
Linux三剑客之awk详解:文本处理的秘密武器,你掌握了吗?
Linux三剑客之awk详解:文本处理的秘密武器,你掌握了吗?
亲爱的读者朋友们,今天我们要深入探讨一个在Linux环境中常用却又被很多人忽视的强大工具——awk!无论你是编程新手还是有经验的开发者,掌握awk都能让你的工作效率提升一个档次。它不仅能让文本处理变得灵活高效,还能帮助你快速从海量数据中提取出有价值的信息。接下来,跟我一起解锁awk的潜能吧!
一、什么是awk?
awk的定义
awk是一种强大的编程语言,专门用于文本处理和数据分析。这种语言的名称来源于其创建者的姓氏首字母(Alfred V. Aho、Peter J. Weinberger和Brian W. Kernighan)。相较于其他处理文本的工具,awk的直观性和灵活性使其广受欢迎,尤其适合用于处理结构化文本,如CSV文件和数据库输出。面对复杂的数据,awk可以通过简单的几行代码迅速提取出我们所需的字段,这在日常的系统管理和数据分析中绝对是个宝藏工具。
功能特性
awk的强大之处在于其能够逐行读取输入文件,利用模式匹配来确定是否对当前行执行操作。这种方式使得awk能够高效地处理上万条数据。例如,假设你有一个学生成绩的CSV文件,awk只需提供实际需要的字段和条件,它便能迅速返回结果,这在数据分析时能够节省大量的时间与精力。
二、awk的基本语法
语法结构
awk的基本语法格式为:`awk '条件 {动作}' 文件名`。这一结构中的“条件”部分用于确定匹配哪些行,而“动作”部分则在满足条件的基础上,对这些行进行相应的处理。例如,如果我们有一个文件students.txt,包含了学生的ID、姓名和分数,想要提取所有分数大于80的学生信息,只需编写如下命令:
```bash
awk '$3 > 80 {print $0}' students.txt
```
`$3`表示第三列,也就是分数;`{print $0}`表示打印当前整行。
示例文件说明
让我们来看看一个示例文件的内容,它命名为pdsyw.txt:
```
1 Alice 85
2 Bob 78
3 Charlie 90
4 David 66
5 Eve 92
```
该文件包含了学生的ID、姓名和分数。在接下来的内容中,我们将利用这个文件,深入探讨awk的各种用法。
