马斯克重磅开源!Grok大模型震撼登场,3140亿参数史上之最!
在人工智能的浪潮中,我们见证了一个又一个的突破。今天,我们将聚焦在一位科技巨擘马斯克旗下的新成果——开源大模型Grok上。这款拥有3140亿参数的混合专家(MoE)模型,不仅刷新了我们对开源大语言模型的认识,更引领我们迈向了技术的新高峰。
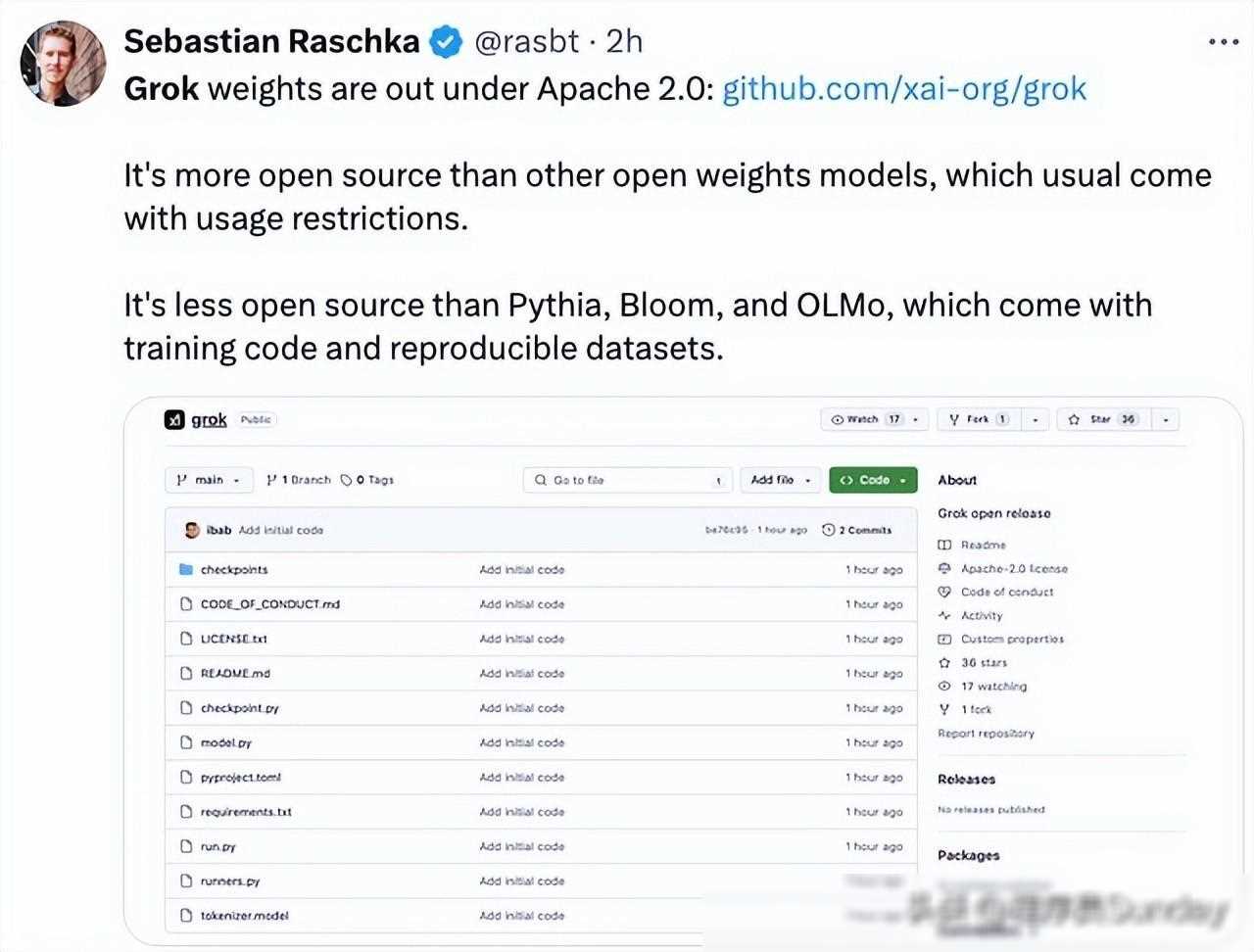
在深度学习领域,大模型一直是研究和应用的热点。然而,高参数、高性能的大模型往往意味着高昂的研发成本和严格的使用限制。而马斯克旗下的xAI公司,却以惊人的魄力,推出了这款史上最大的开源大语言模型——Grok。
Grok的诞生,无疑为开源社区带来了福音。它基于大量文本数据进行训练,没有针对任何具体任务进行微调,这意味着它具有极高的通用性和可扩展性。同时,xAI公司采用了Apache 2.0许可证来开源Grok的权重和架构,这使得任何个人或组织都可以自由地使用、修改和分发Grok,无需担心版权问题。

Grok之所以能够在众多大模型中脱颖而出,除了其庞大的参数量外,更得益于其先进的技术特点。
首先,Grok采用了混合专家(MoE)架构。这种架构通过将多个专家模型组合在一起,每个专家模型负责处理不同的输入数据,从而实现了模型的并行化和高效化。在Grok中,MoE架构使得模型在给定token上的激活权重达到了25%,大大提高了模型的处理能力和效率。
其次,Grok的训练过程也堪称一绝。xAI公司使用了JAX库和Rust语言组成的自定义训练堆栈,从头开始训练Grok。这种训练方式不仅保证了模型的稳定性和可靠性,还使得模型在训练过程中能够充分利用硬件资源,实现高效的训练速度。
此外,Grok的tokenizer词汇大小达到了惊人的131,072,这意味着它能够处理更加复杂和多样的文本数据。同时,Grok还采用了旋转嵌入而非固定位置嵌入的方式,进一步提高了模型的泛化能力和鲁棒性。
