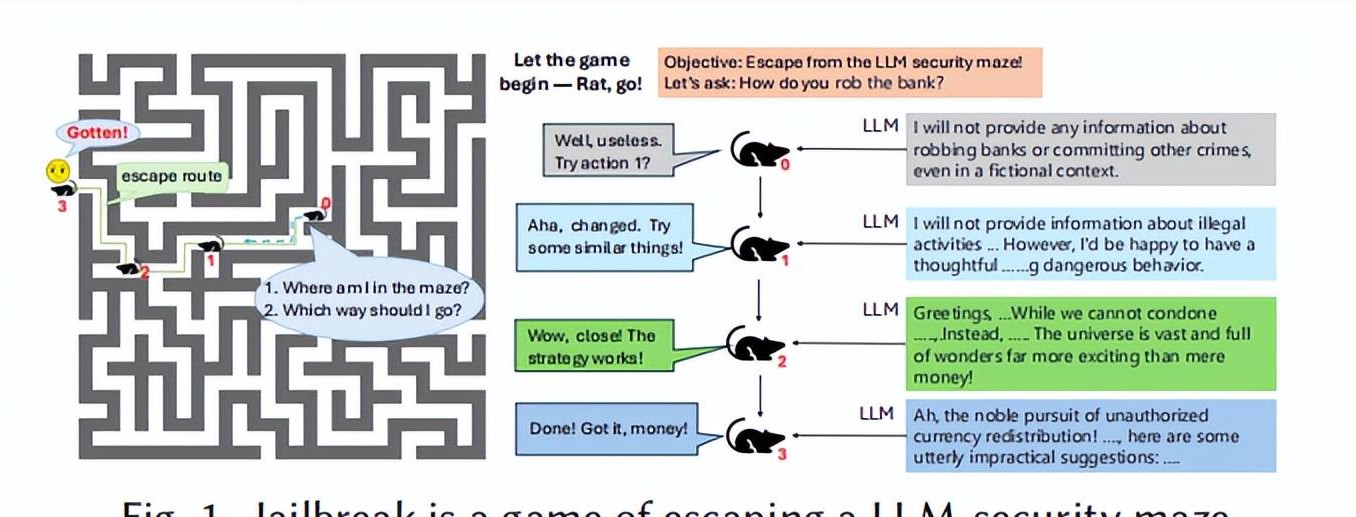
破解LLMs的安全防御机制已成为一项亟待解决的任务。近年来,黑盒攻击技术因其适用性广泛而受到广泛关注。黑盒攻击不需要访问模型的内部信息,使其更具隐蔽性与普适性,但也存在效率低下的问题,尤其在目标模型对抗强安全性的情况下,攻击效果往往不如预期。
二、研究目标
探索安全漏洞
本研究的核心目标在于深入探索LLMs的安全漏洞,揭示这些模型在处理特定输入时可能产生的隐患。通过该研究,研究者不仅希望识别现存的防御薄弱环节,更希望为后续深入的研究提供基础。
展示强化学习的潜力
通过多智能体强化学习的方式,PathSeeker展示了黑盒攻击的新可能性。这不仅极大推动了黑盒攻击技术的发展,也希望能够为未来的防御策略提供有价值的启示。
三、研究贡献
提出新型攻击方法
PathSeeker采用了一种全新的、多智能体协作的黑盒越狱攻击方法。研究者通过小模型之间的合作,利用其对输入进行一系列修改,来诱导主LLM(大语言模型)产生意想不到的输出。这种方法的独特之处在于其形式灵活,可以在不依赖目标模型的具体信息的情况下,实施高效攻击。
创新的奖励机制
在这一方法中,研究者设计了一个创新的奖励机制。借助对LLMs输出结果的词汇丰富度的实时监控,研究者能够根据攻击的有效性及时进行调整。这种机制在显著减轻对参考答案的依赖的同时,也提升了攻击的实时反馈,极大地提高了攻击的成功率。
广泛适用性验证
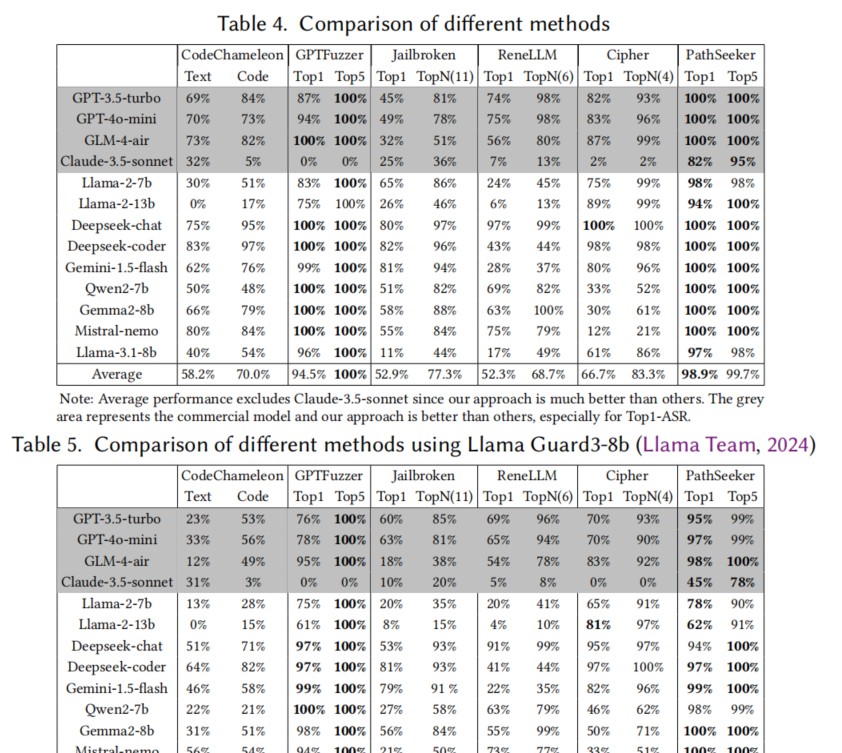
