Mamba大模型惊艳!三倍Transformer性能,告别局限!
探索AI新纪元:Jamba模型与Transformer的革新之旅
在人工智能的浪潮中,Transformer架构无疑是一颗璀璨的明星。自从2017年谷歌团队提出《Attention is All You Need》这篇开创性论文以来,Transformer就以其独特的自注意力机制,在生成式人工智能领域独领**。就像任何伟大的技术一样,Transformer也有着其局限性。今天,我们要聊的,就是一款可能改变这一格局的新兴技术——Jamba模型。
一、Transformer的荣光与挑战

Transformer架构的崛起,标志着人工智能在自然语言处理领域迈出了重要的一步。它解决了传统RNN(循环神经网络)在处理长序列时遇到的梯度消失和梯度爆炸问题,通过自注意力机制,让模型能够关注到输入序列中的每一个位置,从而捕捉更丰富的上下文信息。
随着模型规模的不断扩大,Transformer也暴露出了一些问题。其内存占用巨大,对于长序列的处理能力有限。Transformer的计算复杂度随着序列长度的增加而迅速增长,导致在处理长文本时效率低下。这些问题限制了Transformer在某些场景下的应用,也催生了新的技术探索。
二、Jamba模型:混合架构的新星

在这样的背景下,AI21 Labs推出并开源了一种名为Jamba的新方法。Jamba并非完全摒弃Transformer,而是采用了一种混合架构的设计,将基于结构化状态空间模型(S**)的Mamba模型与Transformer架构相结合,旨在将S**和Transformer的最佳属性结合在一起。
