
深入探索TorchRec:显著提升PyTorch推荐系统性能的最佳实践
TorchRec的优化工作:提升推荐系统性能的新探索
一、导读
在当今数据驱动的时代,推荐系统已经成为了各大平台不可或缺的一部分。无论是电商平台的商品推荐,还是社交媒体的内容推送,推荐系统的效率和准确性直接影响着用户体验和平台的商业价值。随着深度学习的迅猛发展,PyTorch作为一个强大的开源深度学习框架,逐渐成为了构建推荐系统的热门工具。而今天,我们要聊的,就是PyTorch上一个专门为大规模embedding设计的推荐系统库——TorchRec。
TorchRec到底是什么?它有哪些优化目标?在接下来的内容中,我们将一一揭晓。我们将深入探讨TorchRec的架构、优化措施以及最终的性能提升。这不仅对于技术从业者,也对于希望深入了解推荐系统的普通读者来说,都是一场技术盛宴。

二、TorchRec概述
TorchRec的定义
TorchRec是PyTorch官方开发的一个推荐系统训练库,其目的在于支持大规模的embedding处理。想象一下,在我们日常使用的电商平台上,成千上万的商品和用户行为需要通过机器学习算法进行有效匹配,而TorchRec正是在这个背景下应运而生的。它提供了高效的API,帮助开发者快速构建和训练推荐模型,降低了开发门槛。

优化目标
面对日益增长的数据量和复杂的用户需求,TorchRec的优化也显得尤为重要。我们希望通过优化实现以下目标:
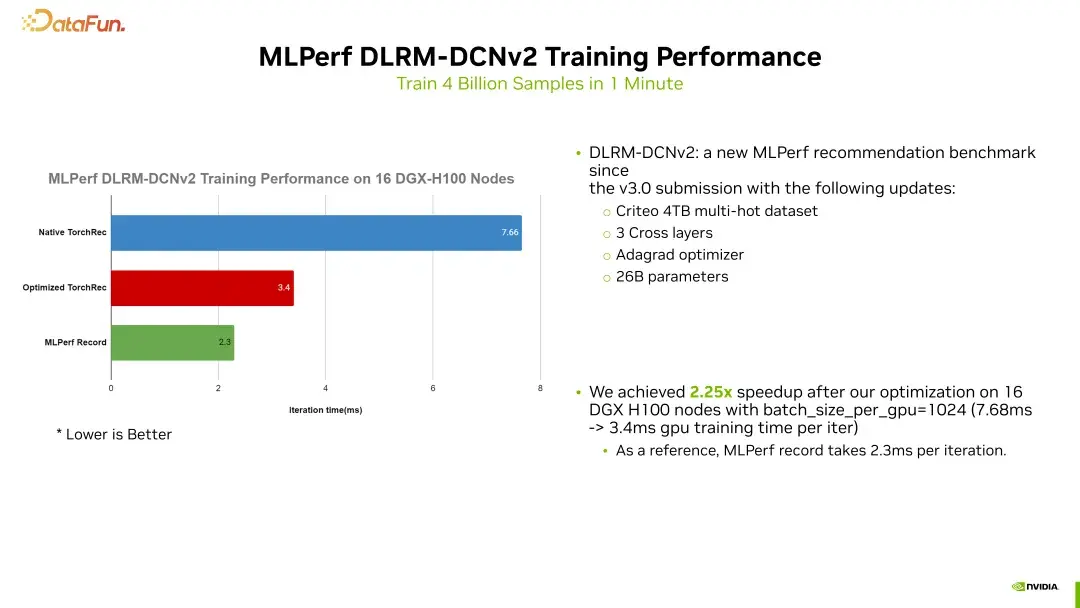
1. **提升性能**:尤其是针对MLPerf中的DLRM benchmark,如何在16个DGX节点上实现更高的扩展性?
2. **保持API稳定性**:优化过程中,如何不破坏TorchRec的API,使得用户可以无缝过渡?