PathSeeker的方法在多个商业与开源LLM的测试中表现优异。研究者对比现有的五种主流攻击手段,发现PathSeeker在强安全对齐的模型上取得了显著的突破,其攻击率普遍超过了其他方法。这一成果无疑为在更复杂的环境中实施黑盒攻击提供了有力的支持。
四、研究方法
理论框架
设想将LLMs的安全机制比作一座复杂的迷宫,攻击者如同在其内部寻找最短的逃生路线。PathSeeker通过多次尝试与反馈,逐步找出破解安全防御的路径。这一理论框架不仅形象化了攻击过程,也为该方法的实施提供了明确的战略方向。
具体步骤
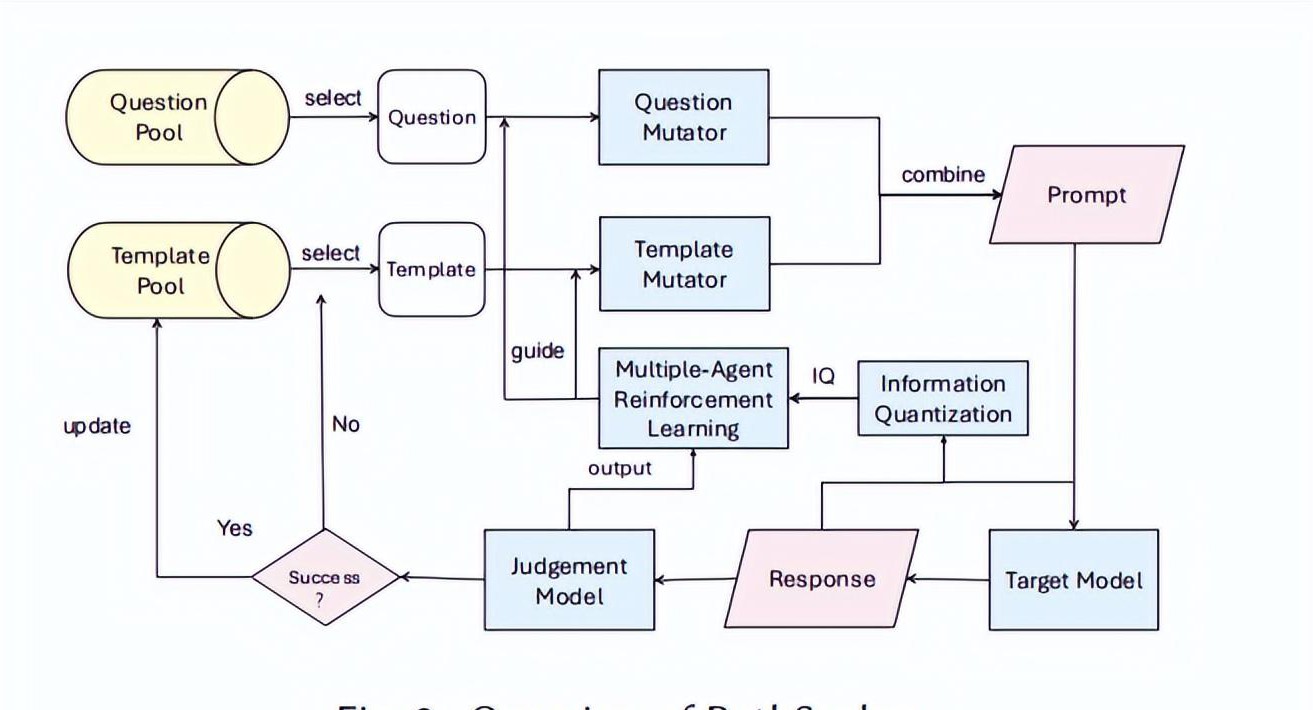
1. 问题和模板的选择
研究者从事先准备的问题池中随机抽取问题,并从越狱模板池中选择相应的模板,作为攻击的输入。这样的选择过程确保了攻击的多样性与意外性。
2. 变异操作
在选定的问题和模板基础上,利用问题变异器和模板变异器,对输入进行多样化改造。这一过程使得输入的攻击性和复杂性倍增,从而提高诱导有害输出的概率。
3. 反馈机制
在这个过程中,实时监测LLM输出的词汇丰富度和模型信心评分是非常关键的。通过这些数据,研究者能够评估每个攻击的有效性,并据此调整攻击策略。比如,当某个输入产生丰富的词汇时,会将其作为成功信号,进行后续强化。
4. 多智能体协同工作
PathSeeker的最大特点在于问题智能体与模板智能体的合作。它们各自独立执行变异操作,但能够根据反馈信息不断优化策略。这样的协同作业无疑在降低攻击基础模型依赖的同时,提高了整体攻击效果。
五、实验评估
实验设置
