向量数据库的秘密:如何优化你的AI应用?
向量数据库的秘密:如何优化你的AI应用?
亲爱的读者朋友们,今天我们将深入探讨向量数据库的架构设计与实现,揭示其在AI领域的重要性和优化方法。在数据爆炸式增长的今天,如何有效地处理和高效检索大规模高维数据,是一个亟待解决的问题。如果你对如何提升自己的AI应用感兴趣,那么接下来就请随我一起走进这个充满挑战与机遇的领域吧!
一、向量数据库背景介绍
1.1 什么是向量数据
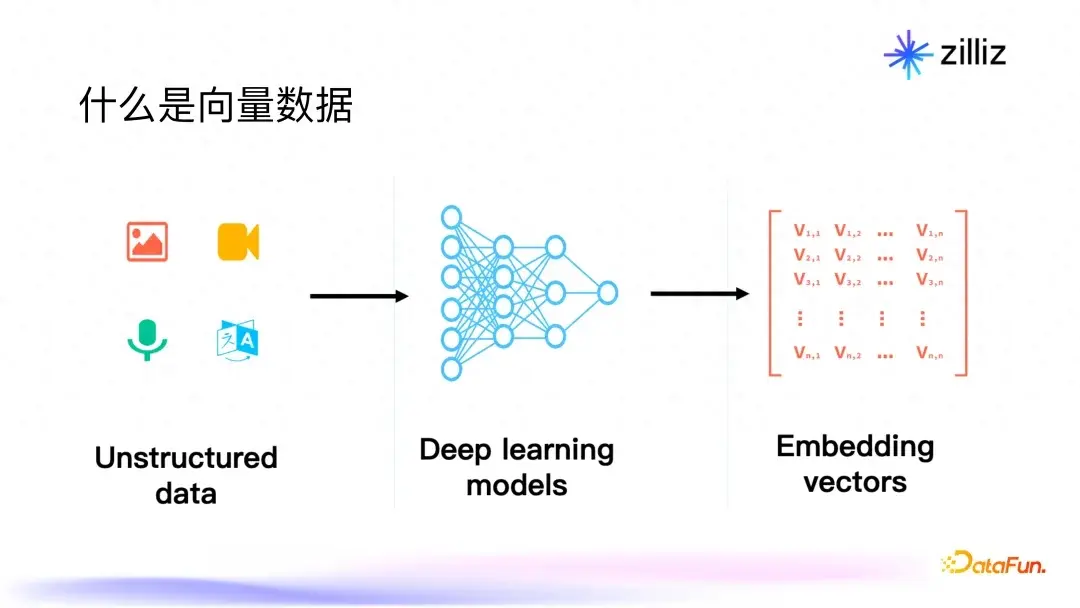
在当今技术背景下,非结构化数据如图片、视频、语音、文本等无处不在。传统的数据库在面对这些数据时显得力不从心。所谓向量数据,就是通过各种模型将这些非结构化数据转化为高维向量,以便于模型进行理解和推理。例如,图像识别中,我们可以使用卷积神经网络(CNN)将图片转化为向量。在这方面,深度学习的出现无疑是一个重大突破。您可能会好奇,这种转化对模型的训练和推理有什么影响。通过向量化,模型可以以更高的维度进行数学计算,因此能够捕捉到数据之间更精细的关系。
1.2 什么是向量检索
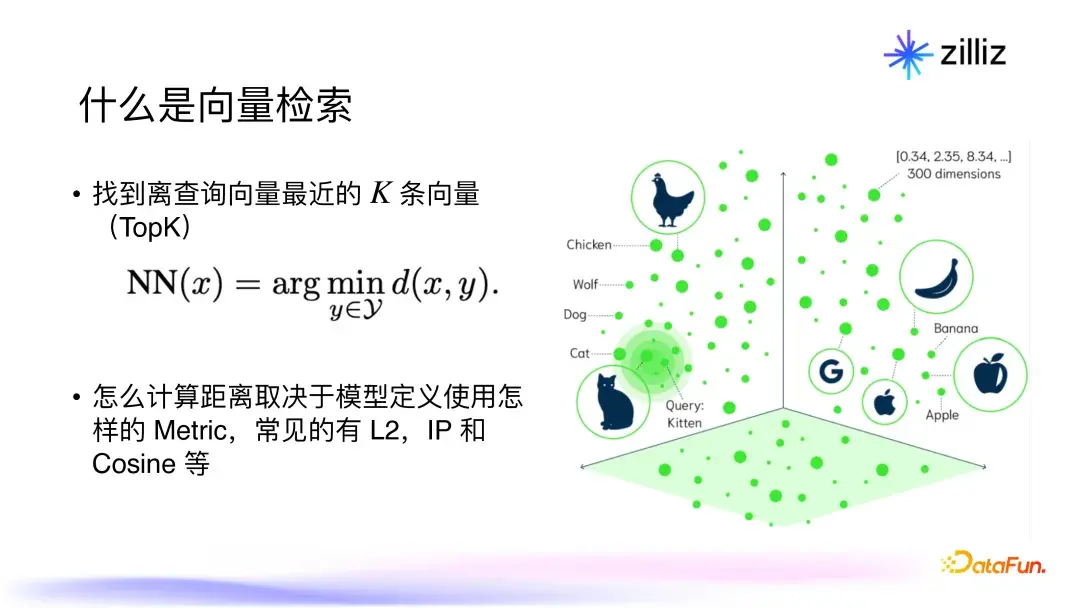
向量检索是一种检索机制,简单来说,它就是在给定场景向量的情况下,找到与其最接近的其他向量,这个过程通常被称为KN查询(k-nearest neighbors)。计算过程中,常见的数学度量方式包括欧几里得距离(L2)、内积(IP)和余弦相似度(Cosine)。例如,在搜索“最热门的旅行地”这个场景时,系统会通过向量检索技术快速找到与之相关的历史数据,从而为用户提供个性化推荐。
1.3 什么是向量数据库
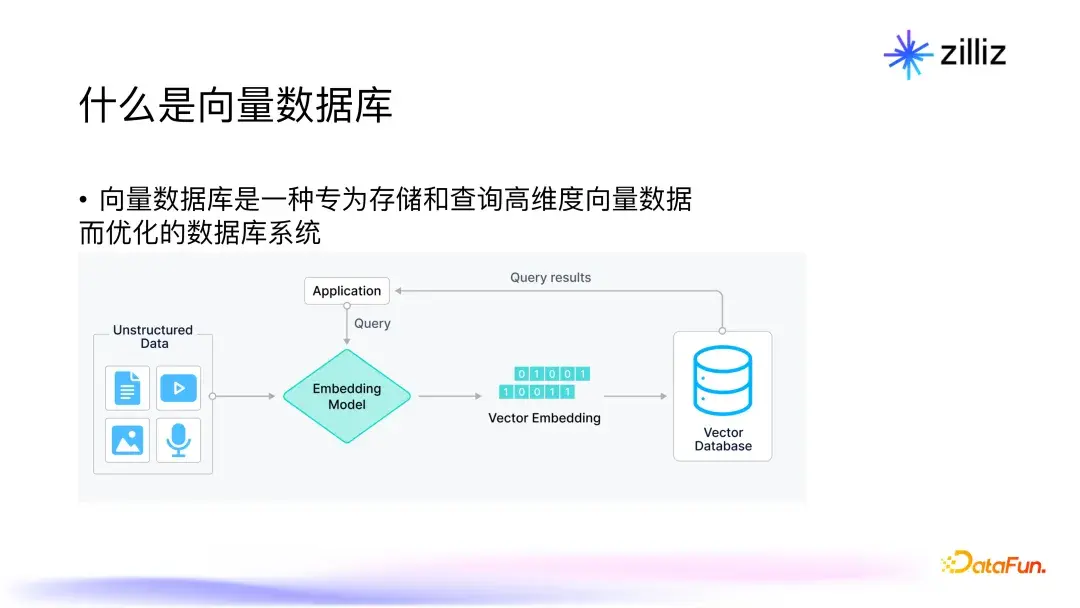