3. **高层次的优化**:在不改变架构的前提下,专注于模型的高层次优化,如何才能做到这一点?
这些问题的答案,将为我们后续的讨论奠定基础。
三、TorchRec的整体架构
架构层次
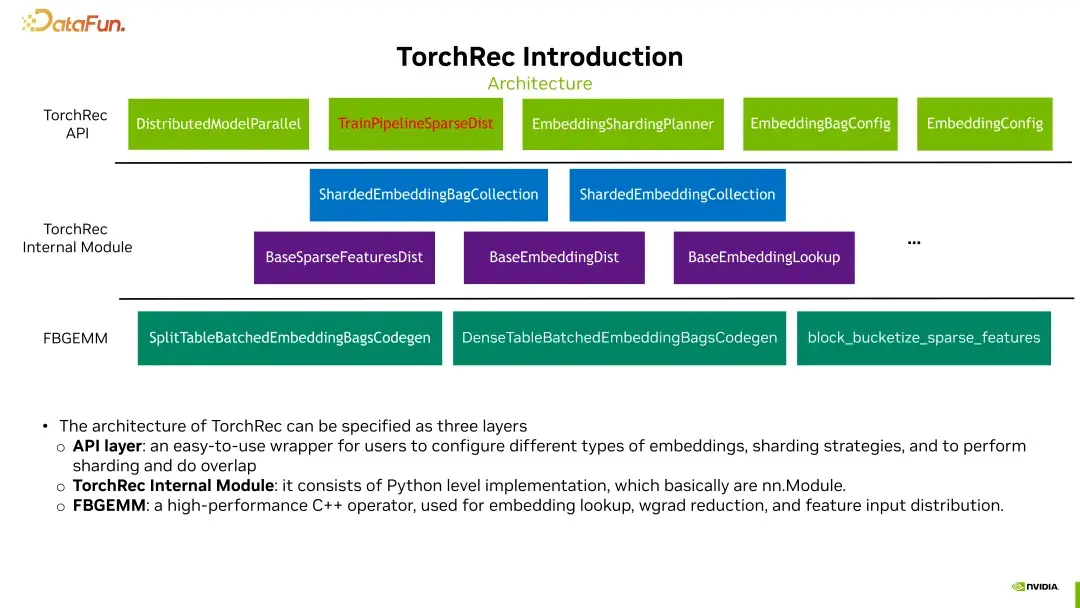
为了更好地理解TorchRec的优化,我们先来看看它的整体架构。TorchRec的架构可以分为三个层次:
1. **最上层:TorchRec API**
这一层主要提供了一些简单易用的wrapper,用户可以轻松配置不同的embedding,实现sharding,并在训练过程中进行流水线操作。想象一下,开发者可以像搭积木一样,快速构建出复杂的推荐系统。
2. **中间层:内部模块**
这一层包括了sharding的实现,将embedding分成了多个部分。这里的代码主要是Python实现的nn.module,开发者可以在这一层进行定制化开发。
3. **最底层:FBGM库**
FBGM是C++层面的库,专注于GPU上高效实现的稀疏相关操作。这一层虽然看似复杂,但实际上是整个系统高效运行的基础。
使用示例