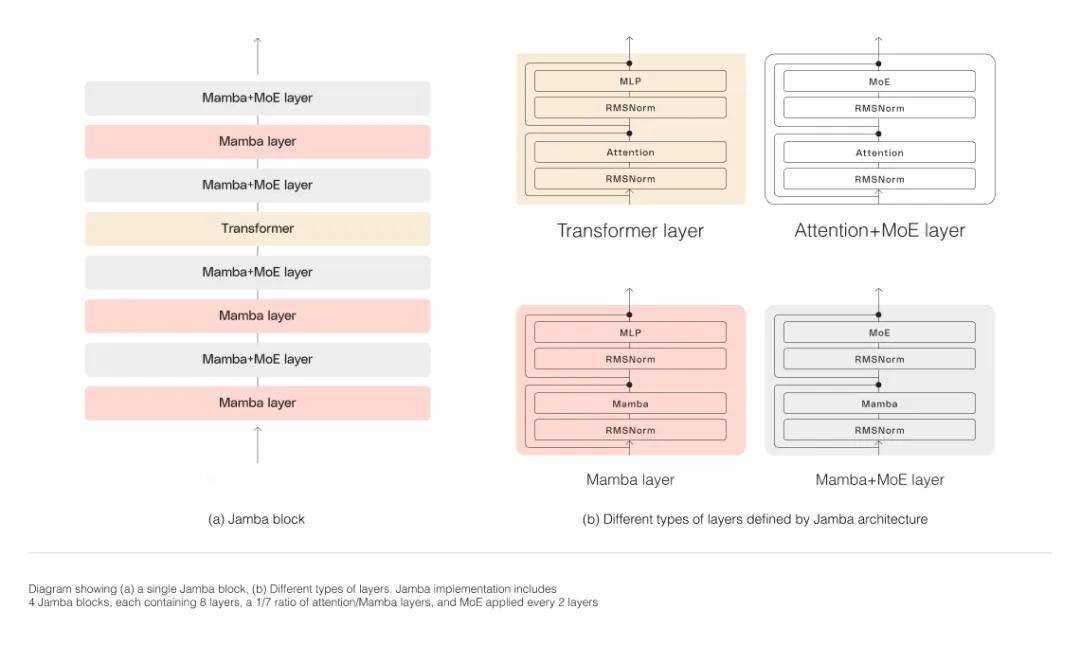
Jamba的架构采用了块层(blocks-and-layers)的设计方法,每个Jamba块包含一个注意力层或一个Mamba层,后跟一个多层感知器(MLP)。这种设计使得Jamba能够灵活地集成两种架构的优势,既能够捕捉长序列中的依赖关系,又能够降低计算复杂度和内存占用。
在Jamba中,MoE(Mixture of Experts)的利用是另一个亮点。通过引入多个专家网络,Jamba能够在不增加计算需求的情况下增加模型参数的总数,同时简化推理中使用的活跃参数的数量。这种设计使得Jamba能够在保证模型容量的提高推理效率和降低内存占用。

三、Jamba模型的性能优势
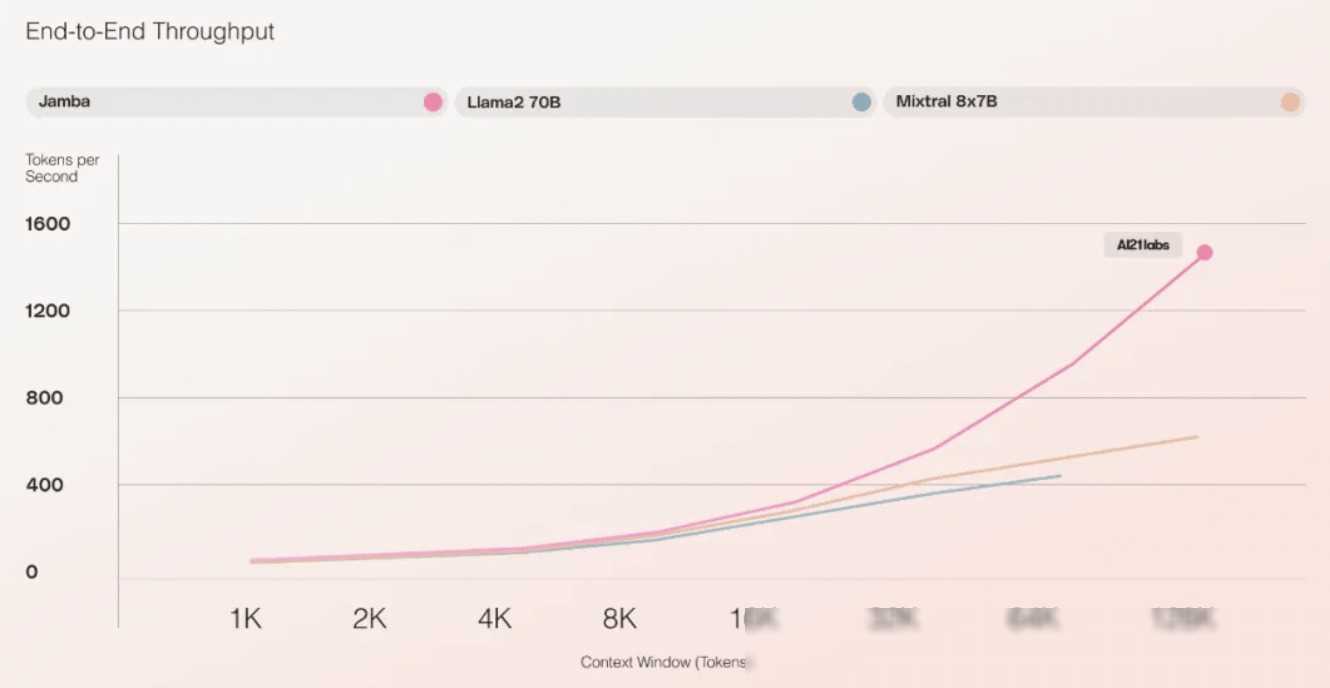
为了验证Jamba模型的性能优势,研究团队进行了一系列的实验。实验结果表明,Jamba在吞吐量和效率等关键衡量指标上表现出色。特别是在处理长上下文时,Jamba的吞吐量达到了Mixtral 8x7B的3倍,且比同等大小的基于Transformer的模型更高效。这意味着,在相同的硬件条件下,Jamba能够处理更多的数据,从而加速模型的训练和推理过程。
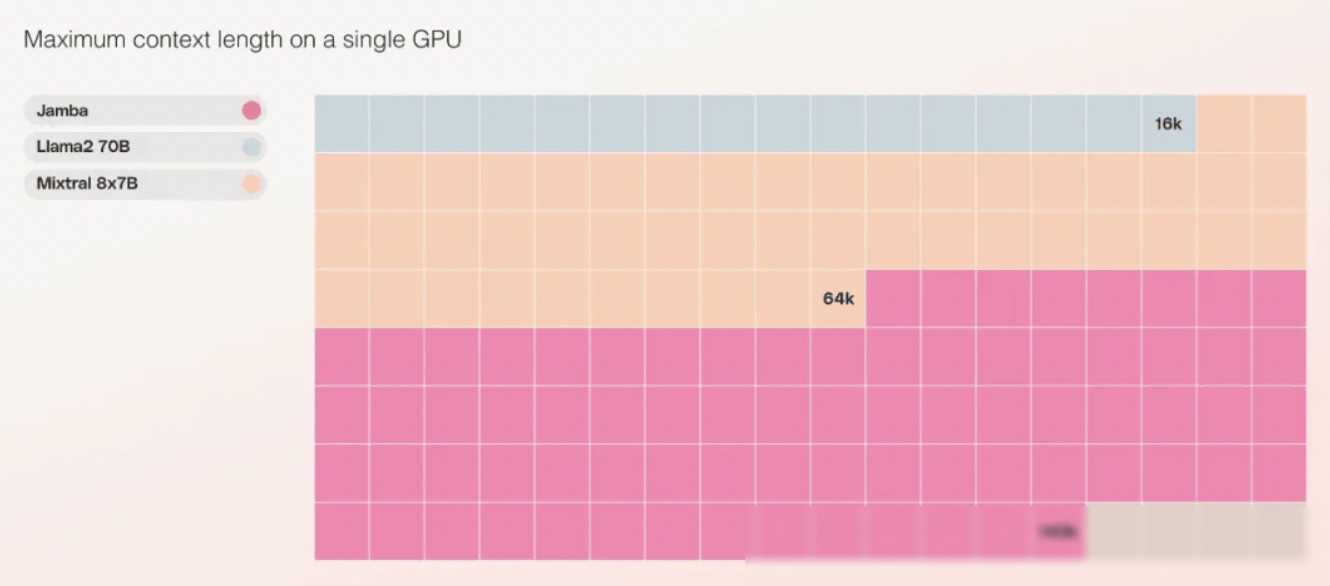