向量数据库是专门为存储和查询高维向量数据而优化的数据库。它与传统的关系型数据库、图数据库或时空数据库有所不同,主要体现在对高维数据的管理能力上。通过对高维数据进行索引优化,向量数据库可以大幅提高检索速度与精确度。例如,Milvus作为一个开源向量数据库,能够支持数十亿级别的向量数据查询。
1.4 为什么需要向量数据库
随着大模型技术的快速发展,向量数据库的需求日益增大。在推荐系统中,向量数据库可以帮助分析用户行为,提供更加符合需求的产品体验。例如,在电商平台上,用户的浏览历史、购买记录等都可以被转化为向量存储在数据库中,当用户进入页面时,系统能够快速计算出与其历史行为相关的商品,为其提供个性化推荐。礁石与海浪间的摩擦,让向量数据库成为了连接用户与内容的桥梁。
1.5 什么是好的向量数据库

评估一个向量数据库的优劣,主要从几个方面来进行考量:性能、扩展性、易用性、功能、可观测性、生态集成、故障恢复和安全性。高性能的数据库可以在短时间内处理大量数据,无论是插入、查询还是删除,都能够保持高效的响应速度。此外,良好的扩展性能够让数据库支持业务的不断增长,而易用性则确保开发者和用户在使用过程中不会感到阻碍。
二、Milvus整体架构设计
2.1 云原生的分布式向量数据库
Milvus作为一款高效的分布式向量数据库,其架构设计非常注重可扩展性和资源的有效利用。Milvus的系统框架中有四个关键角色——proxy、data node、index node和query node。Proxy作为接入层,主要负责请求的检查和路由功能。当数据**入时,信息首先通过proxy进入消息队列,被data node消费并转化为持久化数据放到对象存储中。为了不影响查询性能,索引的构建由index node负责。这一设计不仅可以有效隔离数据插入和查询过程,提升系统性能,还能支持快速扩展。例如,在业务量增加时,可以轻松添加更多的query node以提升查询能力。
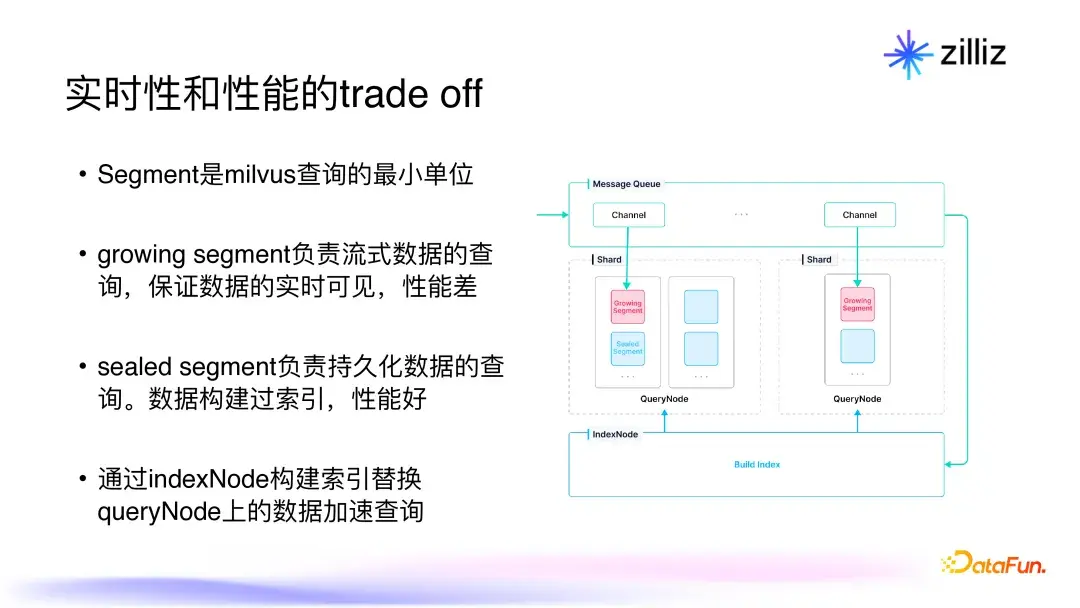
2.2 实时性和性能的trade off