用户如何使用TorchRec呢?其实,使用TorchRec可以分为三个简单的步骤:
1. **构建embedding**:通过EmbeddingBagConfig和EmbeddingBagCollection这两个API,用户可以快速构建embedding。
2. **完成sharding**:使用DistributedModelParallel,TorchRec默认将embedding在每个GPU上进行模型并行,用户也可以选择定制化开发。
3. **构建训练流水线**:通过TrainPipelineSparseDist API,用户可以构建训练流水线,实现更好的性能。
这些步骤看似简单,但其中的细节却蕴含着丰富的技术挑战。
四、优化结果
性能提升

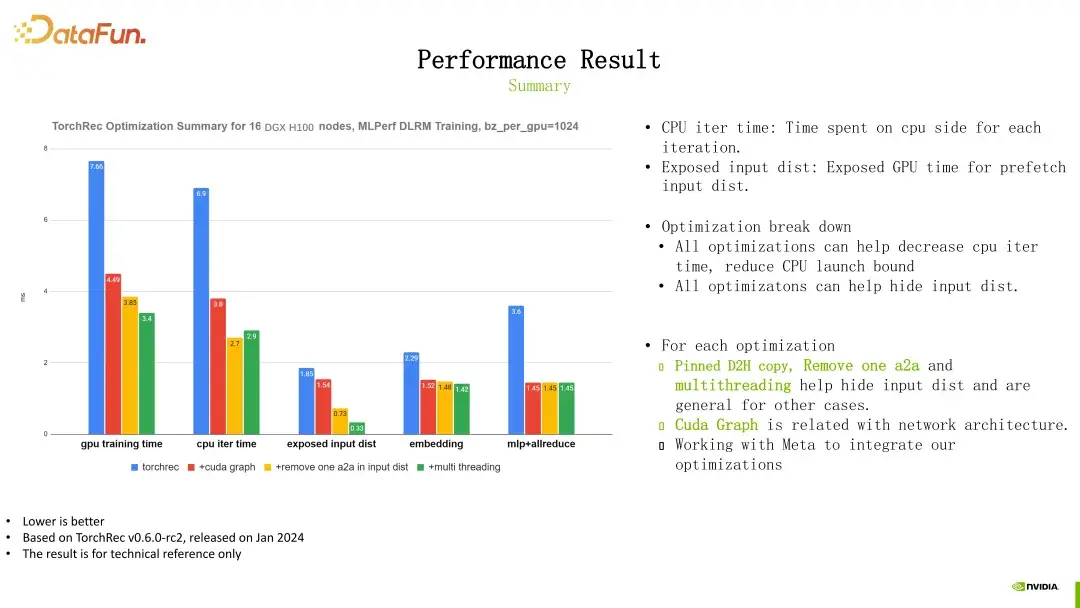
最终的目标就是提高性能。在我们对TorchRec进行一系列优化之后,性能得到了显著提升。原本每次iteration需要耗时7.6毫秒的TorchRec,经过优化后成功缩短至3.4毫秒,这样的提升令人惊叹,达到了2.25倍的加速。更令人振奋的是,当前MLPerf的世界纪录为2.3毫秒,这也意味着我们的优化几乎达到了行业顶尖水平。