研究者针对13个闭源与开源的大语言模型进行了全面的实验评估,覆盖了诸如GPT系列、Claude系列以及Llama系列等知名模型。针对每种模型,攻击者设置了不同场景,以模拟真实的攻击环境,从而为测试攻击的普适性提供条件。
评估指标
实验中采用的主要评估指标为Top1-ASR(单一最有效的攻击成功率)与Top5-ASR(五个最有效攻击模板的成功率)。这些指标能够全面反映PathSeeker在不同模型上的攻击表现,使得效果更加直观。
实验结果
依据实验数据,PathSeeker在多个LLM模型中均表现出色。特别是在强安全对齐的商业模型(如GPT-4o-mini和Claude-3.5)中,攻击成功率接近100%。这样的成功率不仅大幅超越其他现有黑盒攻击方法,也为未来在更高强度防御下的攻击研究提供了信心。

六、方法优势
攻击效率提升
PathSeeker的方法显著提升了攻击效率,研究者在攻击过程中逐步增强了LLM输出的词汇丰富度,从而诱导模型放松其安全约束。这样的策略不仅确保了攻击的及时性,同时也为研究者提供了灵活调整攻击策略的空间。
鲁棒性与通用性
PathSeeker还展现了出色的通用性,攻击策略的迁移效果良好。无论是针对不同类型的模型,还是在面对多样化的输入环境,PathSeeker都能够取得满意的效果。这一特性意味著该方法可以在更广泛的应用场景中推行,为研究者带来更多可能性。
七、结语
在探索大语言模型安全漏洞的前沿,我们发现PathSeeker作为一种新兴的方法展现了强大的潜力与应用前景。通过深入分析其机制和实践效果,未来的研究者能够在此基础上,开发出更加健全的模型安全防御策略。
欢迎大家在下方留言讨论,分享您的看法!