
大型语言模型(LLM)全解析:你知道的太少,必看这篇!
大型语言模型(LLM)全解析:你知道的太少,必看这篇!

亲爱的读者朋友们,今天我们将共同探讨一个正在引发广泛关注的领域——大型语言模型(LLM)。无论你是一名技术人员,抑或是对AI感兴趣的普通读者,本文将助你更深入地理解LLM的训练与应用。我们将从五个核心方面入手,逐步向你揭示其中的奥秘!
一、LLM的定义与重要性
大型语言模型(LLM)是利用深度学习技术搭建的自然语言处理(NLP)模型,具有强大的文本生成、分类和翻译等功能。许多知名的AI助理如GPT、BERT等,都是基于LLM技术开发而成。
为什么LLM如此重要? 在信息化快速发展的今天,大量的数据产生在不断增加,这给了LLM无限的学习可能。根据统计,全球每天生成超过500亿条数据。在如此庞大的数据背景下,LLM能够处理与分析信息,帮助我们更好地理解和利用数据。而且,LLM不仅能提升商业效率,还能在教育、医疗等领域发挥巨大作用。
二、LLM训练-预训练(Pretraining)
自研预训练模型的意义在于作者可以更好地掌握预训练的技术能力,以满足特定需求。这个过程也将对数据质量有更强的控制力,同时通过这样的实践,科研成果还可以向外界展示。
在数据准备上,获取高质量数据并不简单。通常需要成立专门的数据收集团队,考虑到不同的数据来源,包括开放的数据集、爬虫抓取和购买数据等方法。在这过程中,数据的清洗和去重非常关键。例如,数据清洗可以去掉重复、无效的信息,确保后续训练的有效性。
数据顺序的重要性也是不容忽视的,这能直接影响到模型学习的效果。推荐使用“语义相似度”去拼接最相关的文档,形成更加流畅的训练上下文。而有必要在此过程中标记数据的使用次数,以避免过度重复选用某些数据片段。
三、LLM训练-监督微调(SFT)
在进行监督微调(SFT)的过程中,数据的多样性和质量至关重要。通过标注数据来引导模型,SFT能有效提升模型的指令遵循能力。特别是在复杂领域,尤其需要保证数据的质量和多样性。例如,可以利用GPT-4等模型生成的辅助数据,来丰富训练样本。
面临的挑战包括如何消除模型生成的“幻觉”。幻觉是指模型可能生成错误或不准确的信息。此时,通过强化学习(RLHF)来改进模型是一个值得考虑的方向,虽然在消除所有幻觉上依旧具有挑战,但可以逐步提高模型拒绝回答不确定问题的能力。
针对SFT的流程设计,确保数据类别的覆盖与均匀分布至关重要。在实际操作中,可以通过收集用户反馈,形成数据闭环:从用户日志到数据更新,然后又反馈到模型迭代。这种方法不仅能提升模型性能,还能使其更符合用户需求。

四、LLM预训练与SFT数据配比调研
在LLM的预训练过程中,数据增强与清洗技术无疑是重要环节。以Qwen和LLAMA为例,这两款模型在数据处理方面都有独到之处。如,Qwen使用启发式过滤、模型过滤等方法有效提高数据质量,LLAMA则通过长上下文训练优化模型表现。
数据量的增长也不容忽视,从几万亿token到数十万亿token,这一变化显示了大规模训练的需求和潜力。同时,随着数据类型的多样化,如代码、数学推理和多模态数据的引入,团队需要针对不同类型数据进行有效处理与使用。
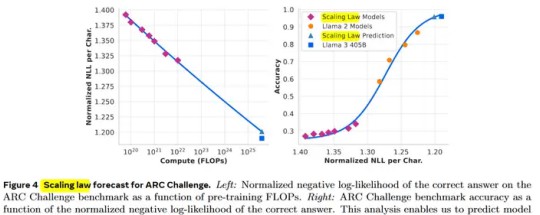
对于SFT数据配比的研究,LLAMA和Qwen使用了一系列有效的技术策略,如清洗、话题分类、质量打分等,成功达到了2.7M的规模。在大模型训练中,数据配比的策略逐渐演变为一种“商业秘密”,掌握这些技术的团队将在市场竞争中占据优势。
五、LLM数据合成之后训练篇
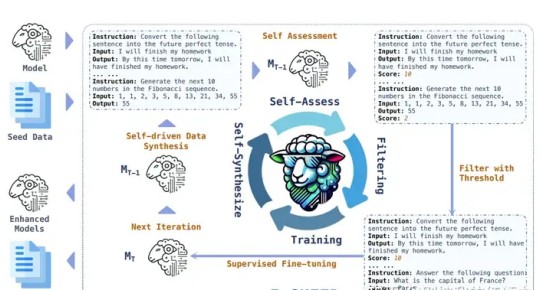
数据合成是提升模型性能的重要手段。当前主流的合成方法包括生成问题对(pair)、问题或答案,以及模型自身迭代。在模型训练中,Nemotron-4的例子尤为突出。在这个模型的设计中,超过98%的数据都是由合成生成的,这显示了数据合成在提升模型泛化能力方面的巨大作用。

如何评估生成数据的质量? 这是数据合成过程中不可忽视的问题。可以通过引入强大的reward模型,自动评估生成数据的质量,确保高质量数据进入下一轮训练。同时,模型自我评估的方式也是一种有效的创新,实现了从无到有的自我对齐过程。
利用这些数据合成的方法,模型能够持续自我进步,逐步改进其在实际应用中的表现。即使在没有引入外部数据的情况下,这些方法仍能有效提升模型的输出质量。
六、大模型SFT数据精选方法串讲
在提升大模型SFT数据的质量方面,精选数据的方法非常重要。以IFD和Superfiltering为例,IFD计算了Instruction-Following Difficulty指标,帮助团队评估数据集的价值,从而选取高IFD的样本。Superfiltering则通过小模型替代大模型,以提高筛选效率。
目标导向的方法如Nuggets和LESS更适合具体应用场景的优化。Nuggets通过评估训练数据对测试集的增益效果来筛选高质量数据,而LESS直接考察训练数据对测试集损失的影响。这类方法不仅提升实验的有效性,更能为实际业务需求对接,增强模型表现。
确保数据的高质量、多样性和必要性,特别是在实际工业落地过程中,推荐优先使用目标导向的方法。这将帮助团队更快适应市场变化,提高竞争力。
文章结束
本文针对大型语言模型(LLM)的多个维度进行了探讨,从理论到实践,一步步为你揭开这些技术的神秘面纱。希望通过这篇文章,你对LLM的理解有了更深的提升!欢迎大家在下方留言讨论,分享您的看法!