
深度学习新篇章:残差连接与层归一化详解!
一文理解深度学习中的残差连接和层归一化
在深度学习的广袤世界里,总有那么一些神秘而强大的名词,它们如同魔法师手中的法杖,赋予神经网络强大的能力。今天,我们就来聊聊其中的两位“魔法师”——残差连接和层归一化。它们不仅是深度学习领域的明星技术,更是Transformer模型中不可或缺的关键技术,为深度网络的训练注入了新的活力。
残差连接,顾名思义,就是在神经网络中建立一种“残差”的传递方式。在传统的神经网络中,每一层的输出都是直接作为下一层的输入。但随着网络层数的加深,这种直接的传递方式会带来一些问题,比如梯度消失和梯度爆炸。为了解决这些问题,残差连接应运而生。
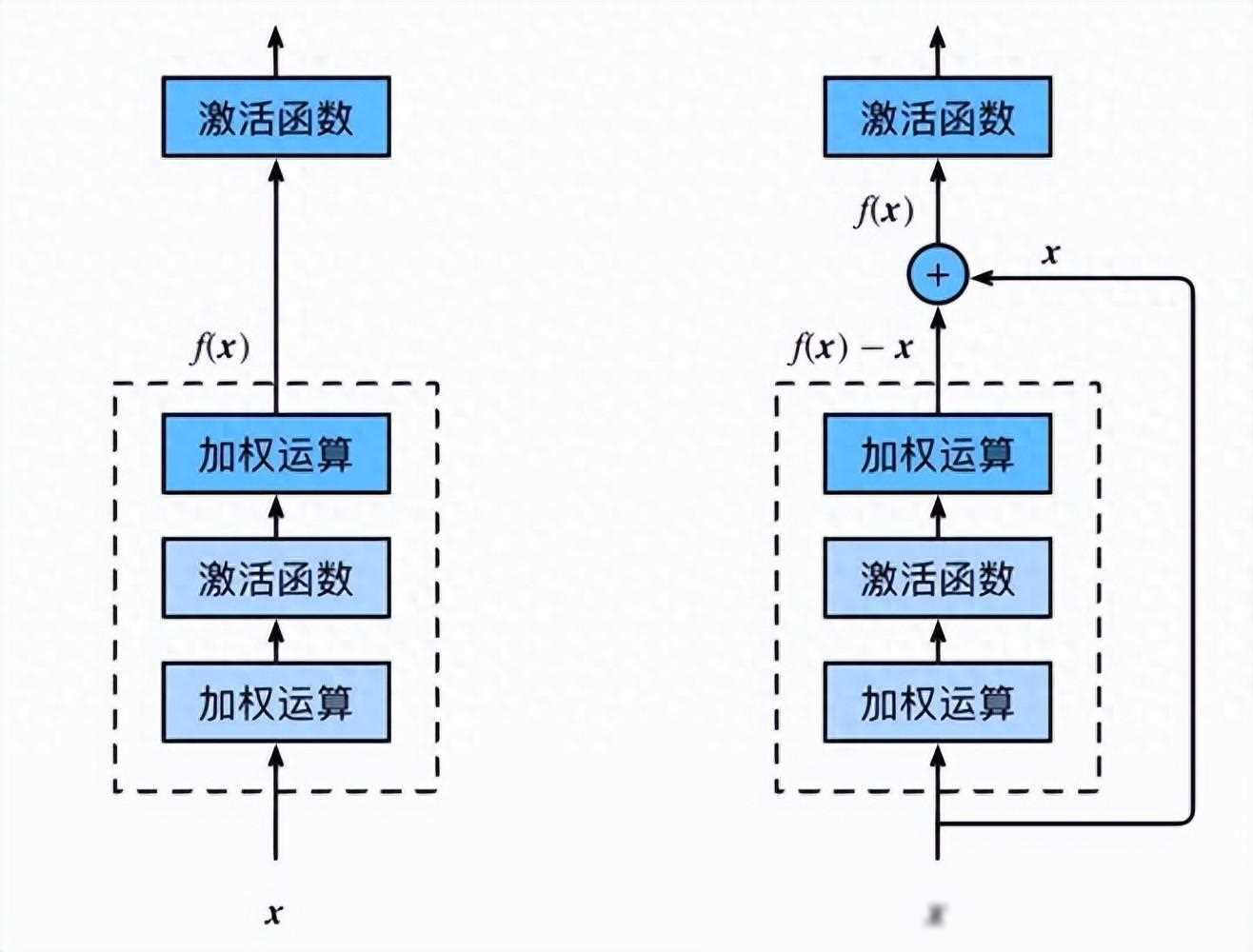
简单来说,残差连接就是在每一层之间增加一个“短路”连接,使得输入可以直接跳过中间的某些层,直接传递到后面的层。这样,即使网络层数很深,梯度也能有效地传播到前面的层,从而避免了梯度消失和梯度爆炸的问题。
残差连接的工作原理其实很简单。假设我们有一个神经网络层L,它的输入是x,输出是F(x)。在传统神经网络中,下一层的输入就是F(x)。但在残差连接中,下一层的输入变成了F(x) + x,即当前层的输出与输入之和。这样,即使F(x)的值很小,甚至接近于0,但由于有x的存在,下一层仍然能够接收到有效的信息。
残差连接在深度学习领域的应用非常广泛。以ResNet为例,它就是一个基于残差连接构建的深度神经网络。ResNet通过引入残差连接,成功地训练出了深度超过100层的神经网络,并在多个计算机视觉任务中取得了优异的成绩。
此外,在自然语言处理、语音识别等领域,残差连接也被广泛应用。比如,在Transformer模型中,就使用了大量的残差连接来加速训练和提高模型性能。
层归一化(Layer Normalization)是一种常用的归一化技术,它通过对神经网络每一层的输出进行归一化处理,来加速模型训练并提高稳定性。在深度学习中,由于数据分布的变化和激活函数的非线性特性,神经网络的输出往往会出现较大的波动。这种波动会导致模型训练的困难,甚至可能导致训练失败。而层归一化正是为了解决这个问题而诞生的。