三、awk的基本用法
显示文件内容
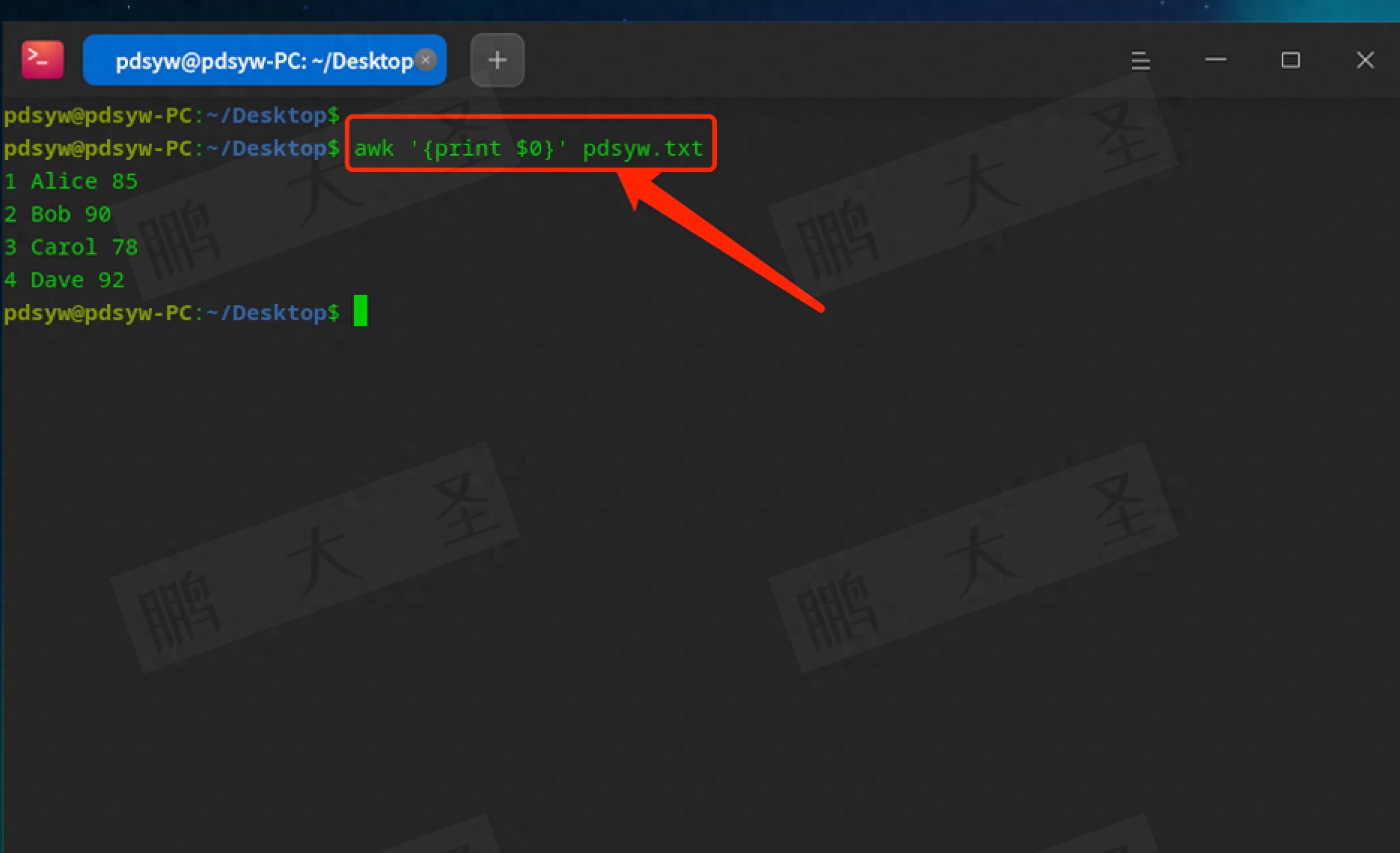
如果我们希望输出pdsyw.txt中的所有内容,使用`print $0`可以轻松实现。如下命令就能完成这项任务:
```bash
awk '{print $0}' pdsyw.txt
```
将逐行输出文件中所有的内容,这是确认文件内容的第一步。
指定输出列
我们只想查看特定的列信息,比如想要获得学生的姓名和分数。可以使用`$1`(第一列,ID)和`$3`(第三列,分数)来实现,示例命令如下:
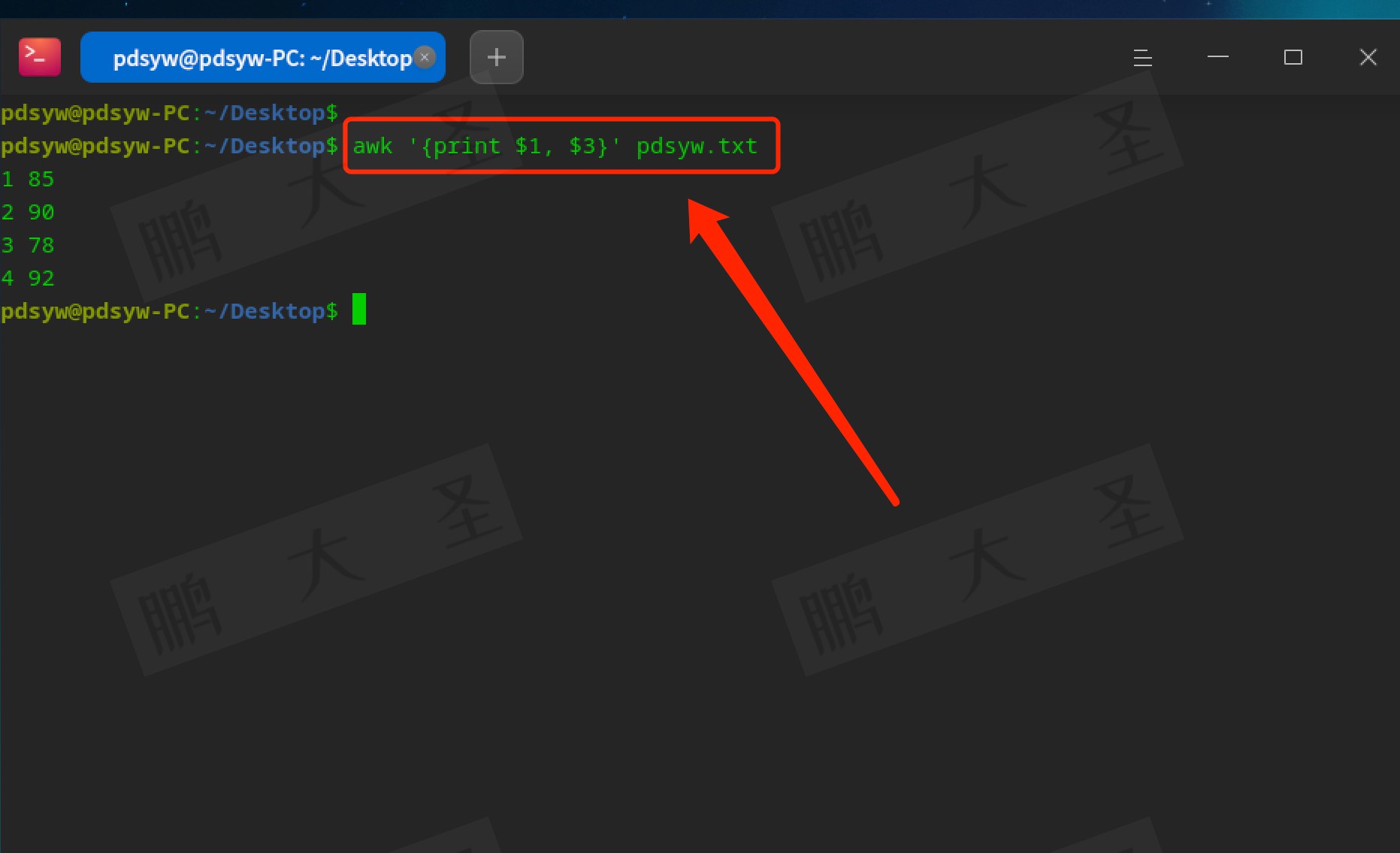
```bash
awk '{print $1, $2, $3}' pdsyw.txt
```
此时输出将为:
```
1 Alice 85
2 Bob 78
3 Charlie 90
4 David 66
5 Eve 92
```
输出带分隔符的内容
awk允许我们自定义输出内容的格式,例如在各列之间插入分隔符。假设我们想要用“ - ”作为分隔符来输出姓名和分数,我们可以这样写:
```bash
awk '{print $2 " - " $3}' pdsyw.txt
```
这条命令将返回如:
```
Alice - 85
Bob - 78
Charlie - 90
David - 66
Eve - 92
```
这种输出格式更加美观,也易于识别。
四、常用选项
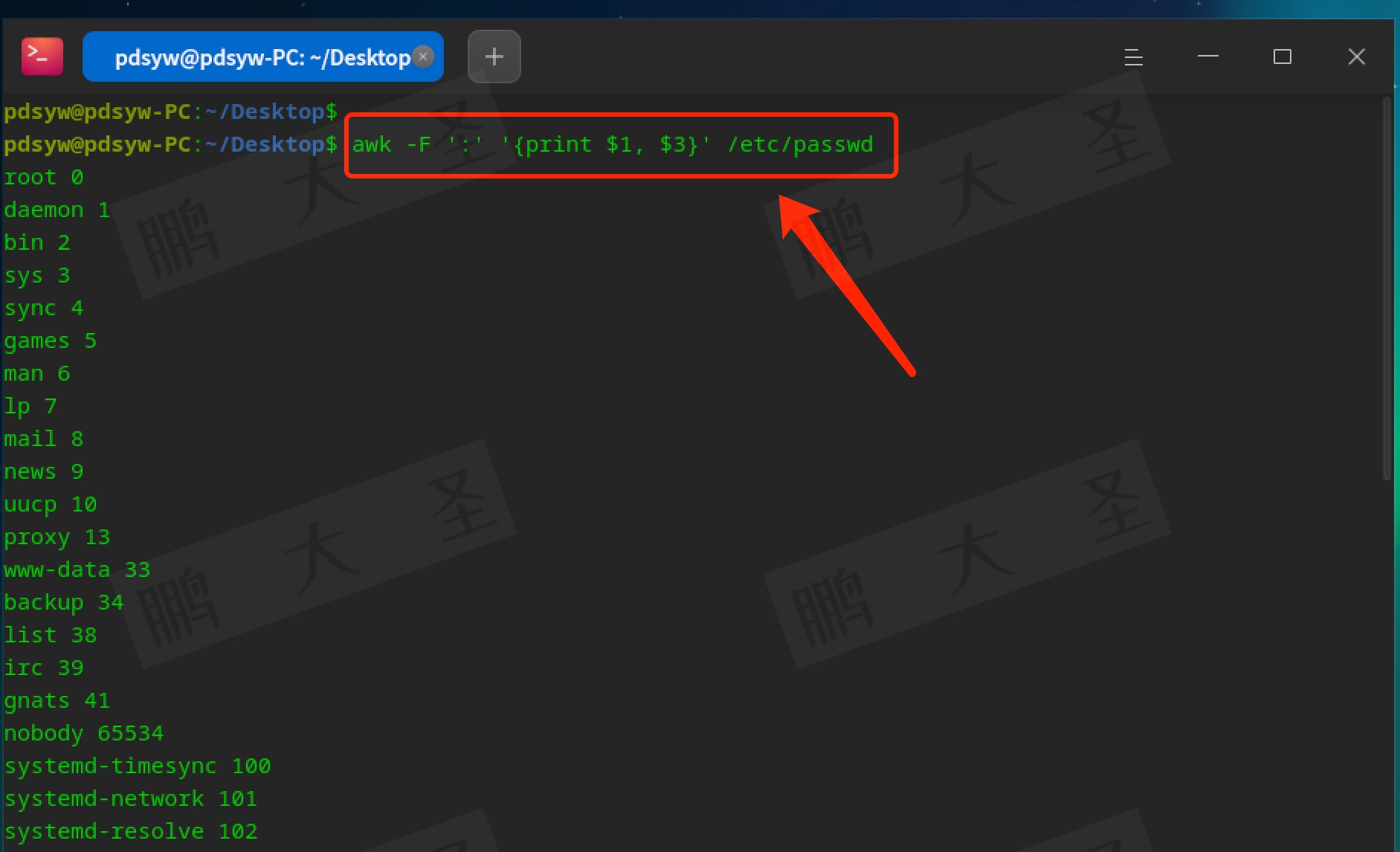
-F选项:指定输入分隔符
awk默认以空格或制表符为输入分隔符,假如我们要处理一份使用冒号(:)作为分隔符的文件,例如students.txt,内容如下:
```
1:Alice:85
2:Bob:78
3:Charlie:90
```
我们可以通过`-F`选项来设置分隔符:
```bash
awk -F: '{print $1, $2, $3}' students.txt
```
这将输出:
```
1 Alice 85
2 Bob 78
3 Charlie 90
```
-v选项:定义变量
