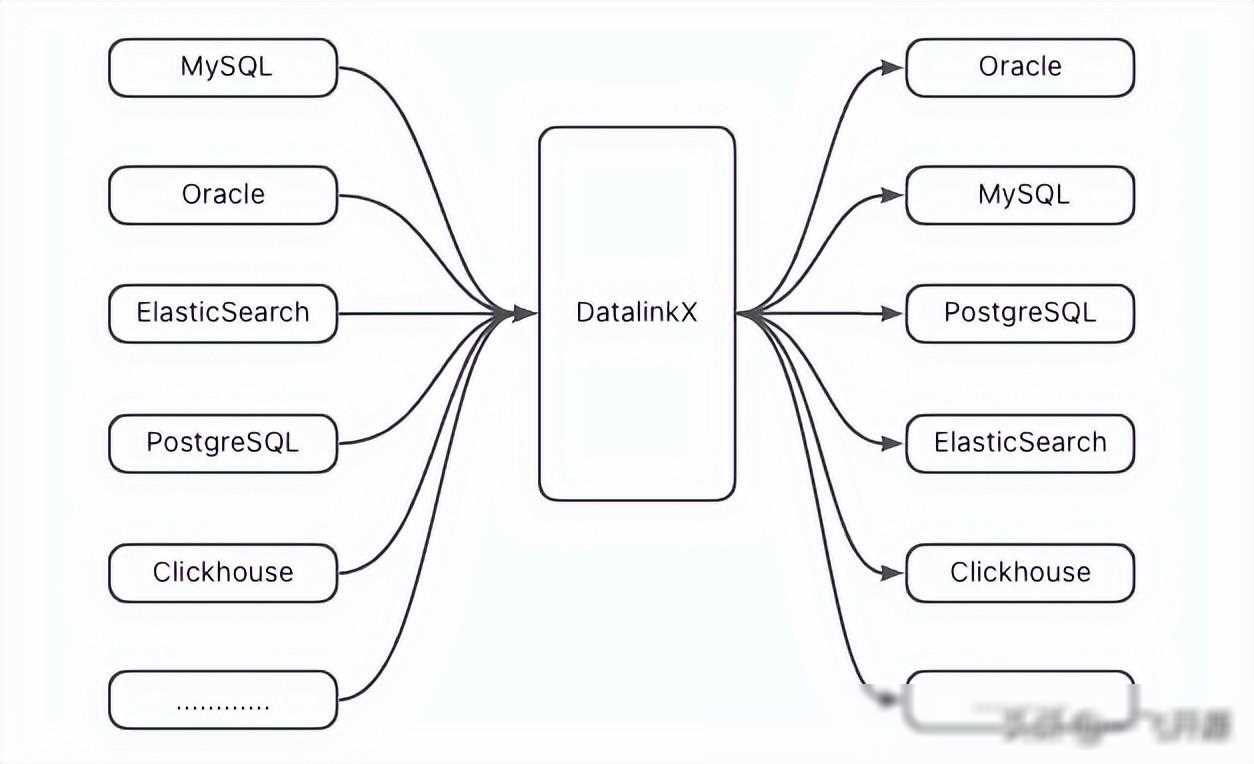
Flink异构数据源流转,高效同步神器!
