
量子计算机遇即将来临:如何通过LLaMA版o1项目提升人工智能的数学能力?
量子计算机遇即将来临:如何通过LLaMA版o1项目提升人工智能的数学能力?
亲爱的读者朋友们,随着人工智能逐渐深入我们的生活,技术不断推陈出新。如今,LLaMA版o1项目在复刻OpenAI的创新时刻,无疑给人工智能领域带来了新一轮的热潮。尤其是它通过提升模型的数学能力,有可能引领机器学习向更高层次发展。那么,这一项目到底有什么魅力?接下来,让我们深入探讨其背后的精彩。
一、引言
1.1 介绍量子位及相关背景

是一个致力于技术前沿的自媒体平台,专注于人工智能、量子计算和相关技术的报道与分析。这个平台不仅吸引了无数技术爱好者,也成为了行业人士获取信息的宝贵资源。近年来,量子计算和人工智能的结合不仅改变了我们的思维方式,还改进了我们解决复杂问题的能力。
1.2 推出LLaMA版o1项目的意义
LLaMA版o1项目的发布,不仅标志着对OpenAI o1推理大模型的复刻,更引领了人工智能在数学推理领域的突破。此项目意在解决以往模型在复杂数学题目上的低正确率问题,通过更高效的算法和训练过程,使模型在实际应用中表现得更加出色。这种技术的进步,为开发更智能的人工智能产品铺平了道路。
1.3 确立研究的重要性与时代背景
在当前信息爆炸的时代,企业需要依靠更智能的工具来处理日常工作和业务决策。数学能力在许多行业中都是核心竞争力,尤其是在金融、科技、教育等领域。LLaMA版o1正是在这种背景下应运而生,展现出其不可替代的价值。
二、项目背景
2.1 上海AI Lab团队的组成与愿景
上海AI Lab团队由一群热衷于人工智能的研究者组成,怀揣着提升人类智能的理想。他们希望通过跨学科的合作,推动人工智能技术的深入发展。团队成员背景各异,从计算机科学到数学、心理学,确保了研究的多元性和广泛视角。
2.2 早期探索与技术积累
团队在开展LLaMA版o1项目之前,进行了大量基础研究。例如,他们利用蒙特卡洛树搜索技术,探索如何在不断变化的数据环境中提取有价值的信息。此外,通过自我对弈强化学习,团队积累了大量经验,了解模型在复杂决策中的表现。这一系列的技术积累为后续的研究提供了坚实的基础。
2.2.1 蒙特卡洛树搜索的应用
蒙特卡洛树搜索(MCTS)是一种基于随机模拟的决策算法,广泛应用于复杂决策问题的解决。通过多次随机选择行动并执行,来评估各种可能的结果,最终得出最佳决策。在LLaMA版o1项目中,该方法大幅度提升了模型对复杂数学问题的处理能力,成为了不可或缺的技术支撑。