在Milvus中,Segment是查询的最小单位,分为growing segment和sealed segment。Growing segment保证了数据的实时可见,但其性能相对较差,而sealed segment则提升了查询性能。通过动态管理这两种segment,Milvus实现了实时性与性能之间的平衡。比如,当用户插入数据时,新的数据会进入growing segment,而经过一段时间后,数据会被转移至sealed segment以提高查询效率。这种设计同时保障了用户在数据频繁变动时,依然能获得高效的搜索体验。
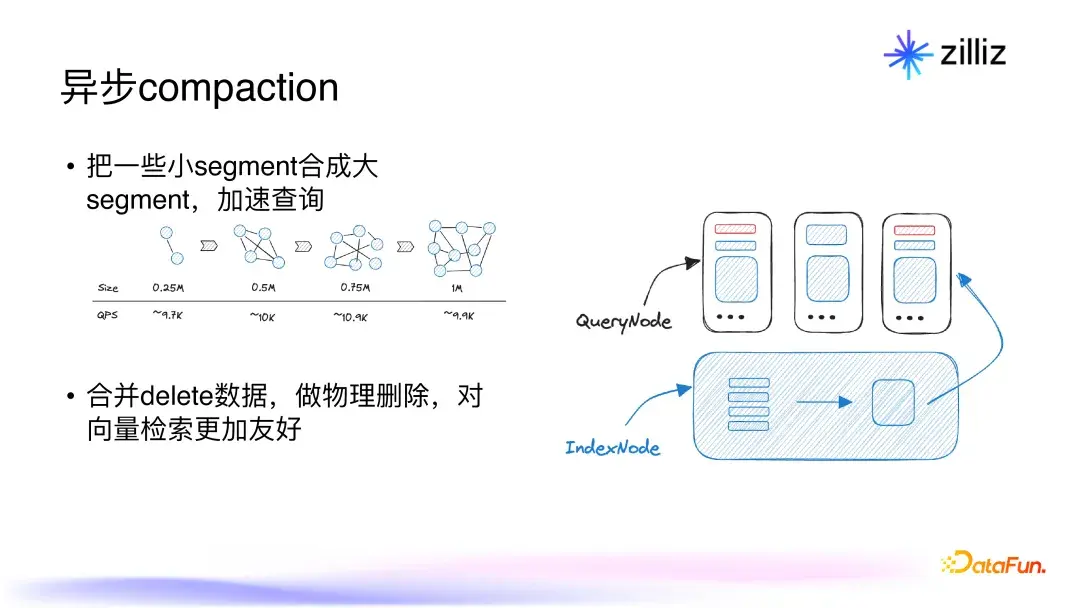
2.3 异步compaction
为了进一步提高查询性能,Milvus采用了异步compaction技术,将多个小segment合并为更大的segment。合并操作不仅可以提高查询效率,还能有效释放存储资源。举个例子,如果向量索引的大小随着数据量的增大而增长,但性能提升却比较有限,那么通过将4个小segment合并成1个大segment,可以显著减少查询所需的时间。这种物理删除的合并方式能让查询过程更加流畅有效,使得用户在得到查询结果时,更加满意。
2.4 批量写入
在实际应用中,用户对数据的实时性需求因场景而异。在数据更新频率较低的情况下,Milvus支持批量写入模式。这种模式允许用户直接将数据批量写入对象存储,跳过了消息队列的限制,提升了数据加载的速度。此外,与Spark等数据处理工具的结合也为数据的导入提供了极大的便利。例如,在大规模的数据迁移中,通过Spark connector能迅速将外部数据源的数据导入Milvus,大幅降低了实施成本。
2.5 全局索引
全局索引的设计使得在查询过程中,系统可以访问所有segment并进行合并处理,从而得到最终结果。如果提前知道数据的分布情况,可以有效减少segment的访问次数。例如,根据不同租户划分数据的场景,可以让查询时只针对特定租户的数据段进行数据检索,大幅提高数据库的效率。此外,标量过滤条件的引入,允许用户在查询时对数据进行针对性的裁剪,进一步提升检索速度。