但这背后又是怎样的一番操作呢?我们又是如何在众多技术细节中找到突破口的?接下来的内容将为你揭晓。
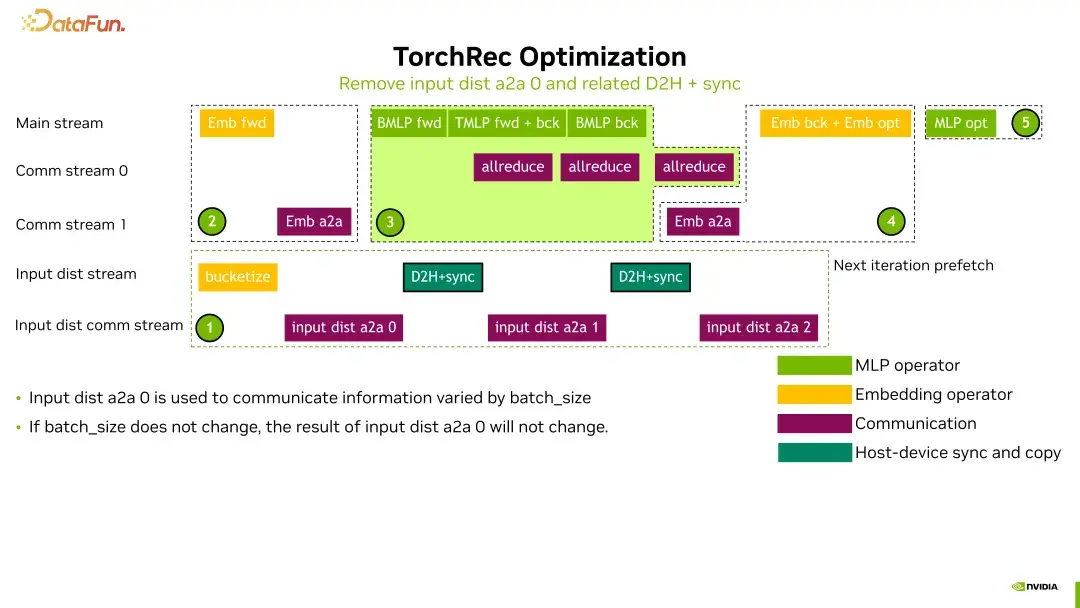
五、优化方案分析
训练流程分解
优化工作并非一蹴而就。我们将TorchRec的训练流程分解为五个部分,分别是:

1. **输入特征分发**
将输入特征从数据库或硬盘读取到GPU,并将其从数据并行转换成模型并行。
2. **Embedding前向传播**
在当前GPU上进行embedding table的查询,以及embedding全到全的操作。
3. **MLP的前向和反向传播**
进行MLP的前向和反向传播,以及梯度的allreduce。
4. **Embedding反向传播**
反向传播过程中,需进行all-to-all操作、backward操作及embedding table的更新。
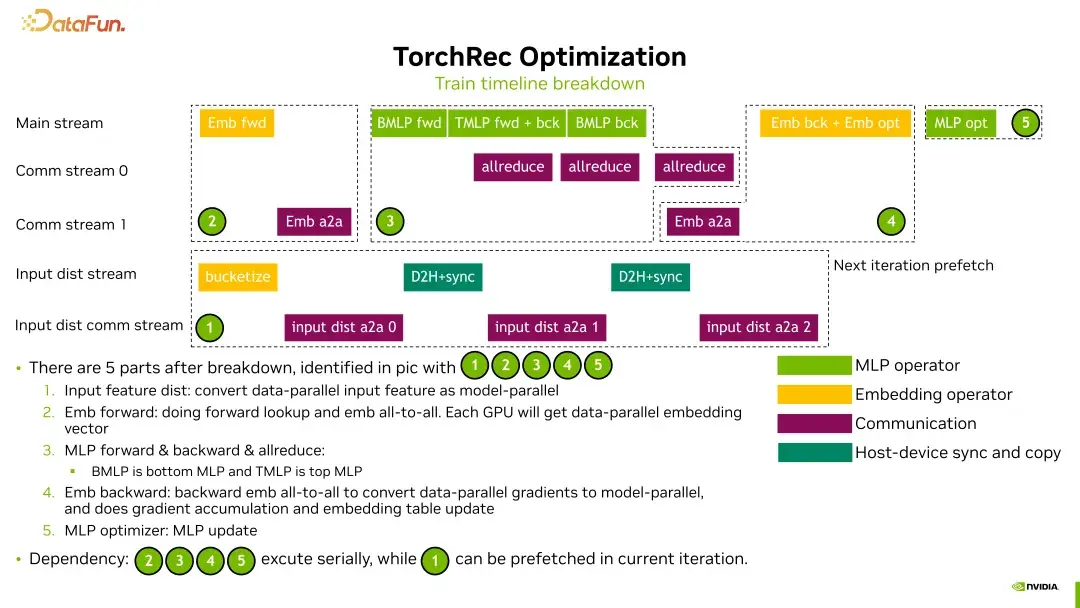
5. **MLP的更新**
最后一步是对MLP的更新。
