
大数据时代,如何用RAG技术解决文档难题?
大数据时代,如何用RAG技术解决文档难题?

亲爱的读者朋友们,面对日益庞大的文档量,如何高效获取所需信息成为了一个令人头疼的问题。尤其是在技术领域,快速解答用户的问题,避免技术支持的瓶颈,让我们发现了 RAG(Retrieval-Augmented Generation)技术的魅力。今天,我们将深入探讨 RAG 技术在大规模文档管理中的应用,帮助大家更好地理解这个前沿技术。

一、较大规模文档的业务挑战

1. 业务背景
PingCAP 作为一家专注于关系型数据库开发的公司,其产品 TiDB 和 TiDB Cloud 近年来得到了广泛的应用。然而,随着公司快速成长,文档数量也在不断增加。目前,PingCAP 已经积累了超过 2K 的英文文档和大量中文文档,总文档量更是达到了 15K。这些文档覆盖了数据库架构、故障排查、性能优化等各个方面,然而,正是这庞大的文档库,给普通用户带来了不小的挑战。
2. 用户认知难题
面对如此庞大的信息量,用户往往感到无从下手。阅读完所有文档几乎不可能,因此用户难以获得全盘的认知。为了应对这个挑战,PingCAP的团队意识到,必须把文档与用户之间的互动进行整合,让用户能在短时间内找到所需的信息,提升使用体验和效率。
3. 技术回答的延迟
随着用户规模的不断增长,用户对于技术支持的需求量呈现出几何级数的增长。而人力资源的有限性导致了技术支持的响应时间逐渐延长,用于处理常见问题的技术支持人员疲于奔命,用户等待答案的时间在增长,这无疑影响了用户满意度。尤其是在发展相对成熟的海外社区,技术答疑的延迟变得愈发明显。
4. 解决方案概述
为了解决文档难题,PingCAP 开发了基于文档的问答机器人,旨在实现自动化的文档查询和问题解答。该机器人通过 RAG 技术,能够迅速从海量文档中提取相关信息并作出准确回复。同时,在社区平台如 Slack、Discord 上直接 @ 机器人提问,不仅提高了问题解决的效率,也让用户体验得到了显著提升。
二、RAG 技术落地实践和演化过程
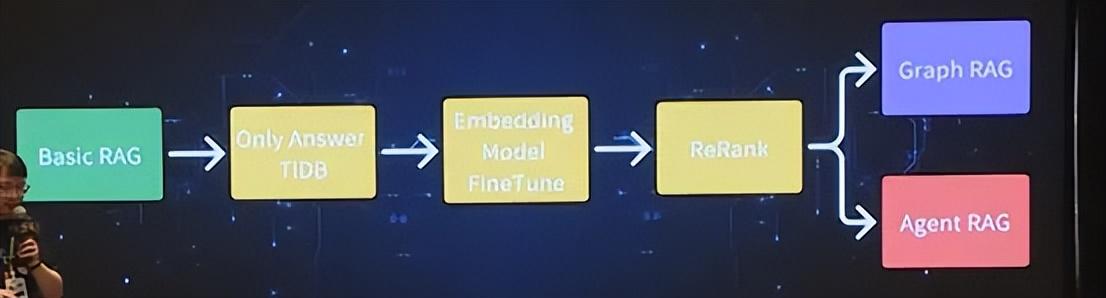
1. RAG 实践的四个阶段
RAG 的实践可被划分为四个阶段,每个阶段都针对文档的特性和用户需求进行了深入探讨和实践。
- Basic RAG:以基础的 RAG 模式为起点,强调多轮对话能力和用户问题理解。
- 应用优化:在初步实践中识别问题,进行系统优化。
- Graph RAG:探索图数据库在文档管理中的应用,增强文档之间的关联性。
- Agent RAG:使用智能体方法进行复杂问题的解答,提升系统的智能化水平。
2. Basic RAG
Basic RAG 依赖于大语言模型的多轮对话能力,旨在理解用户查询并提供准确答案。然而,初期的模型(如 OpenAI)常常会输出与 TiDB 无关的内容。为了提升工作效率,实际应用中需要对模型进行调优,引入不同的毒性检测技术来限制模型仅回答与 TiDB 相关的问题。
3. Only Answer TiDB
在小团队的背景下,自行训练大模型显得不切实际。因此,利用 RAG技术能够以更低的成本实现高效的信息检索。通过毒性检测技术识别与目标主题无关的问题,确保大语言模型只输出与 TiDB 相关内容,从而极大地提升了用户的满意度。
4. Embedding Model Finetune
应对多语言用户的需求,单一的模型无法满足不同语言文本的理解。为此,团队决定自行 finetune Embedding model,引入 GenQ 方法。通过对文档分块并生成问题对,使得模型的训练更加高效。同时,利用 MultipleNegativesRankingLoss 方法,确保正负样本的合理比例,从而提升模型在多语种信息检索中的准确性。
5. ReRank
提高用户反馈是优化 RAG 系统的关键。一旦产品上线,团队立即对用户反馈进行收集与分析。通过点赞和点踩机制,不仅能够识别问题的质量,还能实时调整模型输出。例如,最初用户的 dislike 率高达 34%,而经过几轮优化后,最终降低到 2%-3%。这样的转变证明了反馈机制的重要性。
6. Basic RAG 的业务挑战
尽管 RAG 方法具有一定优势,但其在实际应用中依然面临挑战。向量相似度并非在所有场景下都是最佳搜索方式。PingCAP 团队意识到,真正的需求是一个智能化程度更高的搜索引擎,而不仅仅是靠 RAG 技术。此外,结合图数据库等补充技术手段是必要的,以便于满足复杂的业务需求。
7. Graph RAG
PingCAP 开始探索 Graph RAG 的使用。微软发布的一篇论文为 Graph RAG 提供了理论指导,团队通过与微软和 LlamaIndex 的合作,构建知识图谱。通过对文档进行切分,将每个实体和相关信息建立关联,加深用户对知识的理解和检索的精准度。
8. Agent RAG 的业务挑战
在文档问答中,处理复杂的诊断问题是一项难题。为了从根本上解决这一问题,团队采用 Agent RAG 的方式,构建多角色系统。通过将专门的 Agent 设计为 Planner、Engineer & Executor、Critic,各自负责不同的任务,使得系统在解决复杂问题时更加高效且可靠。
三、前沿介绍