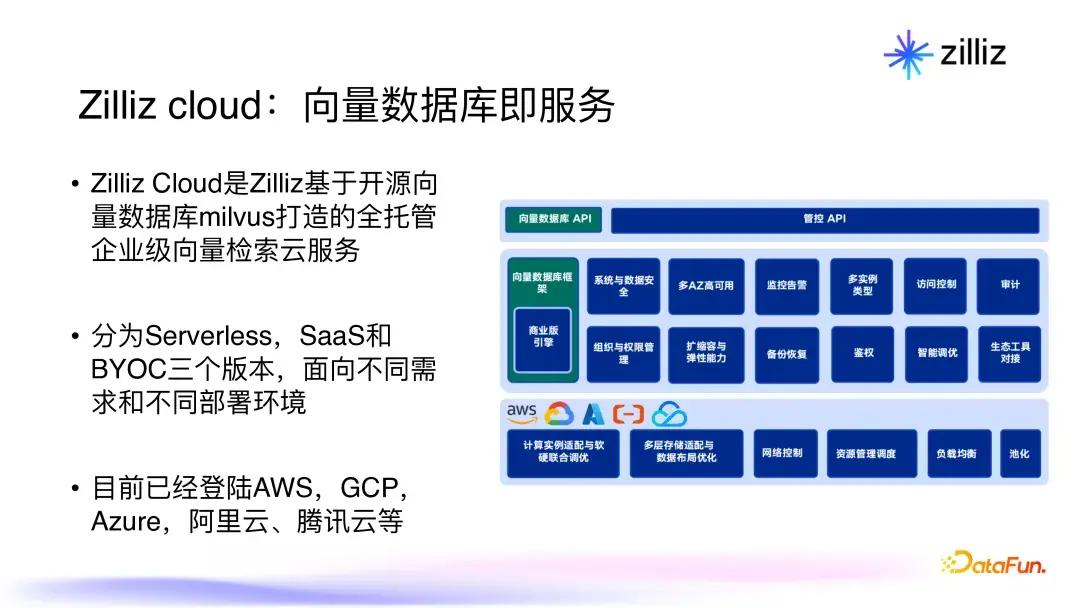
2.6 Zilliz cloud:向量数据库

Zilliz cloud是基于Milvus构建的全托管云服务平台,它结合社区的力量,为用户提供了一个更加稳定、高效的向量数据库服务。在确保高可用性和安全性的基础上,Zilliz cloud还支持监控报警、备份恢复等功能,为用户提供了一整套容易操作的云数据库服务。这种服务方式对于中小型企业特别友好,帮助他们降低基础设施成本,同时又能享受强大的数据管理能力。此外,Zilliz cloud的serverless版本更是为用户提供了低成本的使用方案,让更多人能够轻松接触并应用向量数据库。
三、性能的关键-索引
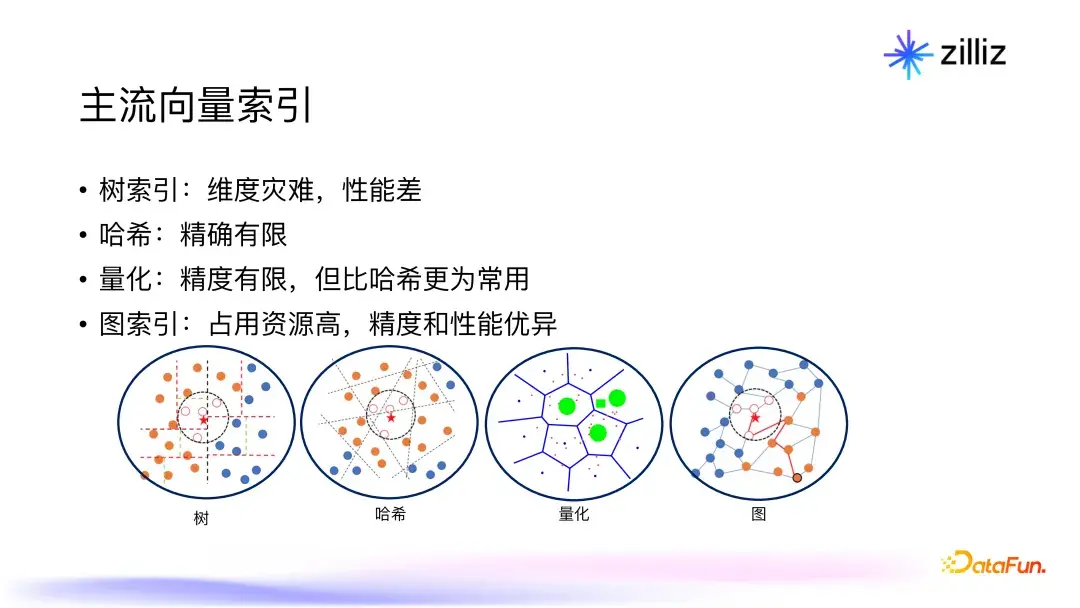
3.1 主流向量索引介绍
在向量数据库中,索引的选择对系统性能有着至关重要的影响。常见的向量索引主要包括以下几种:FLAT,即暴力搜索,通过遍历所有数据实现100%的准确性,但在数据量较大时效率低下;IVF(Invertible File Index),通过数据聚类分成多个桶,可以有效减少搜索范围;Product quantization是一种通过压缩手段降低内存占用的索引方法;HNSW(Hierarchical Navigable **all World)索引,利用近邻连接关系进行高效导航的图索引;DiskANN,将图索引通过磁盘进行优化,实现低内存占用的高效搜索。这些索引各有优劣,因此选用合适的索引对提升性能至关重要。
3.2 如何选择最合适的索引