探索基于Flink的异构数据源流转系统:从理论到实践的飞跃
在数字化浪潮的推动下,数据的价值日益凸显。如何在复杂多变的数据环境中实现高效、稳定的数据流转,成为了众多企业和开发者面临的挑战。一飞开源社区推出的基于Flink的异构数据源流转系统,以其简单易用、高性能的特点,为这一难题提供了有效的解决方案。本文将带你深入了解这一系统的设计理念、核心功能以及部署运行方法,同时分享一些实际应用案例和前景展望。
一、引言

在大数据时代,数据的多样性、异构性和实时性要求日益增强。传统的数据同步方案往往难以满足这些需求,导致数据流转效率低下、稳定性差。基于Flink的异构数据源流转系统应运而生,它利用Flink强大的分布式处理能力,结合多种数据源的支持,实现了高效、稳定的数据流转。
二、系统概述
基于Flink的异构数据源流转系统是一个开源项目,旨在解决不同数据源之间的数据同步问题。该系统通过配置化的方式,实现了数据源的灵活接入和数据流转的自动化管理。它支持多种数据源,包括关系型数据库、NoSQL数据库、消息队列等,并提供了丰富的数据同步策略,满足不同场景下的需求。
三、核心功能
数据同步
该系统能够在不同的异构数据源之间进行数据同步,包括全量同步、增量同步和实时同步等多种方式。通过配置化的方式,用户可以轻松实现数据的自动同步,减少了手动操作的繁琐和错误。
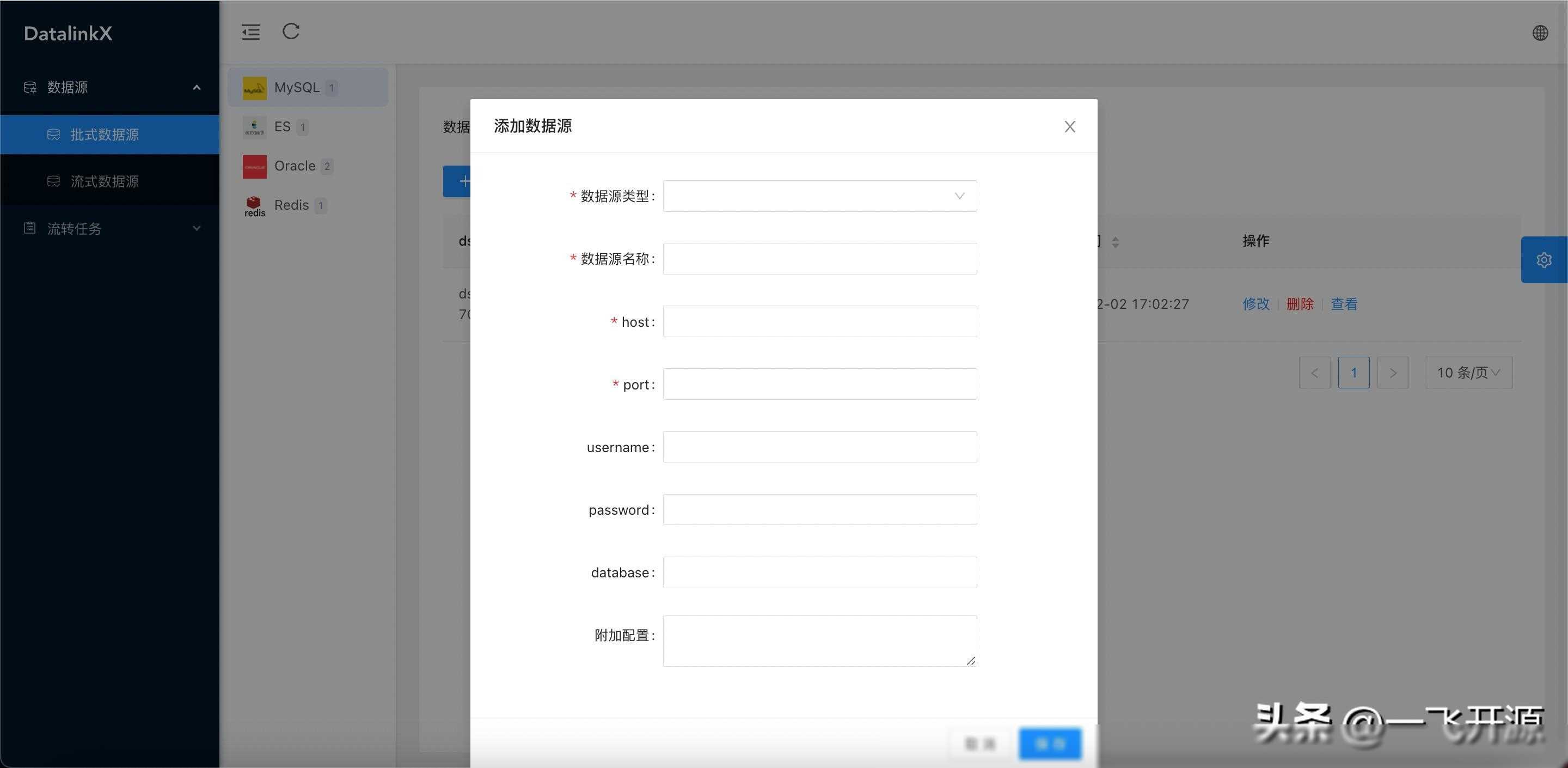
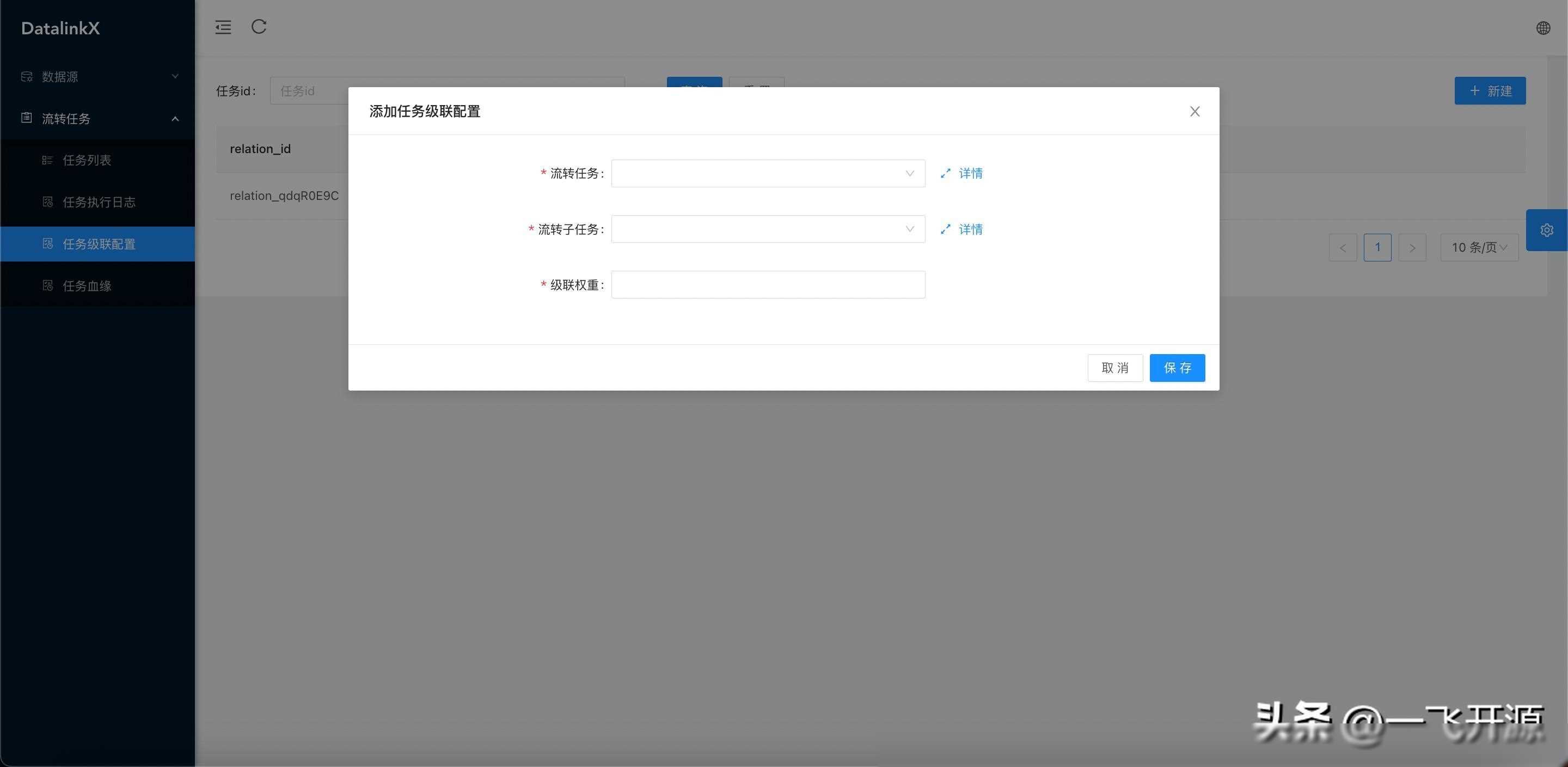
任务管理
系统提供了强大的任务管理功能,包括任务的创建、编辑、删除、暂停、恢复等。用户可以通过可视化的界面,实时查看任务的运行状态和日志信息,方便进行问题排查和性能调优。
同步服务
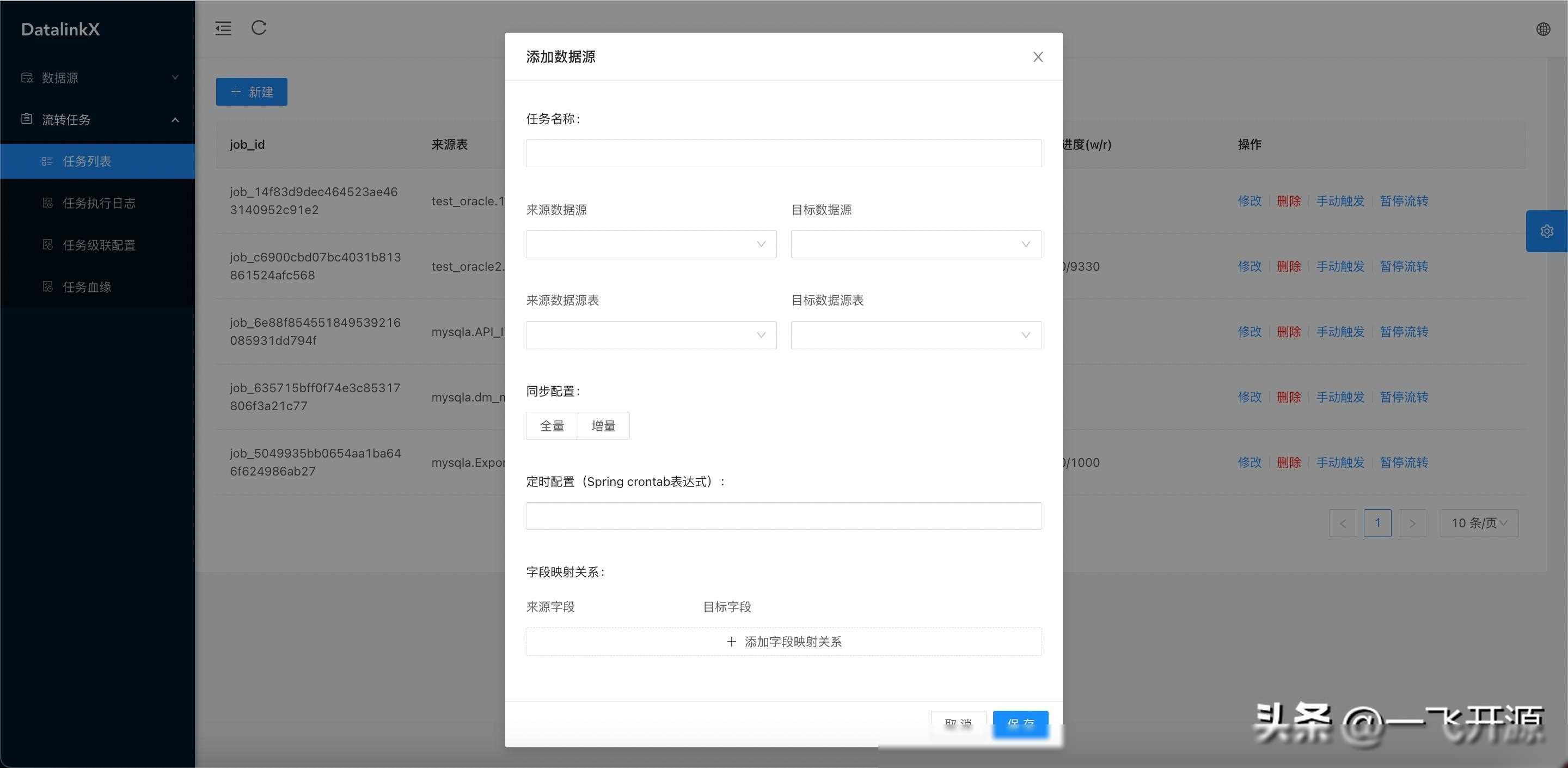
