
如何高效同步数据库数据?揭秘超大表处理的终极秘籍!
标题:如何高效同步数据库数据?揭秘超大表处理的终极秘籍!
亲爱的读者朋友们,今天我们将深入探讨如何高效地同步数据库,特别是在面对超大表时,如何高效处理以及提高同步效率。这不仅关乎数据的完整性和一致性,更是提高工作效率的重要一环。在这个信息爆炸的时代,掌握这些技能让你在职场中如虎添翼。接下来,让我们一起打开这扇通往高效数据库管理的大门吧!
一、数据库同步的重要性
在如今的数据驱动时代,数据库同步的必要性不言而喻。无论是小型企业还是大型跨国公司,实时更新和准确的数据库信息都是业务决策的基础。在开展数据分析、生成报表、以及确保客户信息的实时准确时,数据库的高效同步能力直接影响到工作效率和服务质量。
尤其是在多个系统交互时,确保数据的一致性是至关重要的。倘若在订**台和库存管理系统之间数据不一致,顾客很可能订购到缺货商品,直接影响客户体验并可能导致经济损失。据统计,近70%的企业在未同步或同步出错时,曾经历过客户投诉。这不是小问题,它影响的是公司的声誉与客户信任。
二、mydumper工具介绍
使用合适的工具是实现高效数据库同步的第一步。在众多可供选择的工具中,mydumper因其高效的性能和灵活的配置而受到推崇。这是一款专为MySQL设计的多线程数据导出工具,支持并发处理,能够处理大量数据并将其快速导入或导出。
主要特点与功能包括支持分片导出,适应各种表的大小和配置。这一点尤其对处理超大表时极为重要。更为人称道的是,它可以自定义线程数,用户可以根据服务器的承受能力和当前任务来灵活选择。
如果你想快速掌握mydumper,建议从其GitHub页面入手,查看使用文档和示例代码,了解其使用案例及最佳实践,这将为你的实际操作提供宝贵的参考。
三、同步数据库的具体步骤
在开始同步之前,一定要对数据库的情况有个全面的了解。启动mydumper的第一步是确认服务器的负载。有时候,过多的线程会导致数据库响应变慢,所以合理配置非常关键。
了解自己的表的规模后,使用mydumper的基本命令来进行数据的导出:
```bash
mydumper -u username -p password -h host -B dbname -t 4
```
这里的参数需要你根据实际情况进行调整,比如你可以使用`-t`来指定线程数,最大能够使用到255个线程。这样可以大幅提高数据导出的效率。
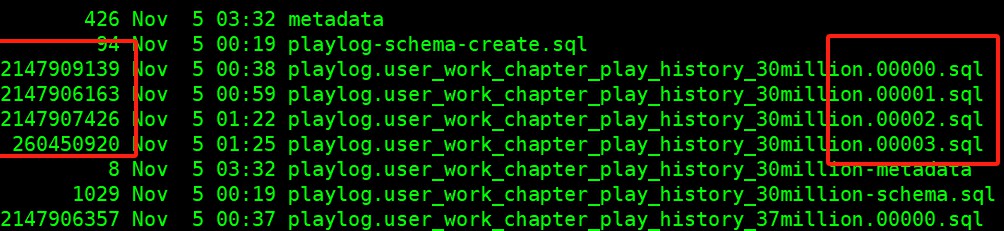
当面对大表时,也许你会遇到因数据量过大导致的处理速度慢的问题。这时,别慌!你可以通过使用--chunk-filesize选项将大表拆分成多个小文件,这样将极大地降低每个文件的处理时间。例如,使用参数设置如下:
```bash
mydumper -u username -p password -h host -B dbname -t 6 --chunk-filesize=2048
```
在此命令中,这就将一张大表分拆为多个2GB的文件,即使是100GB的表也能高效处理,节省了大量等待时间。
四、实战操作示例
不妨尝试以下步骤。假设我们正在处理一个名为`playlog`的数据库,首先使用mydumper将数据导出:
1. 进入到命令行终端,执行以下命令:

```bash
mydumper -u dba -p password -h 192.168.1.20 -B playlog -t 6 --chunk-filesize=2048
```
这个命令表示我们将用6个线程将表数据导出,每个切片为2GB,分成多个文件。
你会看到多个文件生成在指定目录下。接下来的工作就是使用myloader来将这些数据导入到目标数据库中。例如:
```bash
myloader -u dba -p password -h host -B newdbname -d /data/playlog
```
此命令会自动识别并加载所有的数据切片,实现高效的同步。
通过以上的实践例子,可以明显感受到mydumper和myloader在处理大量数据时的速度和灵活性。事实上,一些企业在使用mydumper后,数据导入时间缩短了近70%,这对于需要实时数据更新的业务来说,无疑是个福音。
五、总结与展望

mydumper这个工具,不仅仅是一款简单的数据导出工具,更是提升工作效率的重要助手。通过合理配置线程和拆分数据文件,我们能够高效、准确地完成数据库同步任务。在不断变化的信息技术领域,不断探索和学习是IT人员保持竞争力的关键。期待在未来,有更多高效的工具出现,助力我们在数据管理的道路上越走越远。
欢迎大家在下方留言讨论,分享您的看法!