
数据采集与预处理,第2篇!数据质量提升秘籍!
数据采集与预处理的艺术
在数字时代的浪潮中,数据已经成为推动社会进步和企业发展的核心动力。海量的数据中往往隐藏着各种噪音和冗余信息,如何从中提取出有价值的数据,成为了每一个数据科学家和工程师必须面对的挑战。今天,我们就来聊聊数据采集与预处理的艺术,看看如何通过科学的方法和技术手段,让数据变得更加纯净、更有价值。
一、引言:数据预处理的重要性
在数据驱动的决策中,数据的质量直接决定了分析结果的准确性。而数据预处理,正是保障数据质量的关键步骤。通过数据预处理,我们可以消除数据中的噪音,提取出与关键特征相关的信息,为后续的数据分析和挖掘打下坚实的基础。数据预处理的过程通常包括分段、清洗和特征提取等步骤,每一个步骤都至关重要。
二、数据分段:精准定位关键信息
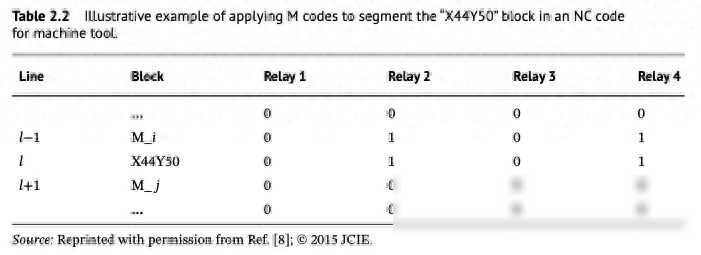
在数据采集的过程中,我们往往会收集到大量的原始数据。并非所有的数据都是有用的,我们需要从中筛选出与我们的分析目标密切相关的部分。这就是数据分段的作用。通过数据分段,我们可以从原始数据中准确地分段出必要的部分,比如从数控(NC)文件中分段出与最终加工精度直接相关的数据片段。