层归一化的工作原理很简单。对于神经网络中的每一层,层归一化都会计算该层输出的均值和方差,然后用这两个统计量来对输出进行归一化处理。具体来说,就是将输出减去均值再除以标准差(或者标准差的一个近似值),得到一个归一化后的输出。这个归一化后的输出会被作为下一层的输入进行传递。
除了归一化处理外,层归一化还会引入两个可学习的参数:缩放因子和偏移量。这两个参数可以通过反向传播算法进行更新,从而实现对归一化输出的微调。这样,即使原始输出发生了较大的波动,经过层归一化处理后的输出也能保持相对稳定的状态。
在深度学习中,除了层归一化外,还有其他的归一化技术,如批量归一化(Batch Normalization)和实例归一化(Instance Normalization)等。这些技术虽然都能在一定程度上解决数据分布变化的问题,但各有优缺点。
批量归一化是在一个批次的数据上进行归一化处理,它可以减少内部协变量偏移(Internal Covariate Shift)问题,但对于小批次数据或者非批量训练的场景可能效果不佳。实例归一化则是对每个样本的每个通道进行归一化处理,它适用于图像生成等任务,但对于自然语言处理等任务可能不太适用。而层归一化则是对每一层的输出进行归一化处理,它不受批次大小和任务类型的影响,因此具有更广泛的适用性。
层归一化在深度学习领域的应用也非常广泛。除了Transformer模型外,还有许多其他的神经网络模型都使用了层归一化技术。比如,在循环神经网络(RNN)中,层归一化可以帮助解决梯度消失和梯度爆炸的问题;在卷积神经网络(CNN)中,层归一化可以加速训练并提高模型的稳定性。
Transformer模型是一种基于自注意力机制的神经网络模型,它在自然语言处理领域取得了巨大的成功。而残差连接和层归一化则是Transformer模型中的两个关键技术。
在Transformer模型中,每一层都包含了多个子模块,如自注意力模块、前馈神经网络模块等。这些子模块之间都使用了残差连接来传递信息。通过残差连接,即使网络层数很深,梯度也能有效地传播到前面的层,从而避免了梯度消失和梯度爆炸的问题。
同时,在Transformer模型的每一层中,都使用了层归一