1. RAG 生态图
随着 RAG 技术的不断发展,目前已经形成了一个相对完善的生态系统。该生态系统不仅包括各类 RAG 实施方法,还涵盖了众多行业的最佳案例,为各公司提供了宝贵的经验和实用的参考。在这个体系中,评估系统发挥着至关重要的作用,团队需要不断关注系统的优化和性能提升。
通过这些探索,PingCAP 的 RAG 实践不仅为公司自身带来效益,也为整个行业提供了极为重要的参考案例。正如许多成功的公司一样,在不断实践中找到适合自身发展的道路至关重要。

四、Q&A

1. 图片语料处理
考虑到文档中除了文字信息,还有大量的图片材料,如何对图片进行有效处理至关重要。尽管语料的重要性在业内并不鲜见,但专业性更高的领域要求对图片的理解远超普通的文字处理。目前,校准和优化图片识别的标准仍在不断改进,例如,一些公司已在考虑使用更先进的图列技术和人工智能模式。虽然传统的识别技术可能无法达到工业级的质量,再加上信息的上下文关联性,这仍然是一个待解决的复杂问题。
2. 标题切分与上下文语意连贯
标题切分是提升用户体验的重要环节。很多时候,标题的处理需要依赖语义分析。如果在处理 Markdown 格式文档时,可以通过井号()进行切分,并在两边各增加一层重叠,由此确保上下文的连贯性。同时,灵活处理特定情况,采用各种方法,如 Llama index 引入的逻辑,能让文档的结构更加清晰,提升用户对内容的理解。
欢迎大家在下方留言讨论,分享您的看法!这样的交流无疑会让我们的文章更加丰富多彩。
