
CVE复现揭秘:栈溢出漏洞利用全攻略!
从CVE复现看栈溢出漏洞利用
在软件安全的领域里,栈溢出漏洞(Stack Overflow Vulnerability)一直是一个热门而又严峻的话题。最近,我深入研究了两个经典的栈溢出漏洞案例——CVE-2017-9430和CVE-2017-13089,希望通过这两个案例,为大家揭开栈溢出漏洞的神秘面纱,同时分享一些防范和应对这类漏洞的经验。
一、栈溢出漏洞概述
在了解具体案例之前,我们先来简单回顾一下栈溢出漏洞的基本概念。栈溢出,简而言之,就是当程序向栈中写入数据时,超出了栈分配的空间大小,导致栈中的其他数据被覆盖。如果这些数据恰好是程序的关键控制信息,如返回地址,那么攻击者就有可能控制程序的执行流程,进而执行恶意代码,造成严重的安全问题。

二、CVE-2017-9430:DNSTracer中的栈溢出漏洞
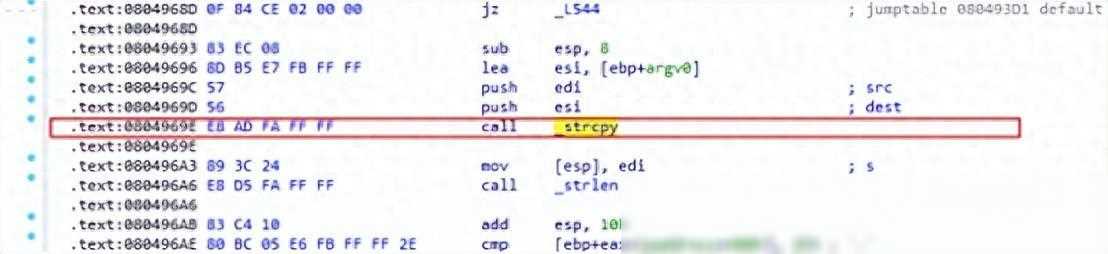
DNSTracer是一款网络诊断工具,用于追踪DNS查询的路径。在其1.9及之前版本中,存在一个基于堆栈的缓冲区溢出漏洞。当程序处理命令行参数时,由于使用了不安全的strcpy函数,没有对参数长度进行检查,导致攻击者可以通过构造恶意命令行参数来触发栈溢出。
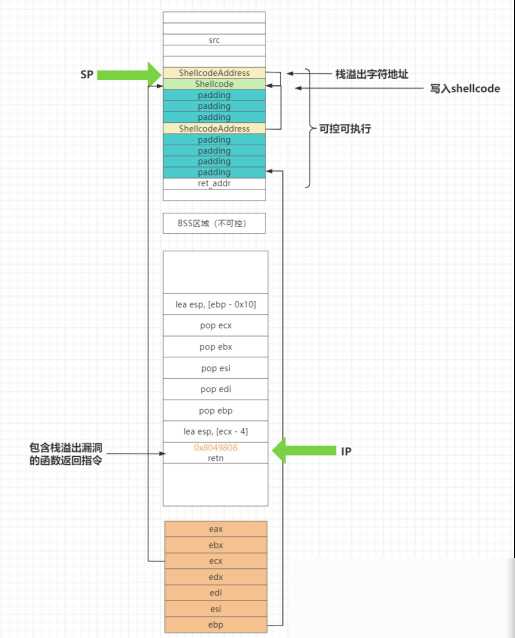
在复现这个漏洞的过程中,我首先关闭了地址空间布局随机化(ASLR)、位置无关可执行(PIE)、金丝雀保护(Canary)、重定位只读保护(RELRO)以及数据执行保护(NX)等安全缓解机制,以便更清晰地观察漏洞的利用过程。通过精心构造的输入数据,我成功地覆盖了程序的返回地址,并指向了预先准备好的Shellcode,从而获得了系统的shell权限。
在复现过程中,我也遇到了一些有趣的现象。我发现,直接覆盖返回地址并不能总是成功获得shell权限。通过深入分析汇编代码,我发现栈指针(esp)在处理返回地址之前被改变了。这个改变是由ecx寄存器的值决定的,而ecx的值又是从栈中弹出的。这意味着,要成功利用这个漏洞,我们不仅要覆盖返回地址,还要精确控制栈中的数据,使得ecx-4处的地址正好是我们要跳转的Shellcode的地址。
这个过程虽然复杂,但却展示了栈溢出漏洞利用的精巧之处。它要求攻击者具备深厚的编程功底和对系统底层机制的深入理解。这也提醒我们,在编写代码时,一定要谨慎使用类似strcpy这样的不安全的字符串操作函数,避免类似漏洞的产生。