选择适合自身需求的向量索引,需要在cost、accuracy、performance三个维度上做出权衡。您可能会问,如何衡量这些指标呢?在实际应用中,CPU、GPU、内存资源的使用和数据的处理速度都会影响整体性能。因此,应当基于实际的场景需求来选择合适的索引类型。例如,如果您的应用对性能要求极高而容忍一定的误差,那么HNSW或Product quantization可能是较好的选择。而对于数据量较少的应用场景,使用FLAT索引可能更具优势,因其提供100%的搜索准确性。
3.3 Zilliz cloud商业版索引引擎-cardinal
Cardinal是Zilliz cloud中的一款商业版索引引擎,旨在为用户提供更优质的服务。它通过更高效的数据结构和C++模板的使用,大幅提升了代码执行效率。此外,Cardinal采用了智能参数学习机制,将向量索引的精度和性能间的调优简化到极致。大幅优化的数据存储布局,也使得在内存和磁盘访问方面达到了更高的效果。这种极致的性能优化,使得Cardinal在面对高频查询时表现更加优异,帮助企业有效降低了成本和提升了效率。
四、面向AI持续优化
4.1 Filter search
在向量检索中,引入标量过滤条件已经成为一种趋势。例如,当用户在搜索特定类别的图片时,可能会希望添加额外的约束,如“品牌”或“颜色”。Milvus通过支持多种标量索引,极大地提升了这种过滤的效率,并且通过向量侧与标量分布融合的索引加速了检索过程。这种优化在实际应用中,不仅提升了检索的速度,用户体验也得到了显著改善,使得应用程序在复杂查询时能保持高响应。
4.2 Sparse vector
在某些情况下,使用稀疏向量(sparse vector)可能更具优势,特别是当涉及到关键字匹配的场景时。稀疏向量可以通过查找关键词来获取相关内容,提供了更强的可解释性。例如,在文本检索中,用户输入关键词可以快速找到相关文档,使得过程更加直观。而传统的密集向量(dense vector)在面对不相关数据时的泛化能力则容易受到限制,导致检索效果不佳。