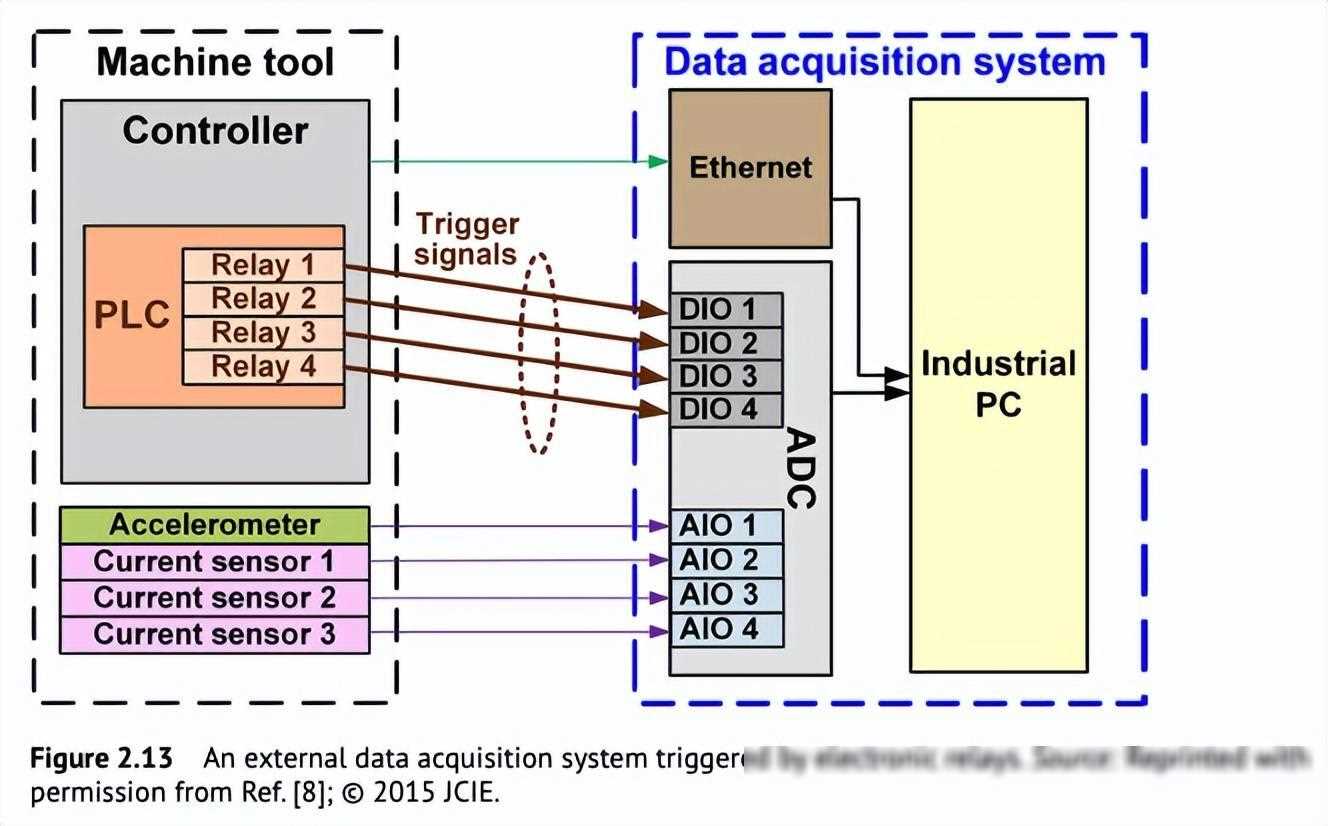
在制造业中,加工过程的数据量往往非常庞大。以数控机床为例,一个典型的加工过程可能需要几分钟甚至几小时,而整个加工过程的数据可能每秒超过100千字节。在这样的情况下,如果直接对所有数据进行分析,不仅会浪费大量的计算资源,而且很难得到准确的结果。因此,我们需要通过数据分段来精准定位关键信息。
为了实现数据分段,我们可以使用一种名为“M代码”的技术。M代码原本用于控制机床的各种设备,但在这里我们将其用于指定NC程序的关键区块。当机床执行到某个预定义的M代码时,会触发一个信号,告诉外部数据采集系统开始或停止收集数据。通过这种方式,我们可以轻松地获取到与最终加工精度直接相关的数据片段。
三、数据清洗:消除噪音,提高信噪比
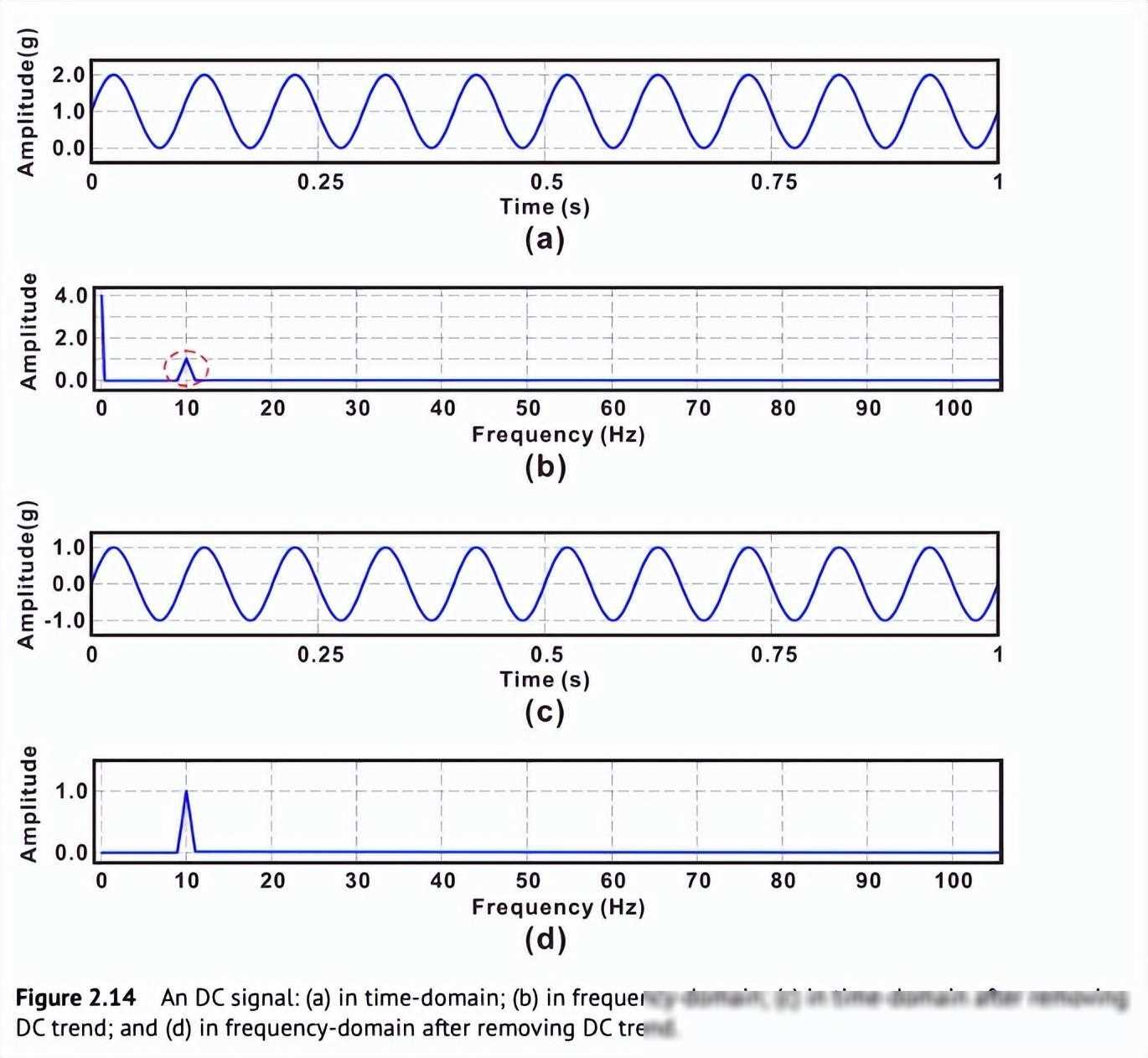
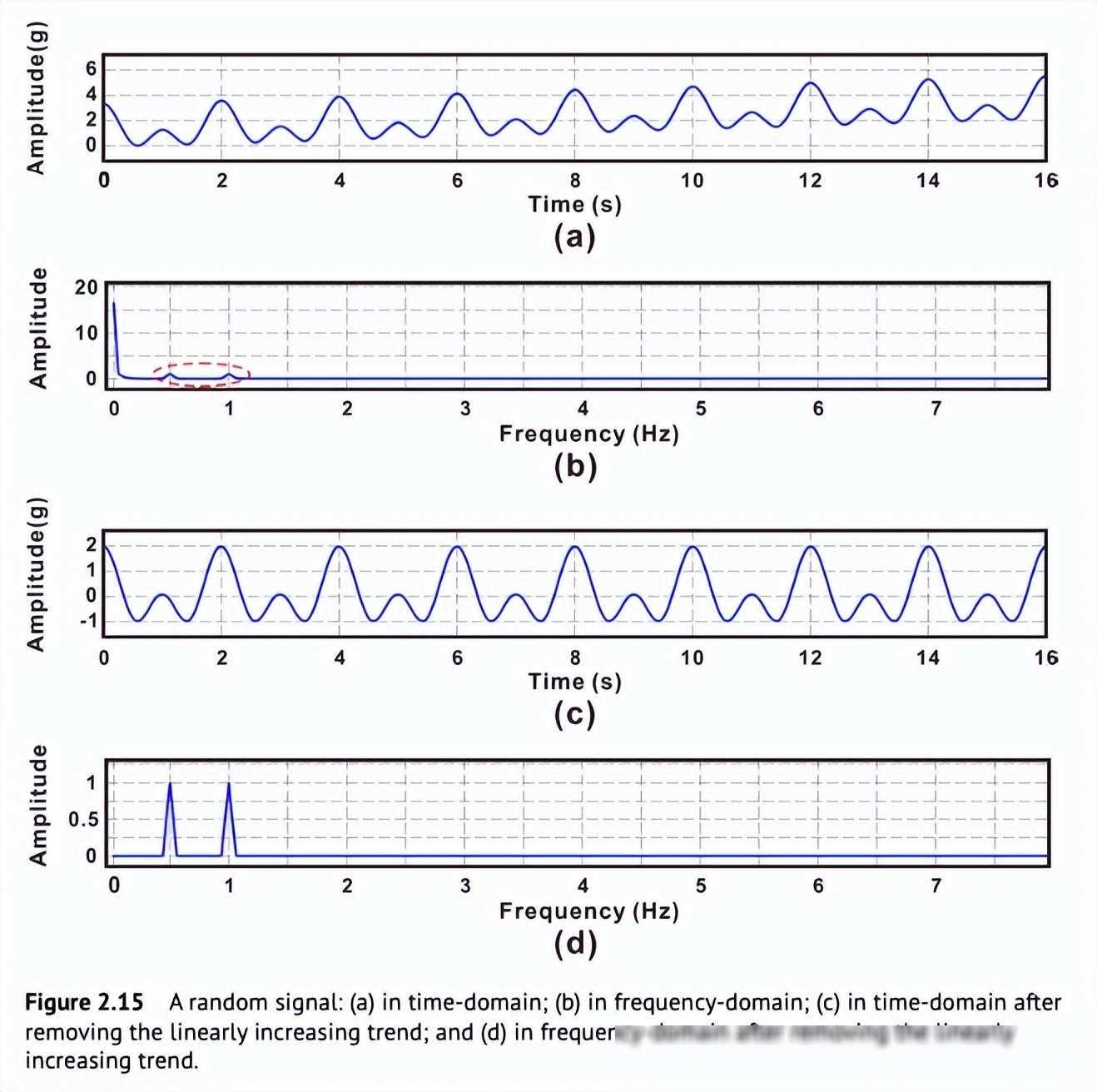
