
监督学习入门!掌握数据驱动的预测艺术!
探索监督学习的奥秘:从理论到实践
在数字时代的浪潮中,机器学习如同一颗璀璨的明珠,不断引领着技术革新的潮流。而在这其中,监督学习以其独特的魅力,成为了众多技术人士争相探索的热点。那么,什么是监督学习呢?简单来说,监督学习就是一种在教师的指导下,从数据中学习模式的技术。通过为教师提供一组已知的输入输出对,算法能够学习到如何根据输入预测出相应的输出。今天,我们就来一起深入探索监督学习的奥秘,从理论到实践,为你揭示其背后的精髓。
一、监督学习的基本概念

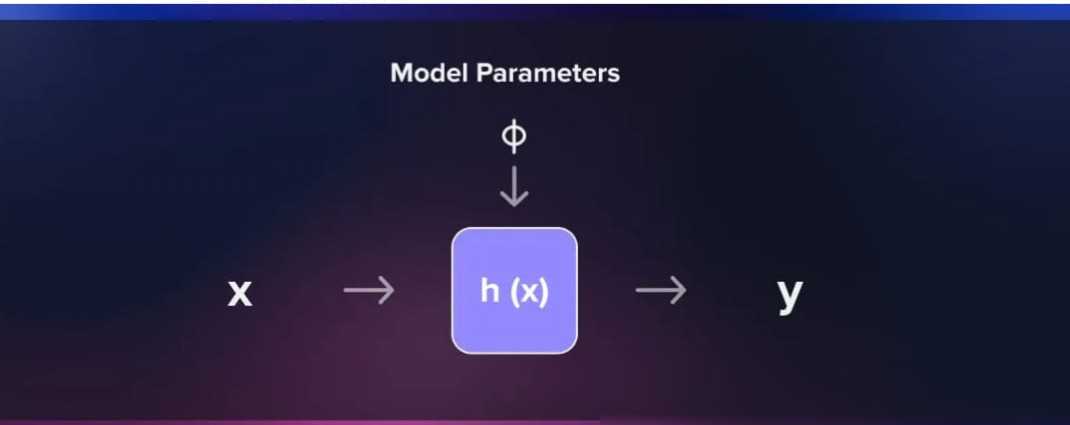
在监督学习中,我们有一个明确的目标:通过已知的输入输出对来训练一个模型,使得该模型能够对新的输入数据进行准确的预测。这个过程中,教师提供的已知输入输出对被称为“训练数据”,而模型则是我们需要构建的关键部分。模型是一个能够将输入特征映射到输出标签的数学表示,它定义了算法在其中搜索最佳拟合函数的假设空间。
举个例子来说,假设我们想要训练一个能够识别手写数字的模型。在这个场景中,输入是一张包含手写数字的图片,而输出则是这个数字对应的标签(0-9)。我们首先需要准备一个包含大量手写数字图片和对应标签的训练数据集。然后,我们使用这个数据集来训练一个神经网络模型。在训练过程中,模型会不断调整其内部参数,以最小化其预测结果与真实标签之间的差异。最终,当模型在训练数据上的表现达到预期时,我们就可以将其应用于新的手写数字图片,进行准确的预测。
二、监督学习的关键组件
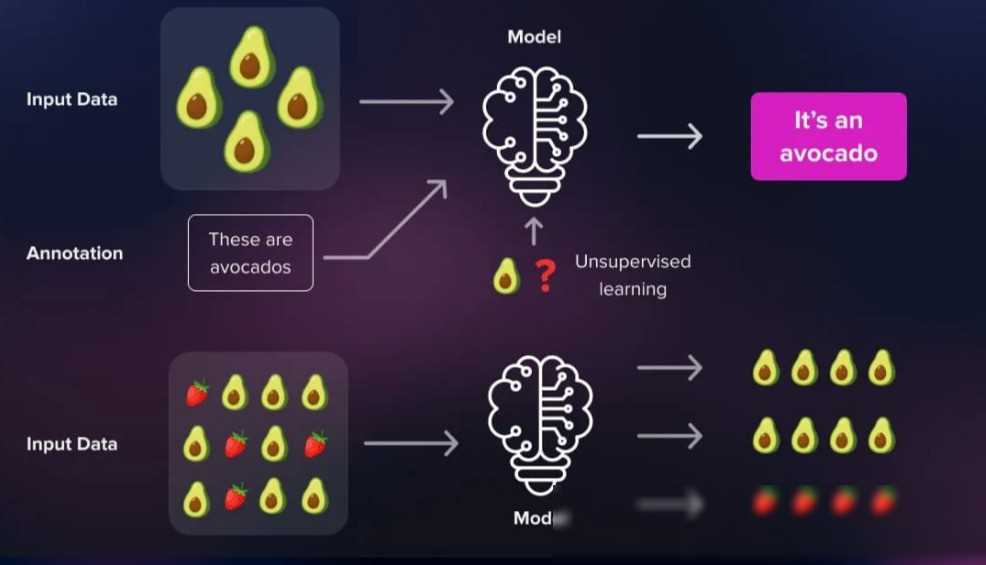
