
如何选择LSTM或GRU?从深度学习到实际应用的全解读!
标题:如何选择LSTM或GRU?从深度学习到实际应用的全解读!
亲爱的读者朋友们,伴随着人工智能和深度学习的迅猛发展,很多技术概念接踵而至,让人眼花缭乱。在这其中,长短期记忆网络(LSTM)和门控循环单元(GRU)这两位老将无疑是焦点,它们不仅解决了传统循环神经网络在长序列数据处理中的一些难题,也为无数应用提供了有效的方案。本篇文章将带你深入了解这两者的结构、优劣以及它们在实际应用中的选择要点。
一、引言
在机器学习的领域,处理长序列数据时,传统的循环神经网络(RNN)往往面临着令人头疼的梯度消失问题。这是什么情况呢?简单来说,当输入序列较长时,信息流经过多层神经网络处理后,更新的梯度会逐渐减小,导致网络失去记忆之前的信息。这就像一个人讲述很久以前的故事,记忆的细节逐渐模糊。因此,针对这种情况的研究显得尤为重要。LSTM和GRU正是在这样的背景下应运而生,旨在维护长期依赖的信息,从而提升深度学习模型在处理复杂序列数据时的能力。
二、LSTM的结构与功能
LSTM的基本构成
LSTM是循环神经网络的一种特殊形式,具备三个关键的“门”:输入门、遗忘门和输出门。这些门的设计巧妙,决定了信息的流通与变更。Input Gate(输入门)负责判断新信息的重要性,以决定哪些信息需要被存储;Forget Gate(遗忘门)则负责决定哪些旧信息由于不再重要而被丢弃;而Output Gate(输出门)则控制了从细胞状态输出隐藏状态的信息量。
状态管理
LSTM不仅有多个“门”,还引入了两种状态:隐藏状态和细胞状态。隐藏状态包含最新的信息,是网络决策的基础,而细胞状态则是一种长期记忆,承载了网络在长序列输入中的历史信息。这一切看似复杂,但实际上正是这种机制,使得LSTM能够在长序列中捕捉到细致入微的信息并进行有效的传递。
性能影响因素
这种设计的确让LSTM的参数数量大大增加。根据研究,LSTM的参数量往往是同类模型的几倍,这就意味着需要更多的计算资源和时间,加大了模型训练的复杂性。比如,使用Keras训练LSTM模型时,通常需要更长的时间来优化参数,因为它需要同时维护和更新更多的 Gates 和状态变量。
三、GRU的结构与功能
GRU的基本构成
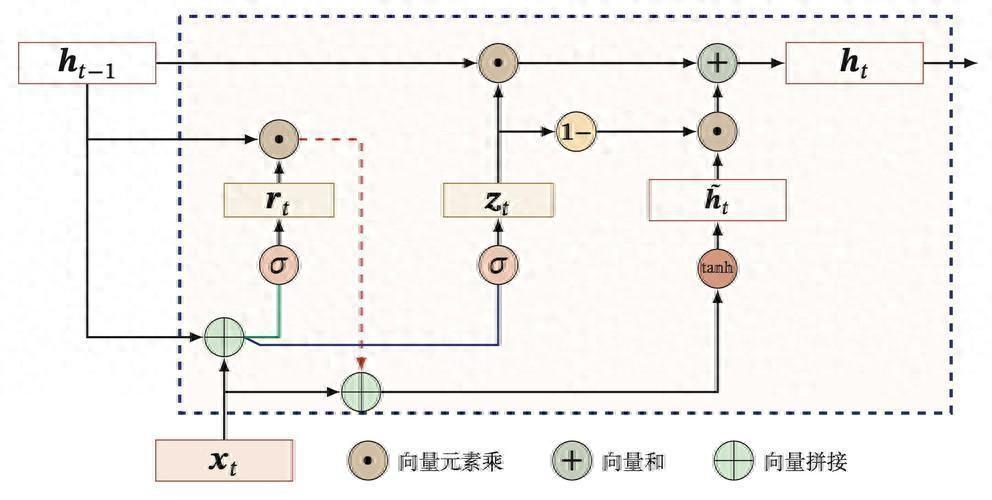
GRU作为LSTM的简化版本,极大地降低了结构的复杂性。它融合了LSTM的功能,但仅使用了两个“门”:更新门和重置门。Update Gate(更新门)决定了多少过去的信息需要保留,而Reset Gate(重置门)则决定了需要遗忘的信息。这种结构让网络在一定程度上保持了LSTM的优良性能,同时减少了计算的负担。
状态管理
GRU只维护一种状态,即隐藏状态,省略了细胞状态的概念。这种设计在处理短序列或小型数据集时尤为有效。比如在需要快速模型训练的情况下,例如图像描述或情感分析任务,使用GRU的模型往往能更快达到收敛。此外,由于参数少,GRU还可以在内存使用上更加高效,避免了系统资源的浪费。