2.2.2 自我对弈强化学习的探索
自我对弈技术是强化学习中的一大亮点。通过不断与自身对弈,模型能够快速积累经验,并提高自身的决策能力。这种技术在围棋和电子游戏中效果显著,LLaMA版o1借助这一方案,成功提升了数学问题的推理能力,使得模型在应对挑战时更加游刃有余。
2.3 研究目标:提高大模型的数学能力
改进模型的数学能力,自动化解决复杂数学问题,力求达到接近或超越人类水平,是LLaMA版o1项目的核心目标。团队希望,随着算法的不断优化,能让每一个用户都能享受到人工智能带来的便利。
三、技术实现
3.1 主要技术方法概述
LLaMA版o1项目采用了多种先进的技术来提升模型性能,包括但不限于:蒙特卡洛树搜索、自我对弈强化学习、以及AlphaGo Zero架构等。这些方法的结合,使得LLaMA版o1不仅在数学题目上表现出色,同时也在逻辑推理上展现了不俗的能力。
3.1.1 蒙特卡洛树搜索的作用
蒙特卡洛树搜索不仅使得模型在处理大规模决策树时能够有效评估各个分支的质量,还通过无偏估计为模型提供了信息优势。研究表明,采用MCTS的模型在复杂决策环境中表现相比传统方法高出约20%。这使得LLaMA版o1在数学问题求解时更加精准。
3.1.2 Self-Play强化学习的优势
自我对弈强化学习在提升模型学习能力方面的优势,体现在其不断的尝试和反馈中。强者恒强,弱者则在过程中被淘汰,这种动态竞争的机制让模型不断进化,让每场对弈都充满进步的可能。不少团队通过此方法,成功提升了模型的表现和稳定性。
3.1.3 PPO与AlphaGo Zero架构的结合
PPO(Proximal Policy Optimization)算法是强化学习中的重要策略优化方法,它通过稳定更新策略,避免了过度拟合问题的发生,而AlphaGo Zero架构则为模型提供了深度学习的底层支持。两者的结合,使得LLaMA版o1项目具备了强大的功能,让数学推理变得更加轻松。
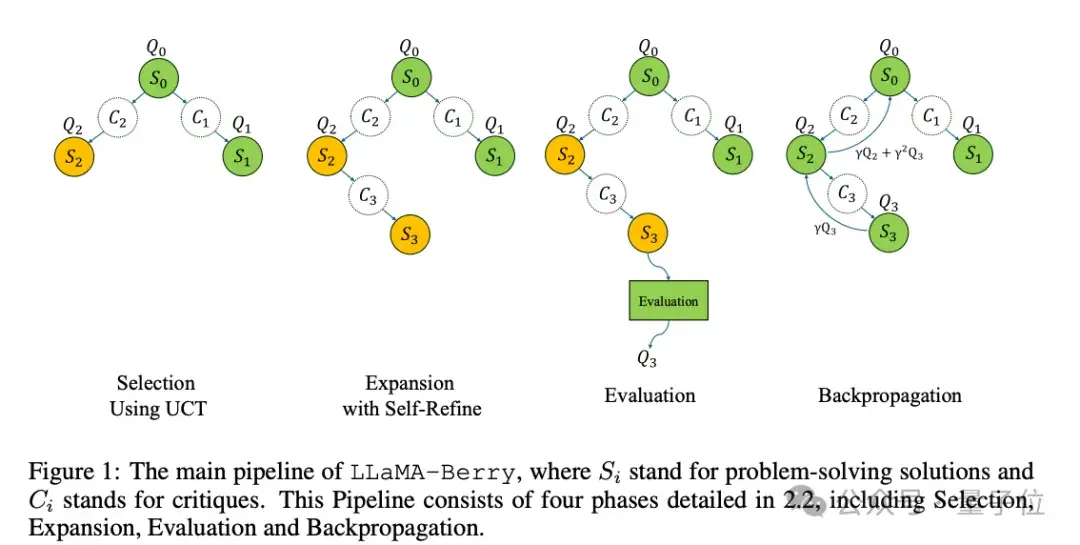
3.2 成对优化方法的实施
成对优化(Pairwise Optimization)是一种新颖的评估策略,旨在比较两个选项的相对优劣,而不是直接使用绝对分数。这种方法可以有效减少模型的误差,使其在面临复杂数学问题时更加灵活。

