
轻松上手!本地运行gpt,简单到飞起!
轻松在本地运行gpt:Ollama让大型语言模型触手可及
随着人工智能技术的飞速发展,大型语言模型(LLM)已经成为我们日常生活和工作中不可或缺的一部分。这些模型通常需要强大的计算资源和网络支持才能顺畅运行。那么,有没有一种方法能让我们在本地电脑上轻松运行这些大型语言模型呢?答案是肯定的,那就是Ollama。
一、Ollama简介

Ollama是一个开源的大型语言模型服务,它提供了类似OpenAI的API接口和聊天界面,使得我们可以非常方便地在本地部署并运行最新版本的GPT模型。不仅如此,Ollama还支持多种大型语言模型,如Llama 2、Mistral、Gemma等,让你可以根据自己的需求选择合适的模型进行部署。
二、Ollama的特点
丰富的模型支持:Ollama不仅支持GPT系列模型,还兼容其他多种大型语言模型。这意味着你可以根据自己的需求和资源情况,灵活选择适合的模型进行部署。

热加载功能:Ollama支持热加载模型文件,这意味着你可以在不重启服务的情况下,轻松切换不同的模型。这一功能大大提高了模型的使用效率和灵活性。
一键安装与部署:Ollama提供了一键安装的模型,使得本地PC上的部署过程变得和Docker Cli一样简单。即使你没有深厚的IT背景,也能轻松完成模型的安装与部署。
友好的Web界面:Ollama提供了一个与本地LLMs聊天的Web界面,让你可以像使用网页版gpt一样与本地模型进行交互。这一设计大大降低了使用门槛,使得更多人能够享受到大型语言模型带来的便利。
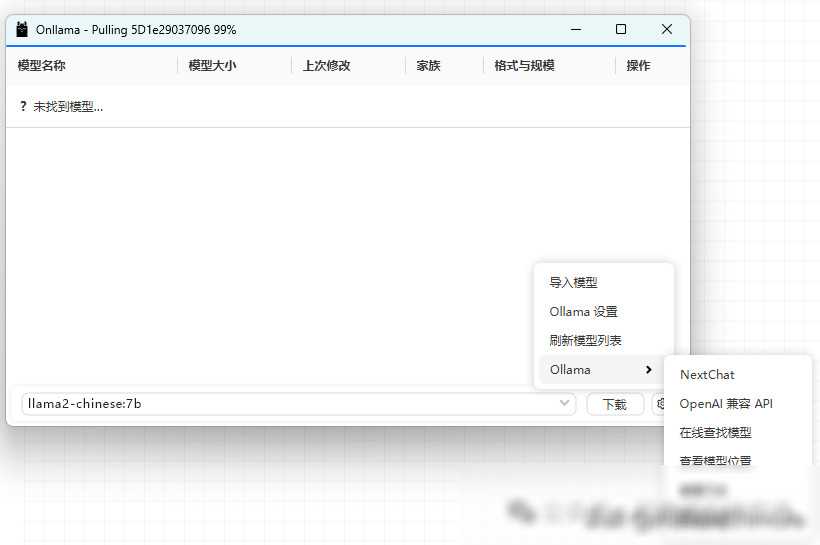
三、如何使用Ollama在本地运行LLM
使用Ollama在本地运行LLM非常简单,只需按照以下步骤操作即可:
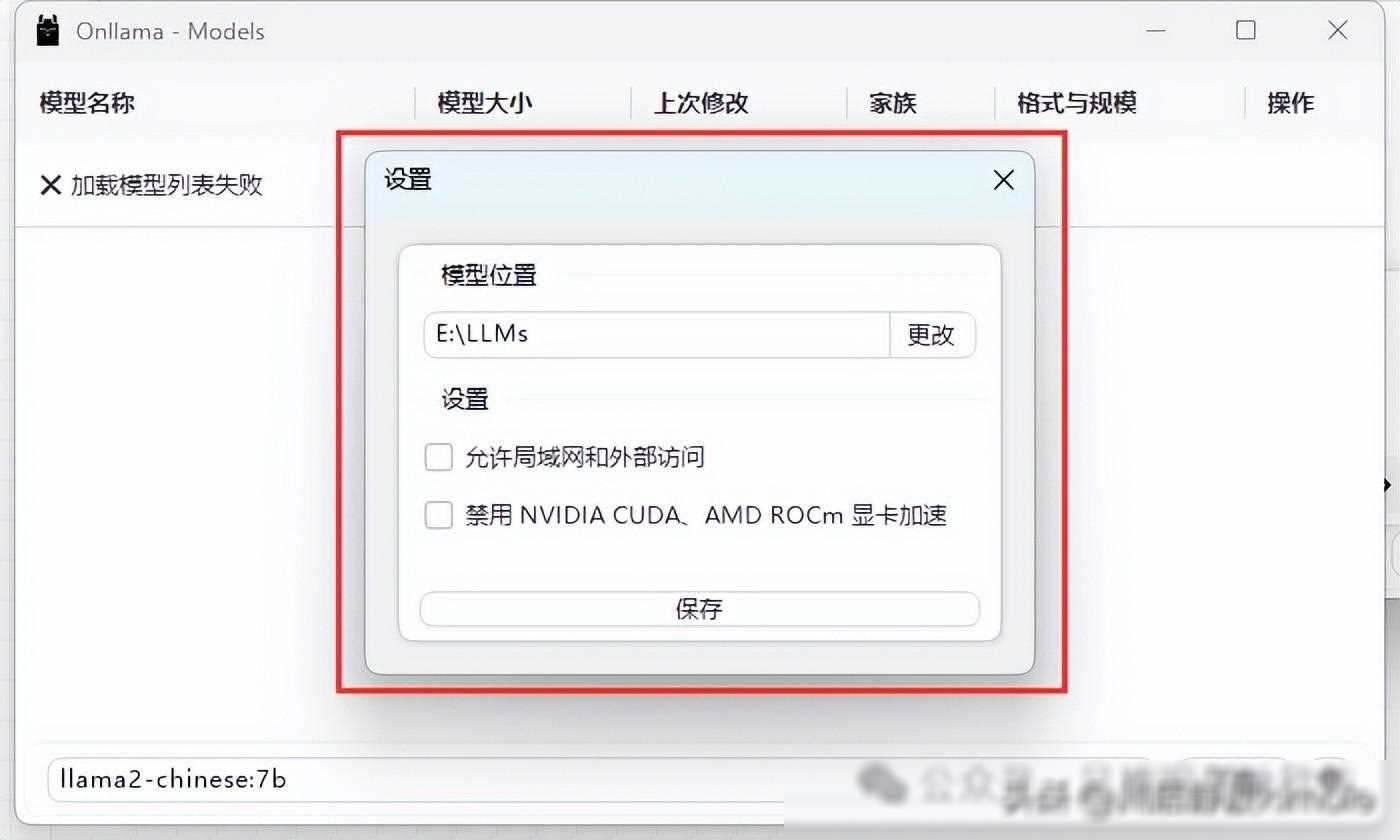