此外,Jamba在成本方面也具有显著优势。由于其较低的内存占用和高效的计算方式,Jamba可以在单个GPU上容纳更多的上下文信息。与当前类似大小的其他开源模型相比,Jamba能够提供更多的部署和实验机会,降低了企业的成本负担。
四、Jamba模型的应用前景
虽然Jamba目前不太可能完全取代当前基于Transformer的大型语言模型(LLM),但它无疑为某些领域提供了新的解决方案。例如,在需要处理长文本的场景下,如文档分类、摘要生成等,Jamba凭借其高效的吞吐量和内存占用优势,有望成为更好的选择。
此外,随着混合架构技术的不断发展,Jamba还有望与其他先进技术进行结合,形成更加灵活和高效的模型架构。例如,将Jamba与图神经网络(GNN)结合,可以进一步扩展模型对图结构数据的处理能力;将Jamba与强化学习结合,可以探索更加智能的决策过程。这些结合将为人工智能领域带来更多的创新机会。
五、结语
Jamba模型的推出,标志着人工智能领域在混合架构技术方面取得了新的进展。通过结合S**和Transformer的优势,Jamba在保持模型容量的提高了吞吐量和效率,降低了成本。虽然Jamba目前还无法完全取代Transformer的地位,但其为人工智能领域带来了新的思考方向和解决方案。
作为开发者,我们应该关注这些新兴技术的发展趋势,不断探索和尝试新的技术方法。我们也要认识到,技术的发展离不开社区的支持和贡献。让我们一起期待更多的创新技术出现,为人工智能领域带来更多的可能性!