
智能电影推荐系统:BERT+向量数据库,观影新体验!
在数字化时代,我们每天都在与海量的数据打交道。其中,电影数据是一个庞大的领域,如何高效地为用户推荐他们可能感兴趣的电影,成为了一个重要的技术挑战。智能电影推荐系统正是为了解决这个问题而诞生的。
智能电影推荐系统的核心是利用先进的算法和技术,如BERT模型和向量数据库,来分析和理解用户喜好,然后推荐出最符合用户口味的电影。这种系统不仅能提升用户体验,还能帮助电影平台提高用户粘性和转化率。
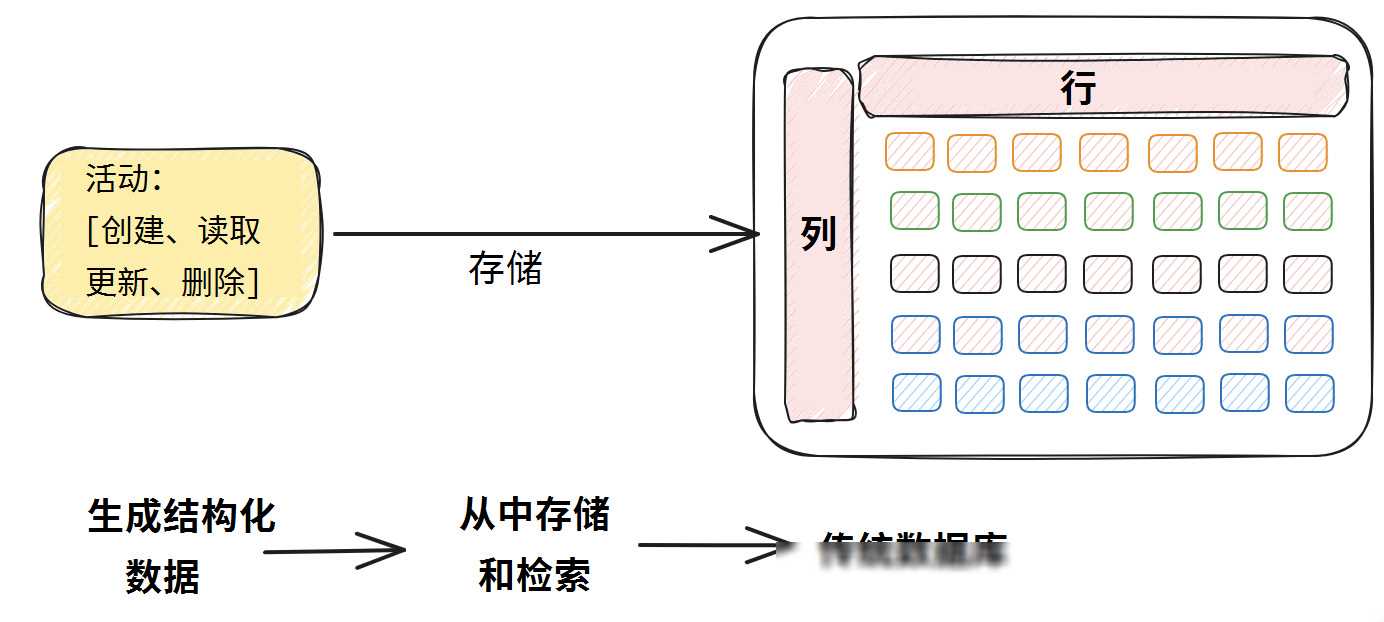
关系数据库管理系统(RDBMS)曾经是数据存储和管理的王者,它们以表格的形式组织数据,使得结构化数据的存储和处理变得简单高效。随着技术的发展,我们逐渐发现RDBMS在处理非结构化数据时的局限性。比如,当我们想要从海量的电影数据中找出与某部特定电影相似的其他电影时,RDBMS就显得力不从心。这是因为RDBMS主要基于文本匹配和简单的数值计算,难以捕捉数据的深层特征和模式。
为了克服RDBMS的局限性,向量数据库应运而生。向量数据库是一种特殊类型的数据库,它专注于存储、检索和管理向量数据。这些数据通常是高维的,能够捕捉到非结构化数据的复杂特征和模式。
在电影推荐系统中,向量数据库可以存储电影的特征向量,这些向量是通过深度学习模型(如BERT)从电影描述、剧情、演员阵容等文本信息中提取出来的。通过计算这些向量之间的相似度,我们可以轻松地找到与某部特定电影相似的其他电影。
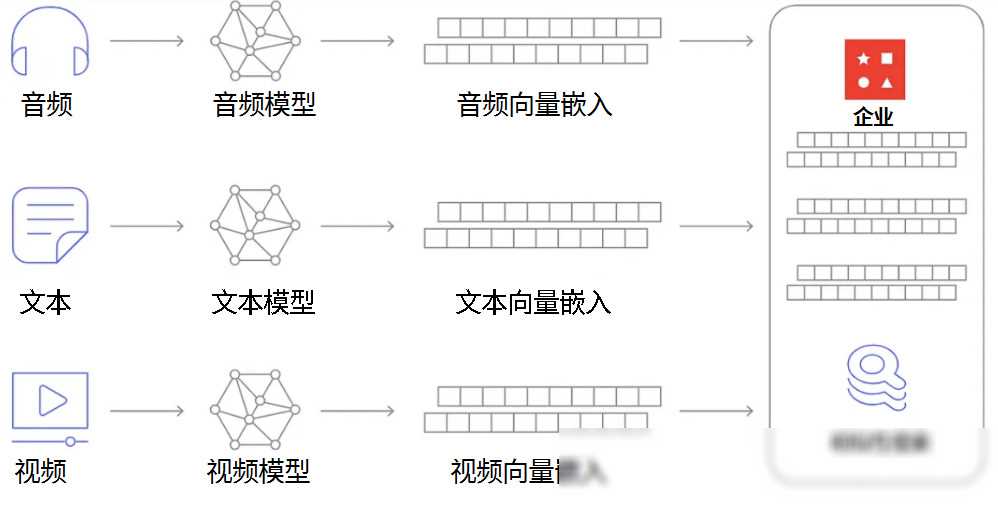
在电影推荐系统中,我们首先需要构建一个包含大量电影信息的数据库。这个数据库可以是从公开数据源(如IMDB)获取的,也可以是自己收集的。然后,我们使用BERT等深度学习模型将这些电影信息转换为向量嵌入。
这些向量嵌入捕捉了电影的深层特征和语义信息,使得我们可以更精确地理解电影之间的相似性和差异性。通过将这些向量嵌入存储在向量数据库中,我们可以高效地执行相似性搜索和推荐任务。