监督学习之所以能够取得如此显著的成果,离不开其背后的几个关键组件:训练数据、模型架构、损失函数和优化算法。下面,我们就来逐一介绍这些组件。
训练数据
训练数据是监督学习的基石。一个高质量的训练数据集能够极大地提升模型的性能。在准备训练数据时,我们需要关注数据的数量、质量和多样性。数量方面,足够多的数据能够覆盖更多的情况,提高模型的泛化能力;质量方面,数据需要准确无误地反映真实情况,避免引入噪声和错误;多样性方面,数据需要涵盖各种可能的情况,以应对各种复杂场景。
以图像分类任务为例,如果我们想要训练一个能够识别不同种类水果的模型,就需要准备一个包含各种水果图片和对应标签的训练数据集。这个数据集需要包含各种颜色、形状、大小、光照条件下的水果图片,以确保模型能够应对各种复杂场景。
模型架构
模型架构是监督学习的另一个重要组件。它定义了输入特征和输出标签之间的数学关系,并决定了算法在其中搜索最佳拟合函数的假设空间。不同的任务需要不同的模型架构来应对。例如,在图像分类任务中,卷积神经网络(CNN)由于其独特的卷积层和池化层结构,能够很好地提取图像中的局部特征;而在自然语言处理任务中,循环神经网络(RNN)和长短时记忆网络(LSTM)则能够更好地处理序列数据中的依赖关系。
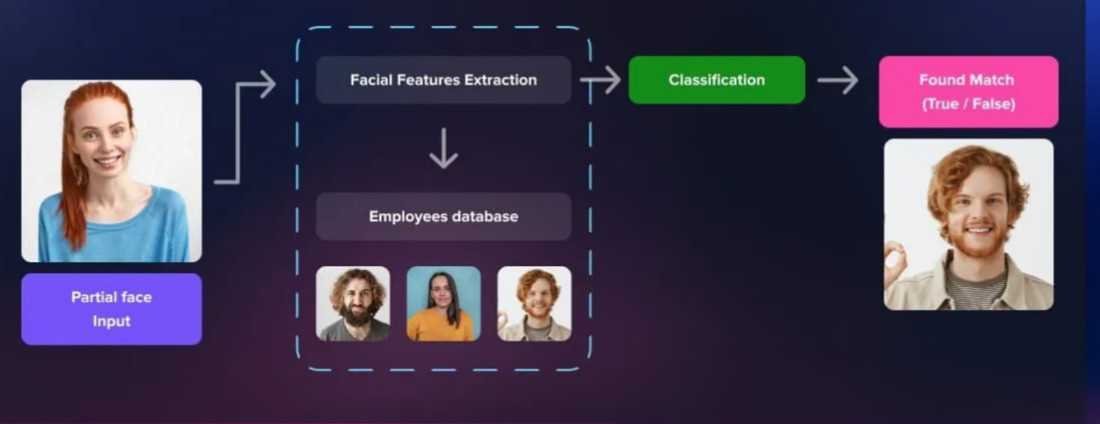
在选择模型架构时,我们需要根据任务的特点和需求来做出决策。我们也需要关注模型的复杂度和计算资源的需求。过于复杂的模型可能会导致过拟合和计算效率低下的问题;而过于简单的模型则可能无法充分学习数据的特征。
损失函数