在这五个部分中,前四个之间存在依赖关系,而第一部分则可以与其他部分并行进行,这为我们的优化提供了可能性。
优化方法总结
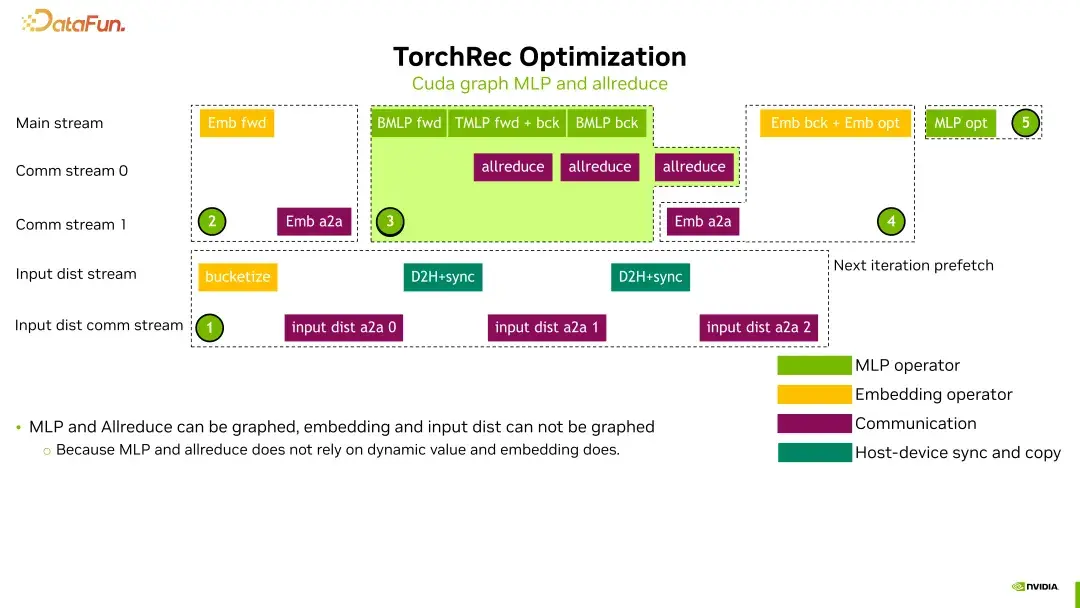
通过对训练流程的分解,我们可以将优化措施总结为两大部分:
1. **优化CPU启动延迟**
如何在确保性能的同时,减少CPU的启动延迟?这无疑是一个关键问题。
2. **优化输入分发部分**

通过去掉不必要的操作,进一步提升性能。
这些措施的实际效果又是如何的呢?接下来,我们将逐一探讨。
六、详细优化措施
使用CUDA Graph
我们使用CUDA Graph来优化MLP和allreduce部分。通过CUDA Graph,我们可以捕获中间的kernel启动过程,减少CPU的调用时间。这就好比在高速公路上开车,你不需要每次都停下来加油,而是提前规划好加油站。
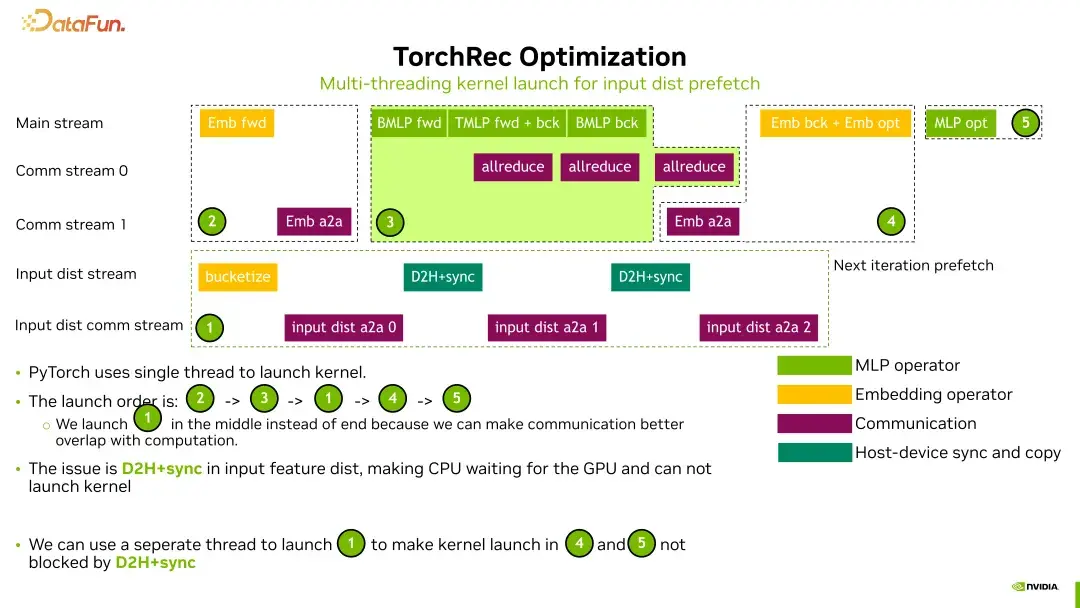
多线程kernel启动