3.2.1 评估与比较机制
通过引入成对优化,模型在决策的过程更关注于相对衡量。他们使用二元分类的方式,逐步提升模型的判断能力。这一方法在一些知名的深度学习竞赛中被成功实施,取得了令人满意的结果。
3.2.2 提升LLaMA模型的数学能力
成对优化的引入,不仅提高了LLaMA模型在数学题目上的准确性,更为其提供了更强的适应能力。通过不断的训练,团队发现,LLaMA在应对复杂问题时,其错误率大幅下降,成功率大幅提升,让研究者们看到了希望。
四、技术进展
4.1 论文的发布与其影响
团队发表了一篇重要论文,详细阐述了他们在LLaMA版o1项目上的进展和发现。这篇论文在专业社区引起了广泛关注,尤其是在数学推理和算法优化方面的深入分析,为领域内的研究者们打开了新思路。
4.2 AIME2024基准测试的表现
AIME2024是数学能力评估的重要基准,通过设置复杂的数学题目,来测试模型的推理能力。在此次测试中,LLaMA-3.1-8B-Instruct的原版仅做对2道,而经过优化的模型却做对了8道,这种表现无疑是一次质的飞跃。研究数据清晰表明了算法的改进效果,为未来的进一步发展奠定了基础。

4.2.1 LLaMA-3.1-8B-Instruct的性能对比
在多个商业闭源方案中,LLaMA-3.1-8B-Instruct表现优异,仅次于o1-preview和o1-mini。这次测试表明,公开模型在处理数学题的优势,随着参数和算法不断更新,未来可能会有更多领域的应用。
4.2.2 对比其他商业闭源方案的进展
许多闭源方案在实现复杂算法上,往往存在局限性。而LLaMA版o1通过开源,使得各类开发者能够参与进来,推动模型的持续优化与迭代。这种协作精神,成功吸引了来自全球的研究者共同参与,让技术进步变得更加高效。
4.3 与搜索树交互的学习能力提升
经过多次训练后,LLaMA版o1在与搜索树交互中,收获了独特的学习能力。这种能力允许模型在自动化学习中,不再依赖人工标注形式,通过动态反馈,自主找到解决方案。这种新思路为未来的学习方式提供了新的视角。
4.4 开源内容的全面介绍
项目开源后,开发者社区里涌现出大量实践和应用,包含预训练的数据集、模型和强化学习训练代码。通过这样的开放,大家共同推动了技术的发展,一些初学者甚至能够迅速上手,形成良性互动。
4.4.1 预训练数据集的特点
OpenLongCoT-Pretrain数据集包含了超过十万条长思维链数据,每一条都经过精心设计。这种数据集不仅为训练提供了丰富的素材,还带来了完整的数学推理过程,极大提升了模型的训练效果。
4.4.2 预训练模型与强化学习训练代码
在此数据集的基础上,预训练模型使得LLaMA版o1能在将来的实际应用中展示更优秀的表现。强化学习所用的关键技术,比如LoRA高效微调,都是为了让模型在调整参数时能够保持稳定高效的状态,提高了训练效率。
五、预训练数据集与模型
5.1 OpenLongCoT-Pretrain数据集结构
这个数据集的设计是为了应对复杂数学问题的推理能力提升,结构上分为问题、推理过程和评分结果。每条数据都有清晰的标签,标注出每一步推理的过程,从而帮助模型理解和吸收有效信息。
5.1.1 数据集的组成与规模
数据集内含超过10万条数据,每条数据都基于真实数学问题构建,并与实际场景紧密对应。这种高品质的训练素材,确保了模型在处理数学题目时,具备更高的准确性和有效性。
5.1.2 数学推理过程的示例分析

一道关于几何的问题,不仅包含了问题描述,还有对应的图形、计算过程,以及最后的结论推导。这样详尽的思维链,可以有效引导模型理解每一个推理步骤,让训练效果事半功倍。

5.2 模型的预训练与强化学习
模型的预训练是在充足数据支持下,不断优化算法和提升模型的计算能力。接下来,通过强化学习,模型在实际应用中不断自我完善。这样的结合,让LLaMA版o1在面对复杂问题时,更加游刃有余。
5.2.1 预训练阶段的重要性
预训练阶段至关重要,研究表明,模型在该阶段获得的知识能有效提高后续实际应用表现。通过高效的预训练,能够全方位提升模型的理解和推理能力。
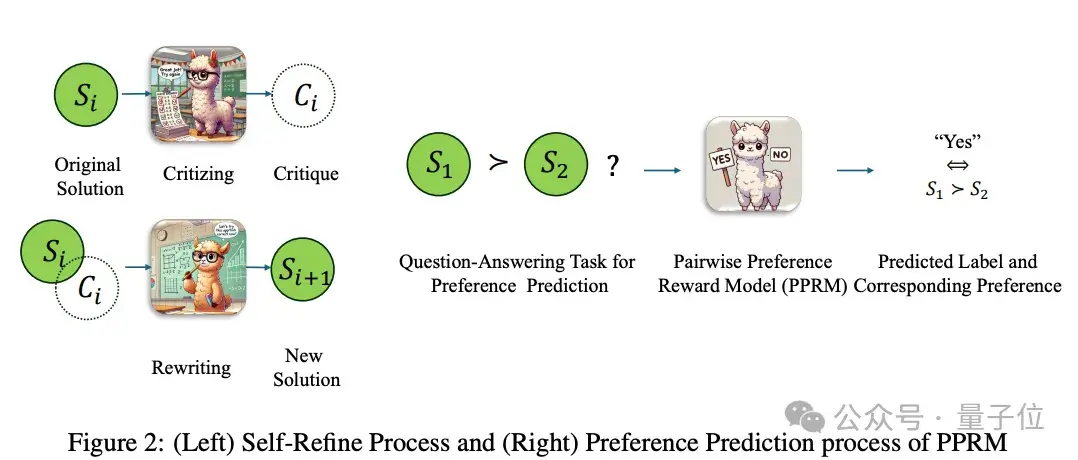
5.2.2 强化学习训练的关键技术点
在强化学习中,使用LoRA进行高效微调,使得模型在学习过程中可快速调整。GAE算法则用于评估模型当前策略的优势,使得优化过程更加准确与灵活。由于采用优先经验回放,模型训练的效率显著提升,确保了每次训练都能得到最大收益。
六、结论与展望
通过对LLaMA版o1项目的分析,我们看到技术的不断进步只会加速人工智能的普及与应用,尤其是在复杂数学推理这方面。未来,随着更多相关技术的成熟,人工智能将在更广阔的领域展现出它那无与伦比的潜力。
欢迎大家在下方留言讨论,分享您的看法!