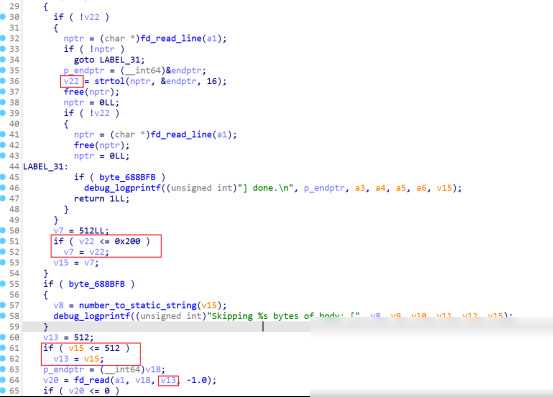
三、CVE-2017-13089:wget中的栈溢出漏洞
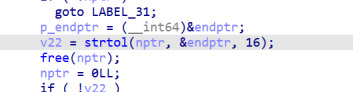
wget是一款常用的命令行下载工具。在处理HTTP重定向时,wget的http.c:skip_short_body()函数中存在一个栈溢出漏洞。当程序读取HTTP响应块的大小时,由于使用了strtol函数但没有进行负数检查,导致攻击者可以构造恶意的HTTP响应,使得程序读取一个巨大的负数作为块长度。由于这个长度被传递给了一个无符号整数参数的函数fd_read(),导致实际读取的长度完全由攻击者控制,从而触发了栈溢出。
在复现这个漏洞时,我发现关闭ASLR等缓解机制同样重要。即使在关闭了这些机制的情况下,栈地址的偏移仍然是一个需要注意的问题。由于操作系统的调度和内存管理的不确定性,栈地址在每次程序运行时都可能发生变化。这意味着,即使我们构造了一个看似完美的利用代码,也可能因为栈地址的偏移而无法成功执行。
为了解决这个问题,我们可以采用一些技术来稳定栈地址。例如,通过精心构造输入数据来触发特定的内存布局,或者使用一些高级的调试技巧来固定栈地址。这些方法都需要对系统底层机制有深入的了解和实践经验。
四、栈溢出漏洞的防范与应对

通过上面两个案例的分析,我们可以看出栈溢出漏洞的严重性和复杂性。那么,如何防范和应对这类漏洞呢?以下是一些建议:
使用安全的字符串操作函数:避免使用strcpy、sprintf等不安全的字符串操作函数,改用strncpy、snprintf等安全的替代品。这些函数会检查目标缓冲区的大小,防止溢出发生。
启用安全缓解机制:如ASLR、PIE、Canary、RELRO和NX等安全缓解机制可以有效降低栈溢出漏洞的利用成功率。在编写软件时,应尽量启用这些机制。
输入验证和过滤:对用户的输入进行严格的验证和过滤,防止恶意输入触发漏洞。例如,可以限制输入的长度、格式和内容等。
代码审计和漏洞扫描:定期对代码进行审计和漏洞扫描,及时发现和修复潜在的栈溢出漏洞。可以使用一些自动化的工具来帮助完成这项工作。
安全培训和意识提升:加强对开发人员的安全培训和意识提升工作,让他们了解栈溢出漏洞的危害和防范方法。也要提高用户