我们引入了多线程的kernel启动。TorchRec原本在同一时间只使用一个线程来启动kernel,这导致了CPU的等待时间被浪费。通过引入多线程,我们能够在一个线程上启动输入特征分发,而在另一个线程上启动MLP的更新,从而有效利用CPU的资源。
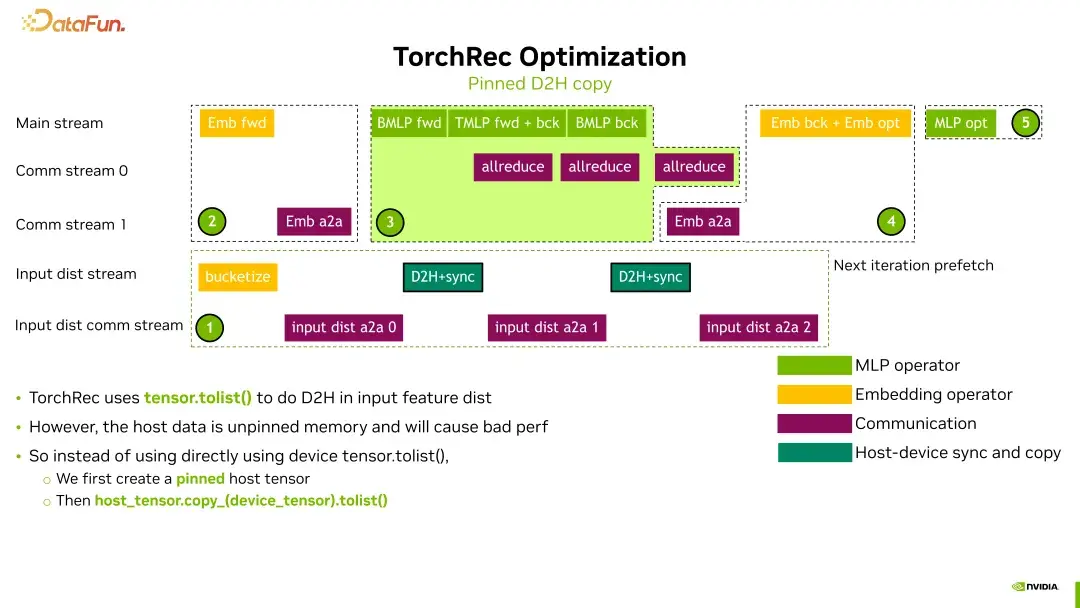
Pinned Memory使用
我们对D2H(Device to Host)的拷贝进行了优化,采用了Pinned Memory。这一优化不仅提升了内存的访问速度,还有效减少了CPU的开销。想象一下,使用Pinned Memory就像是插上了快速通道,让数据传输更加顺畅。
环境变量优化
我们通过设置环境变量TORCH_NCCL_AVOID_RECORD_STREAMS,减少了CPU的开销。原本在使用多个stream时,为了确保内存安全性,PyTorch会进行轮询,导致性能下降。而通过设置该环境变量,我们有效避免了这一开销。
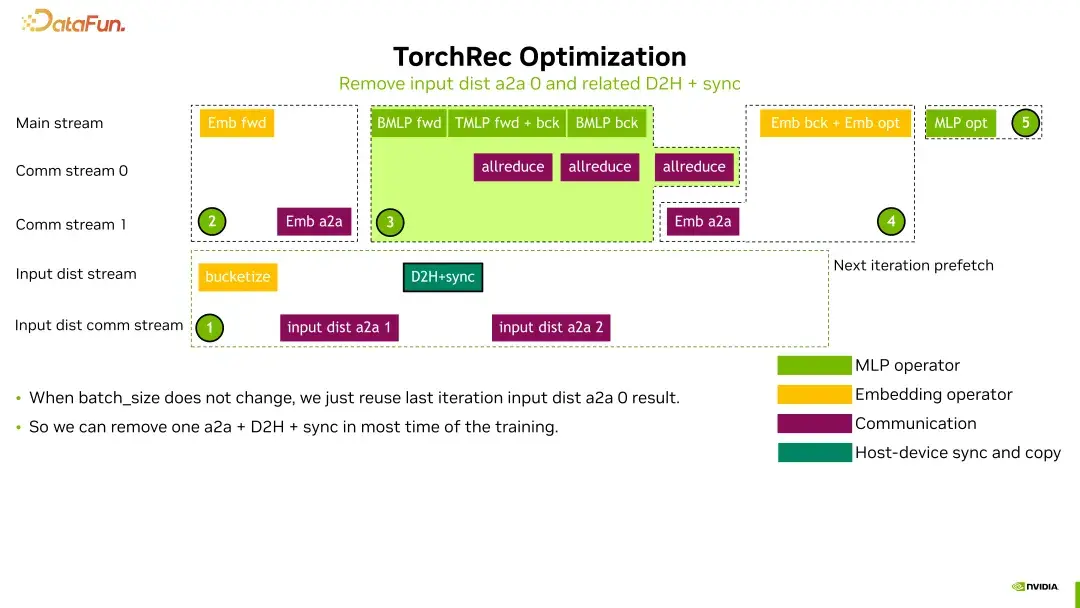
去除冗余操作
我们对输入特征分发部分进行优化,去掉了一些不必要的中间操作。这一措施使得我们在数据传输时避免了多余的计算,从而提高了整体效率。
七、性能结果展示
详细性能指标
经过一系列优化后,我们对TorchRec的性能进行了详细测试,结果令人满意。比如,在GPU上每个iteration的训练时间显著降低,CPU上的开销也大幅减少。这样的结果不仅展示了我们优化工作的有效性,也为未来的研究提供了重要的参考。
优化收益总结
这些优化措施不仅减少了CPU上的开销,还提高了GPU上的训练效率。特别是在输入分发部分,我们的优化使得这一环节的时间开销得到了良好的隐藏,提升了整体性能。
八、结论
总结优化工作的意义
通过本次优化,我们不仅提升了TorchRec的性能,也为推荐系统的发展提供了新的思路。优化工作是一个不断迭代的过程,只有通过不断的实验和总结,才能找到最佳的解决方案。
对未来工作的展望
TorchRec的优化方向可能还会扩展到更多的网络结构,尤其是那些依赖动态输入的模型,如Transformer等。在这些领域,如何更有效地进行优化,将是我们面临的新挑战。
九、致谢
在这篇文章的最后,我想感谢所有参与TorchRec优化工作的团队成员。正是你们的努力和坚持,才让这些技术的实现成为可能。希望各位读者能够在这篇文章中找到启发,继续关注推荐系统领域的最新动态。