该系统还提供了同步服务,用于集中管理同步任务。通过同步服务,用户可以方便地收拢同步日志,提高内部工作效率。系统还提供了丰富的监控和报警功能,确保数据同步的稳定性和可靠性。
四、技术特点
高性能
基于Flink的分布式处理能力,该系统能够实现高效的数据流转。通过并行计算和流处理技术,系统能够充分利用计算资源,提高数据处理的效率。
可扩展性
系统支持多种数据源和同步策略,具有良好的可扩展性。用户可以根据实际需求,灵活配置数据源和同步策略,满足不同的业务需求。
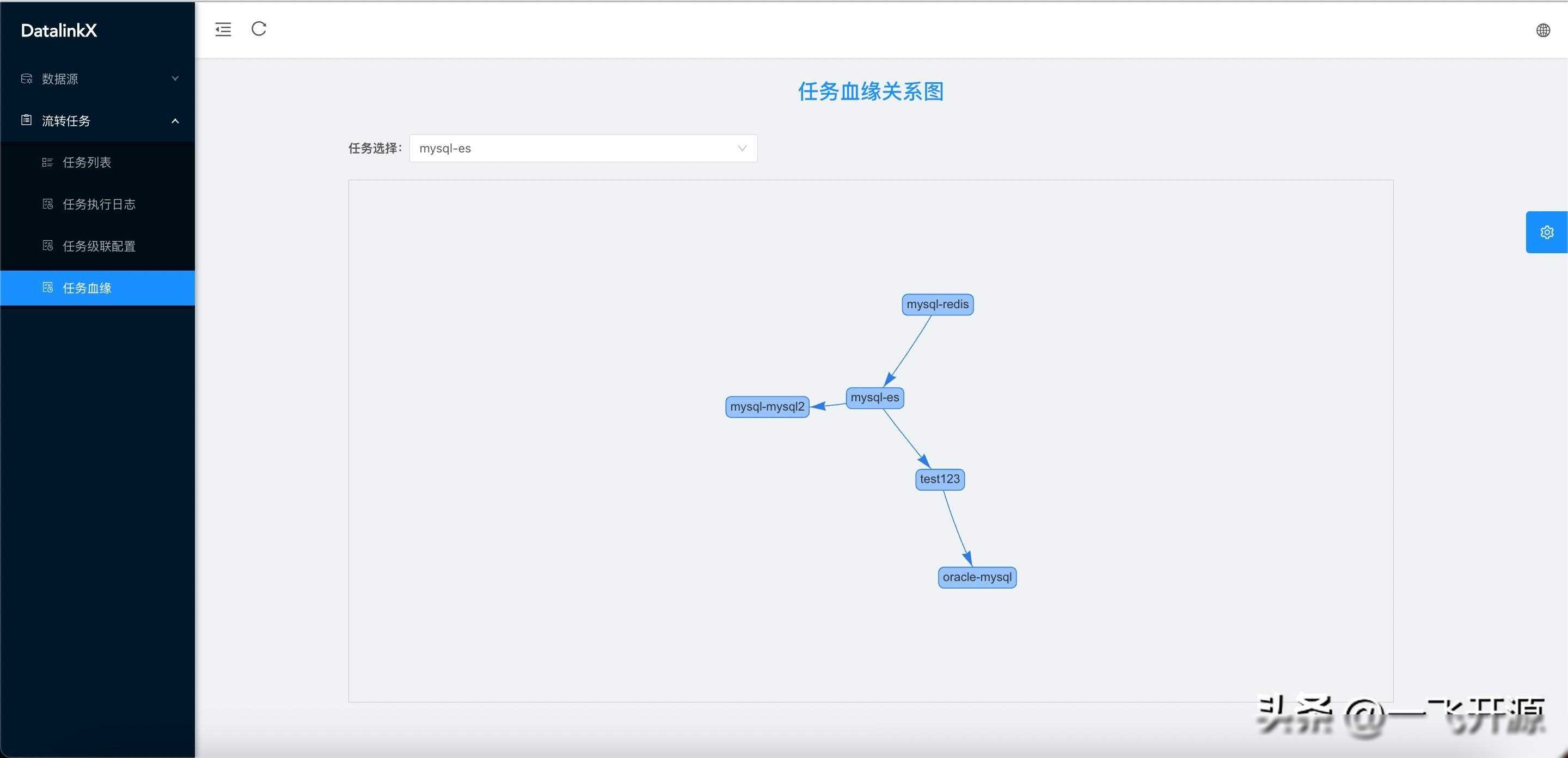
易用性
系统提供了可视化的界面和配置化的方式,使得用户可以轻松地进行数据同步和任务管理。系统还提供了丰富的文档和示例,帮助用户快速上手。
五、部署与运行
基于Flink的异构数据源流转系统支持Docker容器化部署,使得部署过程更加简单和高效。用户只需执行相应的命令,即可启动各组件并配置相关参数。系统还提供了详细的部署文档和教程,帮助用户快速完成部署和配置。
六、实际应用案例
某电商企业拥有多个业务系统和数据源,需要实现数据的实时同步和共享。通过引入基于Flink的异构数据源流转系统,该企业成功实现了多个数据源之间的数据同步,并提高了数据流转的效率和稳定性。该系统还提供了丰富的监控和报警功能,帮助企业及时发现和解决数据同步过程中的问题。
七、前景展望
随着大数据和云计算技术的不断发展,数据的多样性和异构性将进一步增强。基于Flink的异构数据源流转系统将继续发挥其在数据流转领域的优势,为更多的企业和开发者提供高效、稳定的数据同步解决方案。未来,该系统还将进一步优化性能、扩展功能和提升易用性,满足更多场景下的需求。
总之,基于Flink的异构数据源流转系统是一个功能强大、易于使用的数据同步解决方案。它利用Flink的分布式处理能力,结合多种数据源的支持,实现了高效、稳定的数据流转。无论是企业还是开发者,都可以从中受益,实现数据的价值最大化。