4.3 Hybrid search
随着数据种类与形式的不断丰富,Milvus支持多向量多模态存储及检索能力,也因此提升了检索效果的多样性。这种混合检索(Hybrid search)方法,通过结合多种信息维度,可以从更广泛的视角进行信息检索。例如,结合文本和图片的内容,能够为用户提供复杂的搜索结果,进而实现多重排序,¿让用户获得期待的结果。混合搜索的优势在于,它为用户打开了多维度的信息获取渠道,让检索变得更加灵活和准确。
4.4 Grouping search
在一些高级检索场景中,单纯依赖向量维度的召回不可避免地造成信息的碎片化,用户可能找不到集中的结果。Grouped search的出现就是为了解决这一问题。当用户希望从某个文档中召回信息时,他们更期待的往往是整体内容的聚合结果而非单个片段。例如,若一个文档被切分为若干个chunk,适当的聚合和重组能够更好地满足用户的需求。这种能力让数据访问变得更直观、高效。
4.5 更加易用
在未来的追求中,向量数据库的易用性将成为其核心竞争力。用户希望能直接导入非结构化数据,如文本或图像,而不必为数据转化过程而烦恼。为了实现这一目标,Milvus计划增加第三方模型调用的能力,让用户可直接通过简单的接口,将数据转换为向量。这一创新无疑将大幅降低用户的学习成本,为更多的应用场景提供便利。
五、问答环节
5.1 问题与回答
听众提出了多项有趣的问题,针对图索引的实时更新,专家指出虽然HNW(Hierarchical Navigable **all World)能够支持实时更新,但其插入性能仍需进一步提升。在面向大模型的任务时,学术界和工业界都在积极探索智能参数学习等技术方向,以适应向量数据库领域不断变化的需求。在考虑到关于grouping search的工作时,专家透露已经支持这一功能,并期待未来能开发出更多聚合查询的方式。
---
欢迎大家在下方留言讨论,分享您的看法!你对向量数据库还有什么想要了解的内容吗?