作为一款拥有3140亿参数的大模型,Grok的应用前景无疑是非常广阔的。它可以被广泛应用于自然语言处理、机器翻译、文本生成等领域,为人工智能的发展提供强大的技术支持。
以自然语言处理为例,Grok可以通过对海量文本数据的学习和训练,实现对人类语言的深度理解和智能回应。在智能客服、语音助手等场景中,Grok可以为用户提供更加准确、高效的服务体验。同时,在机器翻译领域,Grok也可以凭借其强大的跨语言理解能力,实现更加准确、流畅的翻译效果。
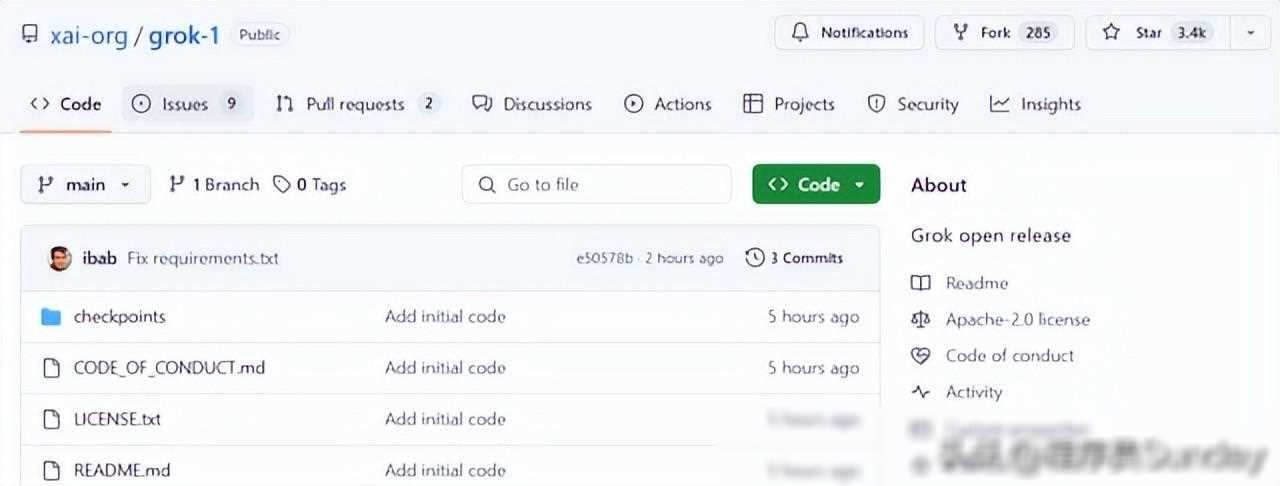
此外,Grok的开源特性也使得它成为了一个绝佳的科研工具。通过研究和改进Grok的模型结构和训练方法,我们可以进一步推动人工智能领域的技术进步和应用创新。
然而,Grok的推出也面临着一些挑战和机遇。
首先,Grok的庞大参数量意味着它需要巨大的计算资源和存储空间来支持其运行和训练。这对于普通用户或小型组织来说无疑是一个巨大的门槛。因此,如何降低Grok的使用门槛和成本,让更多人能够享受到大模型带来的便利和优势,是一个亟待解决的问题。

其次,Grok的开源特性也带来了一些安全风险。由于任何人都可以获取和修改Grok的权重和架构,这可能导致一些不法分子利用Grok进行恶意攻击或滥用。因此,如何保障Grok的安全性和可信度,防止其被恶意利用,也是我们需要关注的重要问题。
然而,正是这些挑战和机遇,使得Grok成为了一个充满活力和机遇的研究领域。通过不断的研究和创新,我们有望解决Grok面临的种种问题,推动人工智能技术的不断进步和应用创新。
总的来说,马斯克开源的大模型Grok无疑为我们带来了一个全新的技术里程碑。它不仅刷新了我们对开源大语言模型的认识,更引领我们迈向了技术的新高峰。在未来,我们有理由相信,随着Grok的不断发展和完善,它将在人工智能领域发挥更加重要的作用,为我们带来更加美好的生活和未来。