若想在awk中定义变量,可以使用`-v`选项。例如,我们希望筛选分数大于80的学生。可以定义一个变量`threshold`来传递我们需要的分数。以下命令实现了这一目标:
```bash
awk -v threshold=80 '$3 > threshold {print $2, $3}' pdsyw.txt
```
这将输出所有分数大于80的学生姓名和分数,简洁又高效。
五、条件判断
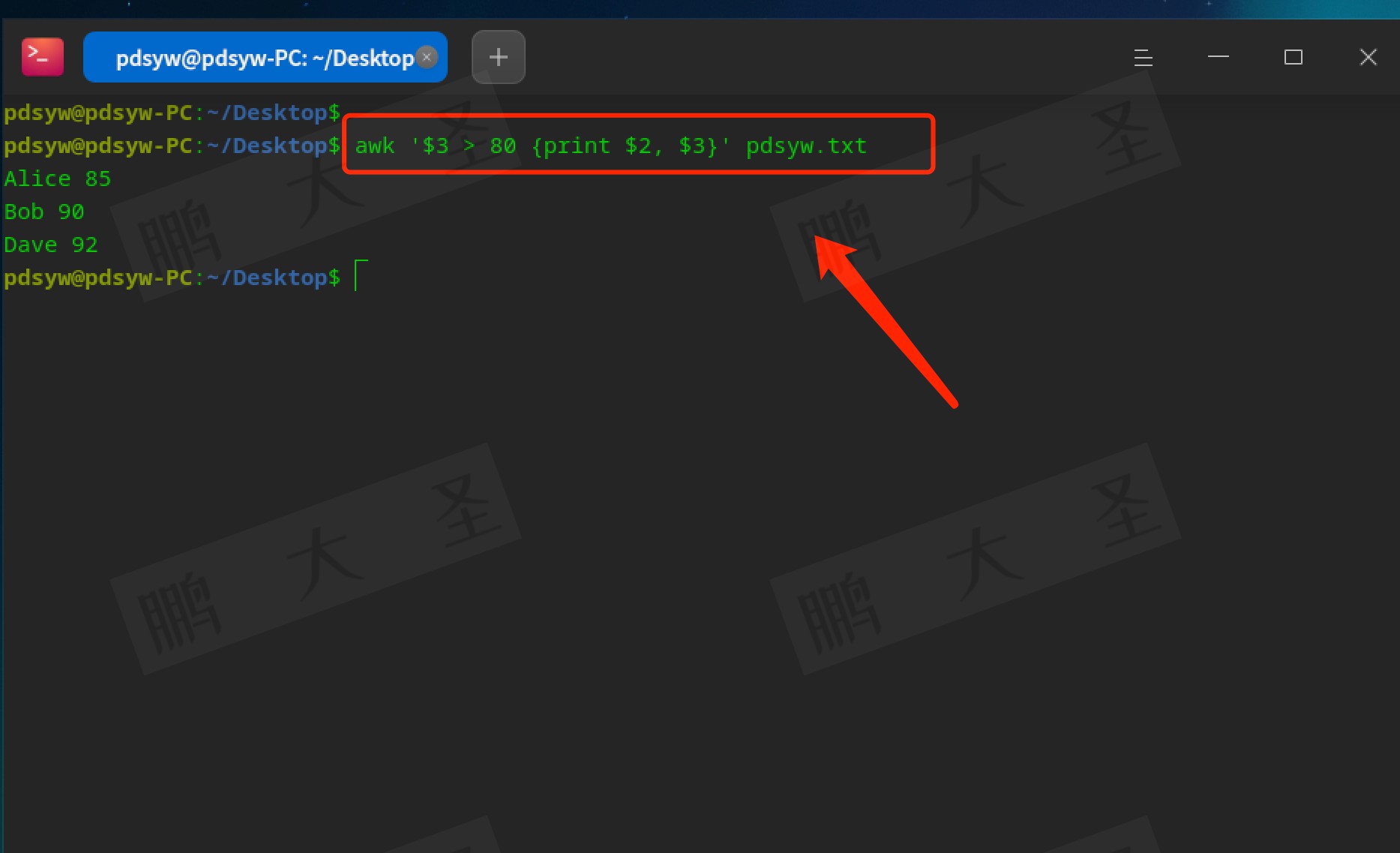
基于数值的条件
awk支持多种条件判断,最常用的就是基于数值的判断。比如我们想筛选出分数大于80的学生,只需使用以下命令:

```bash
awk '$3 > 80 {print $2, $3}' pdsyw.txt
```
结果会是:
```
Alice 85
Charlie 90
Eve 92
```
在实际应用中,数据量往往庞大,能迅速筛选出我们关心的数据,能够极大提高工作效率。
基于字符串的条件
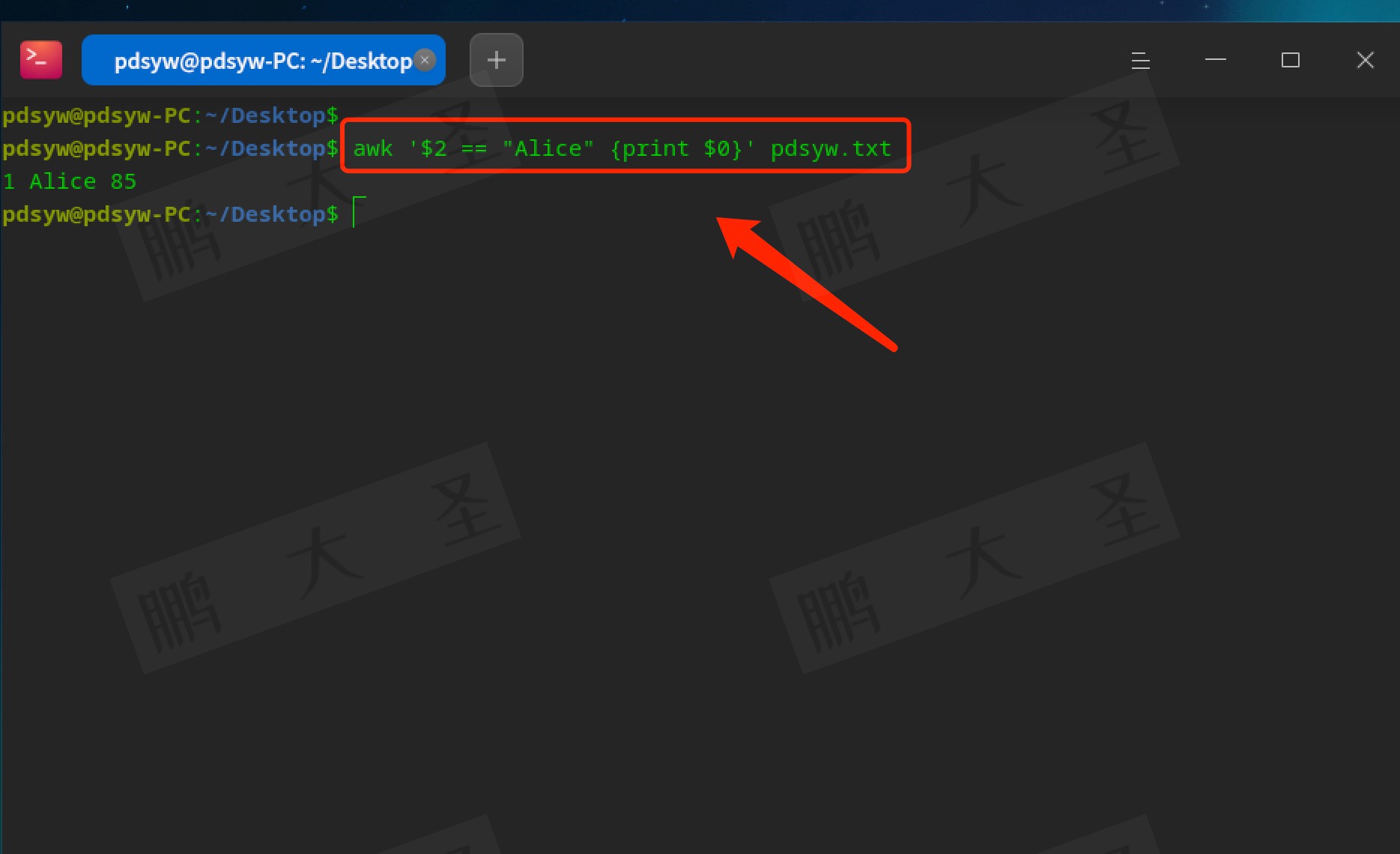