在数据采集的过程中,由于各种因素的影响(如设备故障、传感器误差等),原始数据中往往会包含大量的噪音和冗余信息。这些数据不仅会降低分析结果的准确性,还会浪费大量的计算资源。因此,在数据预处理的过程中,我们需要对数据进行清洗,消除其中的噪音和冗余信息。

数据清洗的方法有很多种,比如趋势去除、小波阈值法等。以趋势去除为例,我们可以通过分析数据的趋势变化,识别出其中的无意义信息(如由设备或环境引起的长期连续增加或减少的特征),并将其从原始数据中去除。这样不仅可以提高数据的信噪比,还可以简化问题模型,提高分析效率。
除了趋势去除外,我们还可以使用小波阈值法等其他时域或频域技术进行数据清洗。这些方法可以根据数据的特点选择合适的阈值进行滤波处理,从而消除噪音和冗余信息。
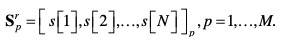
四、特征提取:挖掘数据的深层价值
在数据预处理的过程中,特征提取是一个非常重要的步骤。通过特征提取,我们可以从原始数据中提取出与关键特征相关的信息,并将其转化为适合后续分析和挖掘的形式。这些特征可能包括数据的统计量、形状、纹理等,它们能够反映数据的本质特征和内在规律。

在特征提取的过程中,我们需要根据具体的分析目标和数据特点选择合适的方法。比如对于时间序列数据,我们可以使用滑动窗口、傅里叶变换等方法进行特征提取;对于图像数据,我们可以使用卷积神经网络(CNN)等深度学习模型进行特征提取。
特征提取的结果将直接影响后续分析和挖掘的效果。因此,在特征提取的过程中我们需要注重方法的科学性和合理性,并根据实际情况进行调整和优化。
五、总结与展望
数据采集与预处理是数据分析和挖掘的基础和关键步骤。通过科学的方法和技术手段进行数据预处理,我们可以消除数据中的噪音和冗余信息,提高数据的信噪比和纯度;通过特征提取我们可以从原始数据中挖掘出有价值的信息并将其转化为适合后续分析和挖掘的形式。
随着技术的不断发展和应用场景的不断拓展,数据采集与预处理的技术也在不断更新和完善。未来我们将面临更加复杂和多样化的数据挑战但同时也将迎来更多的机遇和可能。因此我们需要不断学习和探索新的技术和方法不断提高自己的数据预处理能力为数据分析和挖掘提供更加准确和有效的支持。
在这个数字化、智能化的时代里让我们一起携手共进探索数据采集与预处理的奥秘吧!