苹果重磅推出:Python联邦学习模拟框架!
苹果研究人员推出机遇性Python框架:pfl-research,引领联邦学习研究新纪元
在人工智能的浪潮中,联邦学习(Federated Learning,FL)以其独特的优势,正在逐渐崭露头角。这种新型的分布式机器学习框架,允许多个设备在保持数据本地化的共同训练模型,不仅优化了数据利用,还极大地增强了数据隐私保护。联邦学习的研究并非一帆风顺,模拟大规模、真实世界的联邦学习场景一直是困扰研究者的难题。近日,苹果研究人员推出的pfl-research Python框架,为这一难题提供了强有力的解决方案。
联邦学习是一种在分布式环境中进行机器学习训练的技术,其核心理念在于“数据不动,模型动”。具体来说,就是在保证用户数据隐私安全的前提下,通过让多个设备或服务器各自训练本地模型,然后将这些模型的参数进行聚合,以形成一个全局模型。这种方式不仅避免了数据的集中存储和传输,减少了数据泄露的风险,还使得模型能够利用更广泛的数据源进行训练,从而提高模型的泛化能力。
联邦学习的研究并非易事。由于数据分布在不同设备上,如何确保这些设备在训练过程中能够保持同步,是一个需要解决的关键问题。由于设备性能和计算资源的限制,如何高效地进行模型训练和参数聚合,也是联邦学习研究中的一大挑战。如何模拟真实世界的联邦学习场景,以验证研究成果的有效性和可靠性,更是研究者们需要面对的一大难题。
为了解决上述挑战,苹果研究人员推出了pfl-research Python框架。这个框架旨在为研究者提供一个快速、模块化且用户友好的联邦学习研究平台。通过pfl-research,研究者可以轻松地构建、训练和评估联邦学习模型,从而加速联邦学习研究的进程。
pfl-research的突出特点在于其多功能性和积木式的方法。它支持多种机器学习框架和模型,包括TensorFlow、PyTorch等主流框架,以及各类神经网络模型。这使得研究者可以根据自己的需求,选择最适合的模型和框架进行研究。pfl-research采用了模块化的设计思想,将数据集、模型、算法、聚合器等组件进行了分离和封装,使得研究者可以像搭积木一样,自由组合这些组件,构建出符合自己研究需求的联邦学习系统。
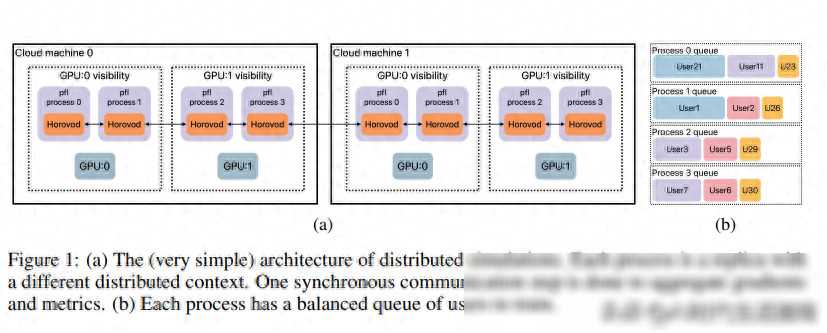
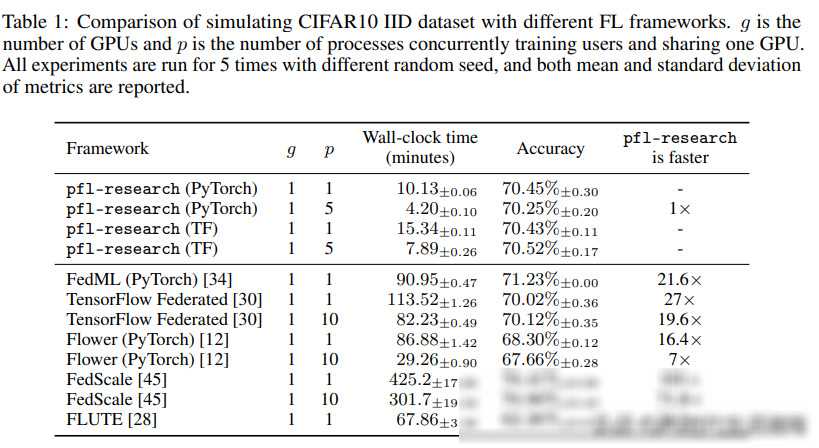
除了多功能性和积木式的方法外,pfl-research还具有出色的性能和可扩展性。在与其他FL模拟器的对比测试中,pfl-research的仿真速度最高可达竞争对手的72倍。这意味着研究者可以在更短的时间内完成更多的实验和迭代,从而加速研究进程。pfl-research还具有良好的可扩展性,支持大规模分布式计算和跨库仿真等功能,使得研究者能够模拟更加真实和复杂的联邦学习场景。
自推出以来,pfl-research已经得到了广泛的应用和认可。在隐私保护的自然语言处理领域,研究者们利用pfl-research构建了一个基于联邦学习的文本分类系统。该系统可以在多个设备上进行本地文本分类模型的训练,并通过参数聚合得到一个全局模型。实验结果表明,该系统在保持数据隐私的还取得了与传统集中式训练相当的性能。
在个性化健康应用方面,pfl-research也发挥了重要作用。研究者们利用pfl-research构建了一个基于联邦学习的健康监测系统。该系统可以收集用户的健康数据(如心率、血压等),并在用户设备上进行本地模型的训练。然后,这些本地模型的参数会被上传到服务器进行聚合和更新,以形成一个全局模型。通过这种方式,系统可以不断地从用户的健康数据中学习,为用户提供更加个性化和精准的健康建议。
除了上述应用案例外,pfl-research还在多个领域取得了显著的研究成果。例如,在图像识别领域,研究者们利用pfl-research构建了一个基于联邦学习的图像分类系统,该系统可以在多个设备上进行协同训练,并取得了比传统集中式训练更好的性能。此外,在推荐系统、智能家居等领域,pfl-research也展现出了巨大的潜力和应用价值。
虽然pfl-research已经取得了显著的研究成果和广泛的应用,但苹果研究人员并没有停下脚步。他们计划继续改进和完善pfl-research框架,以应对更加复杂和真实的联邦学习场景。具体来说,他们计划添加对新算法、数据集和跨库仿真的支持,以拓展pfl-research的应用范围和深度。他们还将探索更加尖端的仿真架构和可扩展性技术,以进一步提高pfl-research的性能和稳定性。
可以预见的是,随着pfl-research的不断发展和完善,它将成为联邦学习研究领域的得力助手和推动者。未来,我们有望看到更多基于pfl-research的优秀研究成果和应用案例出现,为人工智能的发展注入新的活力和动力。