除了对数字进行判断,awk同样也支持对字符串的比较。如果我们想要筛选出名字为“Bob”的学生,可以这么写:
```bash
awk '$2 == "Bob" {print $0}' pdsyw.txt
```
这会误输出Bob的整行内容,非常方便。
使用逻辑操作符
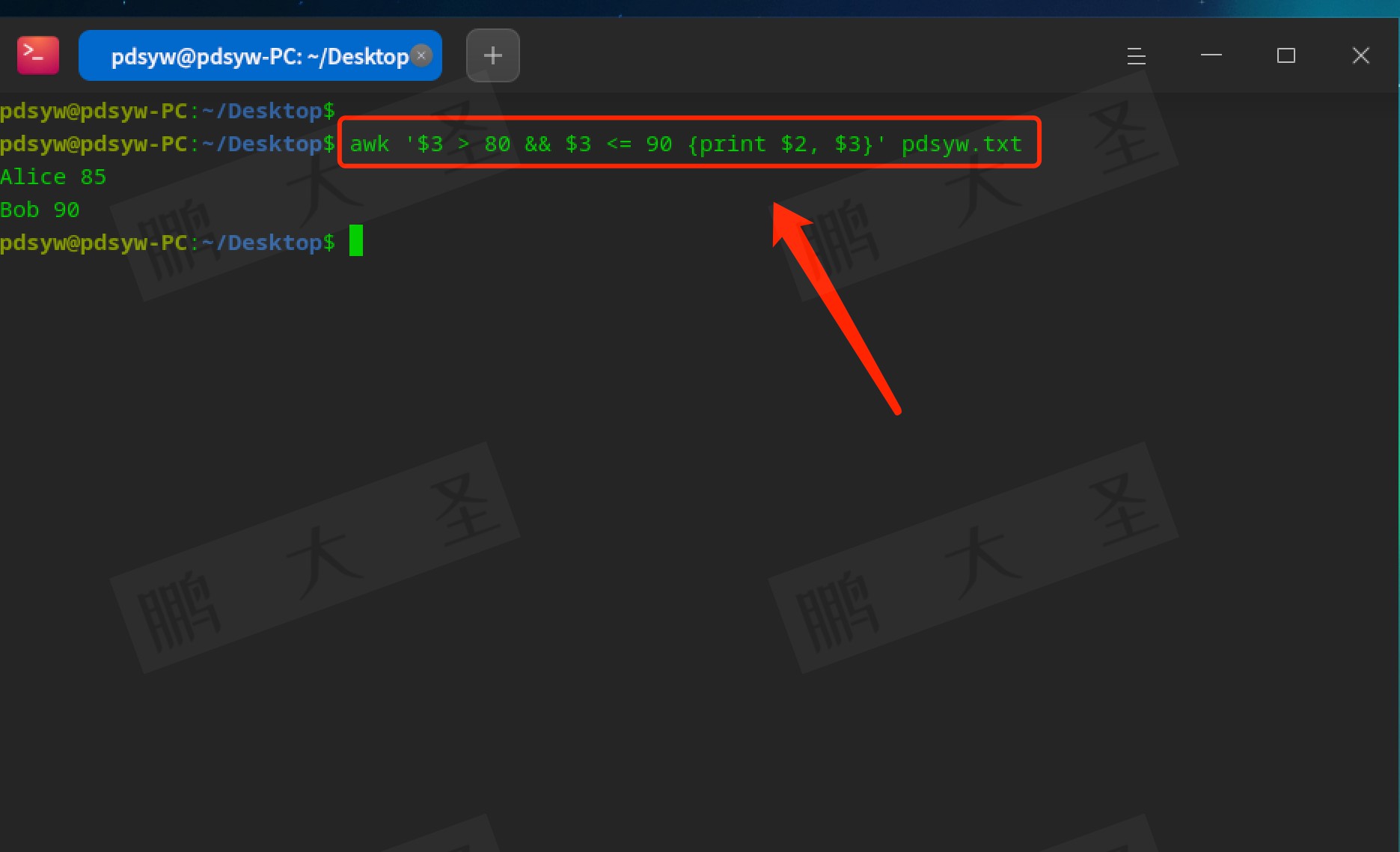
在复杂的数据筛选中,逻辑操作符是必不可少的。你可以使用`&&`(与)和`||`(或)进行多条件判断。例如,要查找分数大于80且小于90的学生信息,可以用如下命令:
```bash
awk '$3 > 80 && $3 < 90 {print $2, $3}' pdsyw.txt
```

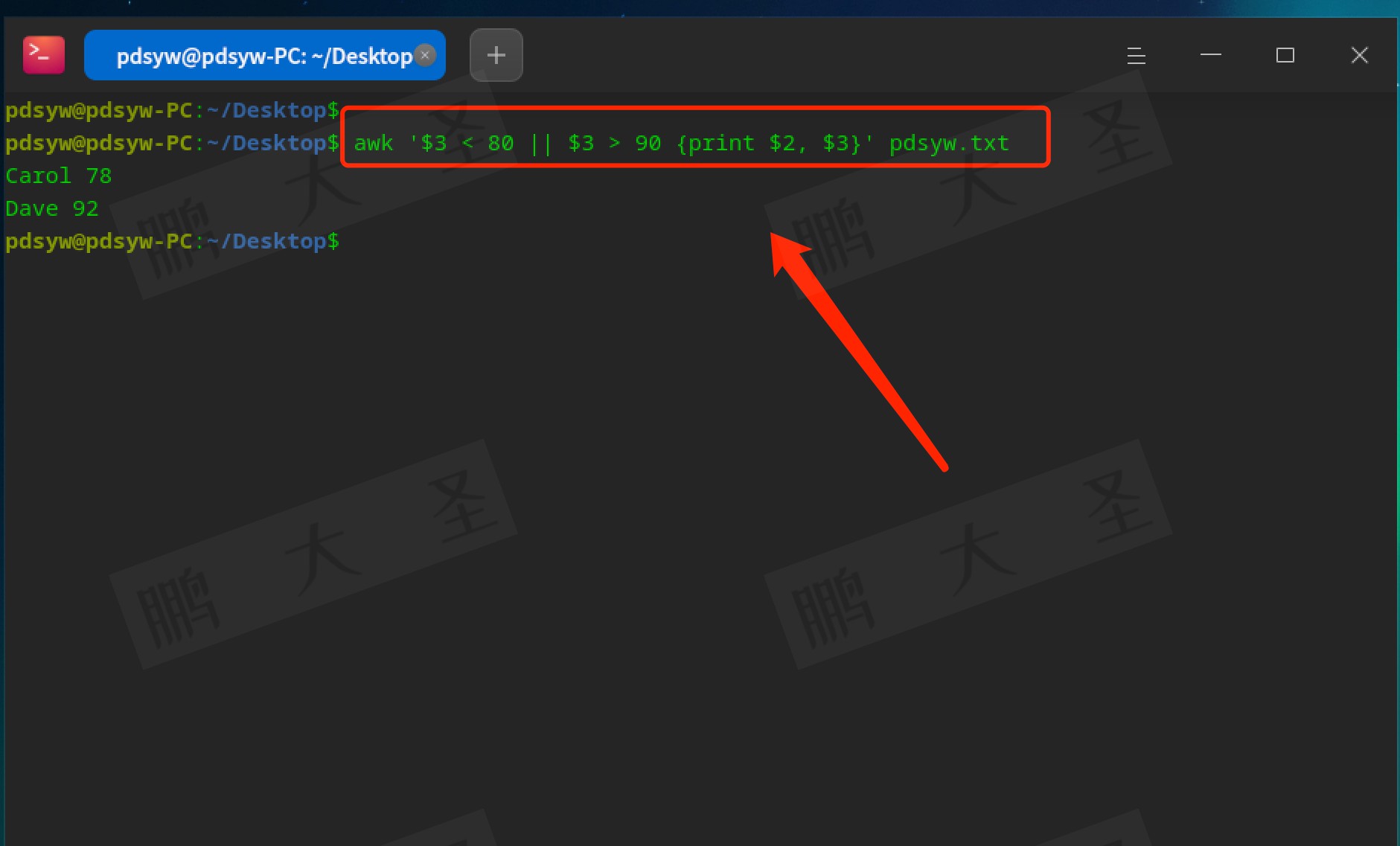
如果你想找出分数小于80或大于90的学生,就可以这样写:
```bash
awk '$3 < 80 || $3 > 90 {print $2, $3}' pdsyw.txt
```
这一逻辑的灵活性使得awk在数据处理时十分强大。
六、内置变量
介绍awk的内置变量特性