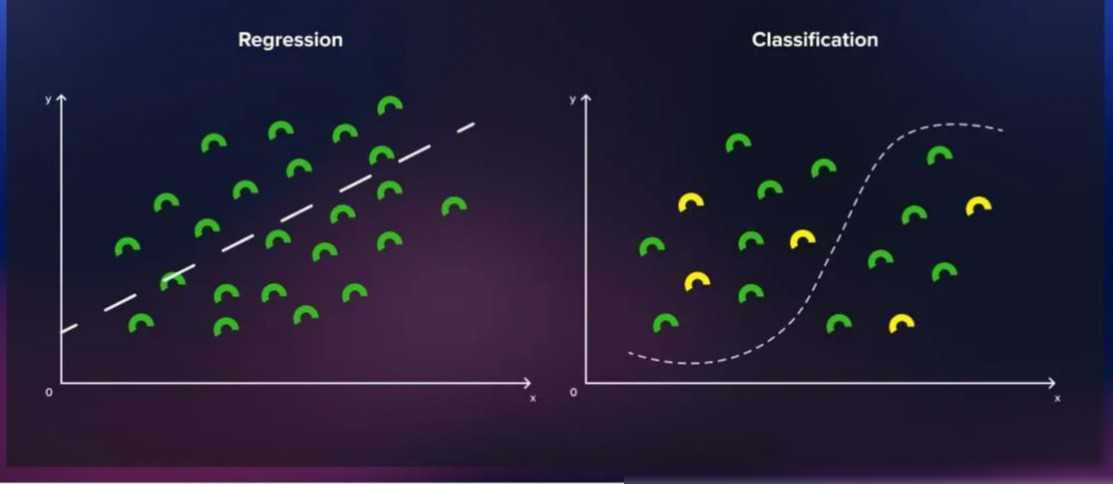
损失函数是量化预测输出和实际输出标签之间误差的关键组件。在训练过程中,我们的目标是不断减少这种误差,使得模型的预测结果越来越接近真实标签。常见的损失函数包括均方误差(MSE)和交叉熵损失等。不同的任务需要选择不同的损失函数来应对。例如,在回归任务中,我们通常使用均方误差来衡量预测值和真实值之间的差异;而在分类任务中,我们则使用交叉熵损失来衡量预测概率分布和真实概率分布之间的差异。
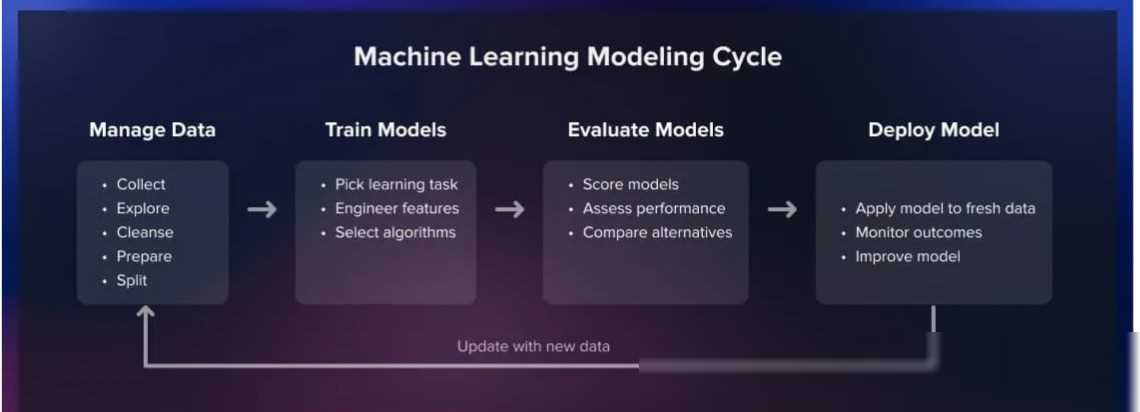
选择合适的损失函数对于模型的训练效果至关重要。一个合适的损失函数能够引导模型在训练过程中找到最佳拟合函数;而一个不合适的损失函数则可能导致模型陷入局部最优解或无法收敛。
优化算法
优化算法是监督学习中用于调整模型参数以最小化损失函数的方法。常见的优化算法包括梯度下降、随机梯度下降、动量法等。这些算法通过迭代地更新模型参数来逐渐减小损失函数的值,从而优化模型的性能。
在选择优化算法时,我们需要考虑算法的收敛速度、稳定性和计算复杂度等因素。不同的优化算法适用于不同的任务和数据集。例如,在大规模数据集上训练深度神经网络时,我们通常使用随机梯度下降算法来加速训练过程;而在处理非凸优化问题时,我们则可能需要使用动量法或Adam等自适应学习率算法来避免陷入局部最优解。
三、监督学习的实践应用
监督学习在现实生活中的应用非常广泛。从图像识别、语音识别到自然语言处理、推荐系统等领域,都有着监督学习的身影。下面,我们就来介绍几个典型的实践应用案例。
图像识别
图像识别是监督