BERT(Bidirectional Encoder Representations from Transformers)是一个强大的深度学习模型,它能够从文本数据中提取出丰富的语义信息。在电影推荐系统中,我们可以使用BERT模型将电影描述、剧情等文本信息转换为向量嵌入。
具体来说,我们首先将电影文本数据输入到BERT模型中,然后提取出模型输出的向量嵌入。这些向量嵌入捕捉了文本的深层特征和语义信息,使得我们可以更准确地理解电影的内容和主题。
为了演示这个过程,我们可以使用Python中的transformers库来加载预训练的BERT模型,并将电影文本数据输入到模型中。然后,我们可以提取出模型输出的向量嵌入,并将其存储在向量数据库中供后续使用。
在构建了电影数据库和向量嵌入后,我们就可以开始构建智能电影推荐系统了。这个系统的核心是利用向量数据库中的向量嵌入来执行相似性搜索和推荐任务。

我们需要设计一个合适的系统架构和流程。这个架构应该包括数据预处理、向量化处理、向量数据库管理和推荐算法等模块。然后,我们需要实现这些模块的具体功能。
在数据预处理阶段,我们需要对电影数据进行清洗和格式化处理,以便后续的向量化处理。在向量化处理阶段,我们使用BERT模型将电影文本数据转换为向量嵌入,并将其存储在向量数据库中。
在推荐阶段,我们可以根据用户的喜好和历史行为,从向量数据库中检索出最相似的电影推荐给用户。这个过程可以通过计算用户喜好向量和电影向量之间的相似度来实现。

为了提高系统的性能,我们还可以使用一些优化技巧,如使用索引结构来加速向量检索过程,或者使用机器学习算法来优化推荐结果。
通过结合BERT模型和向量数据库,我们可以构建一个高效、准确的智能电影推荐系统。这个系统不仅能够理解用户的喜好和历史行为,还能从海量的电影数据中检索出最相似的电影推荐给用户。
随着技术的不断发展,我们可以预见向量数据库和深度学习模型将在电影推荐等领域发挥越来越重要的作用。未来,我们还可以探索更多的技术结合点和创新应用,为用户提供更加个性化、智能化的服务体验。
我们也需要注意到技术的双刃剑效应。在利用技术提升用户体验的也要保护好用户的隐私和数据安全。只有这样,我们才能让技术真正地造福于人类,推动社会的进步和发展。