选择并下载模型:你需要在Ollama提供的模型列表中选择一个合适的模型进行下载。例如,如果你对中文处理有较高要求,可以选择Chinese Llama 2 7B这个完全开源、可商用的中文版Llama2模型。此外,Ollama还支持自定义模型下载位置,有效解决了C盘空间不足的问题。
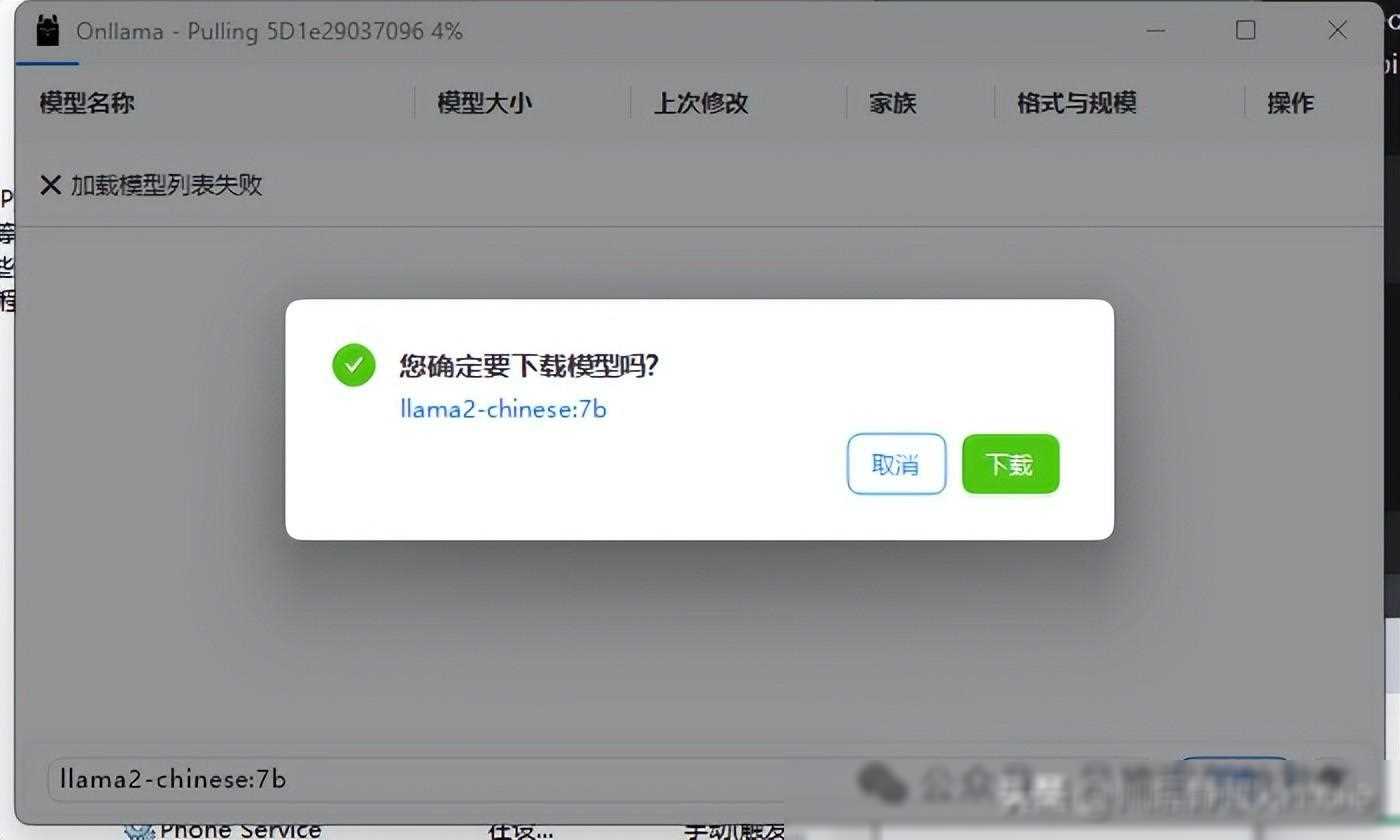
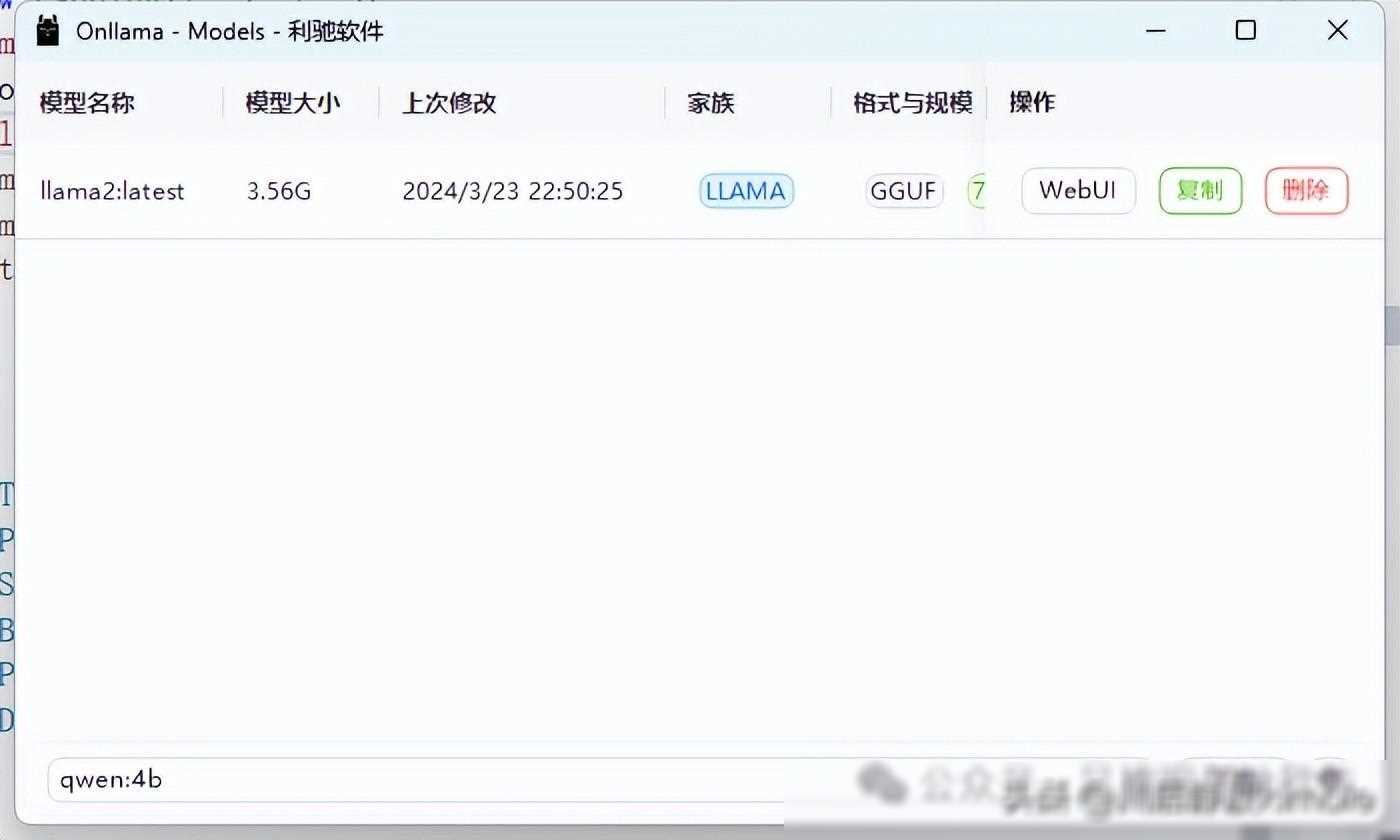
查看本地大模型列表并点击WebUI按钮:下载完成后,你可以在本地大模型列表中看到已下载的模型。点击WebUI按钮,即可启动与模型的交互界面。
开始使用并享受本地LLM服务:现在,你可以像使用网页版gpt一样与本地模型进行聊天了。无论是提问、翻译还是语音识别等任务,本地LLM都能为你提供快速、准确的响应。
四、Ollama的应用场景与优势
离线环境下的语言处理:在一些没有网络或网络环境不稳定的地方,如偏远地区、地下或海上等场所,使用Ollama部署的本地LLM可以确保语言处理的连续性和稳定性。这对于需要实时进行语言处理的应用场景非常有用。
数据隐私与安全:由于所有数据都在本地处理,因此使用Ollama可以有效保护用户的隐私和数据安全。这对于处理敏感信息或进行保密通信非常有利。
定制化与扩展性:Ollama的开源性质使得开发者可以根据自己的需求对模型进行定制和优化。此外,通过结合其他技术和服务,还可以进一步扩展本地LLM的功能和应用范围。
五、结语
Ollama为我们提供了一个在本地轻松运行大型语言模型的解决方案。通过其丰富的模型支持、热加载功能以及友好的Web界面等特性,我们不仅可以降低对网络和计算资源的依赖,还能更好地保护数据隐私和提升处理效率。随着人工智能技术的不断发展,相信Ollama这样的开源项目将在未来发挥更大的作用,推动语言处理技术的进步和创新。