性能影响因素
因为GRU的参数较少,通常在处理较小的数据集时,训练时间会显著缩短。有研究表明,在一些特定情境下,GRU甚至表现出了比LSTM更快速的收敛能力,这为开发者提供了更多的选择。例如,在Twitter数据情感分析等短文本任务中,使用GRU的模型往往能快速给予满意的结果。
四、LSTM与GRU的比较
结构上的关键区别
LSTM和GRU在结构上的主要区别在于“门”的数量和“状态”的维护。LSTM配备三个门,而GRU仅有两个门;LSTM维护两种状态(隐藏状态和细胞状态),而GRU只维护一个。这使得GRU在构建和调优模型时显得更加轻松,尤其是在不需要捕捉复杂时间依赖的情况下,选择GRU无疑可以节省大量的开发时间。
计算复杂性的差异
由于LSTM需要维护更多的门和状态,计算资源的需求自然也水涨船高。在实际应用中,开发者可能会发现LSTM模型在执行时的计算时间明显高于GRU,尤其是在处理大规模数据集时。例如,训练LSTM模型时,通常需要预留更多的GPU计算资源,以保证训练的速度和性能。
训练时间与收敛速度
GRU因其减少的门控结构,通常在较小数据集上训练时表现更佳。在Kaggle等数据科学竞赛中,更便于快速模型调整的特性使开发者可以在短时间内测试多种模型,帮助他们找到最快且有效的解决方案。要实现最佳性能,数据集的规模和任务类型就显得尤为重要。
五、实际应用中的选择
选择LSTM的情况
在面对大型数据集或需要捕捉复杂的长序列关系时,LSTM无疑是更合适的选择。在自然语言处理(NLP)任务中,比如机器翻译或长文本生成,LSTM能够有效捕捉上下文中的依赖关系,保证生成内容的连贯性。例如,Google的神经机器翻译系统就广泛运用了LSTM技术,提供了更加准确和自然的翻译结果。
选择GRU的情况
对于小型数据集或希望快速得到结果的场景,GRU表现得更为出色。在实时分类系统中,速度是至关重要的。比如在在线聊天机器人或流量监测中,GRU能够以较少的延迟完成任务,提高用户体验。实际案例表明,使用GRU训练的模型,在处理短句或近实时数据时,能够显著提高响应速度。
实际案例分析
根据某项研究,当在情感分析数据集上测试LSTM与GRU模型时,结果显示GRU在80%时的准确率与LSTM相差无几,但训练时间却缩短了将近40%。这样的效率提升,让开发者在确保模型性能的同时,充分利用了时间与资源。
六、总结与展望
这个领域的发展趋势说明,LSTM和GRU均有其各自的优势和用途。随着技术的不断进步,越来越多的新兴网络架构应运而生,为开发者提供了更丰富的选择。未来随着AI需求的多样化和复杂化,真正适合使用的模型也越来越倾向于根据具体任务进行选择,而不是一味追求某一技术的优越性。对于开发者而言,了解这些基础知识和应用场景至关重要,便于在实际工作中做出更科学的决策。
欢迎大家在下方留言讨论,分享您的看法!