awk自带了一些非常实用的内置变量,例如`NR`和`NF`。`NR`代表当前读取的行数,而`NF`代表当前行的字段数。这些变量可以帮助我们在处理数据时进行更精细的控制。
应用示例
假设我们在分析一个成绩单的文件,并希望了解文件的总行数和每行的字段数,我们可以使用以下命令:
```bash
awk '{print "第" NR "行字段个数为:" NF}' pdsyw.txt
```
这将输出如:
```
第1行字段个数为:3
第2行字段个数为:3
第3行字段个数为:3
第4行字段个数为:3
第5行字段个数为:3
```
通过内置变量,我们可以进一步分析数据,提高屏幕输出的信息性。
七、awk的高级应用
结合其他命令
awk的强大不仅限于自身,它可以与许多Linux命令结合使用。例如,我们可以将awk与grep结合,先过滤出包含特定关键词的行,再用awk提取需要的内容:
```bash
grep "Alice" pdsyw.txt | awk '{print $2, $3}'
```
这一条命令组合极大地提高了数据处理的效率。
实际案例分析
假如你是一名IT运维工程师,负责分析服务器的日志文件。通过逐行分析、过滤和处理文档,你能迅速找到异常请求或失败的登录尝试,从而及时进行排查和修复工作。以下是一段可能的log文件示例:
```
2023-10-01 10:00:01 Login success: user1
2023-10-01 10:10:02 Login failed: user2
2023-10-01 10:10:05 Login success: user3
```
如果想要获取所有登录失败的记录,可以使用下面的命令:
```bash
awk '/Login failed/ {print $0}' logfile.txt
```
这一过程的快速性和高效性对于IT运维人员来说至关重要。
八、总结
上面我们探讨了awk的各个基本和高级组成部分,通过实际案例来帮助理解其应用。它使得数据的处理变得轻而易举,任何人都能迅速掌握。无论你是数据分析师还是系统管理员,学会使用awk,都将使你的工作事半功倍。
欢迎大家在下方留言讨论,分享您的看法!如果你有关于awk的使用经验或是心得体会,特别是如何在实际工作中高效利用awk的节目,绝对欢迎你分享哦!