
深度解析WebMagic爬虫框架:轻松入门的数据抓取秘籍
深度解析WebMagic爬虫框架:轻松入门的数据抓取秘籍
亲爱的读者朋友们,今天我们将一起深入探索一个备受开发者喜爱的工具——WebMagic。这不仅是一个无须复杂配置的爬虫框架,更是让初学者轻松上手的数据抓取利器。接下来,我们将逐一解析这个框架的核心结构、功能及使用技巧,并结合实际案例,让你在掌握 WebMagic 的使用过程中,更加得心应手。
一、WebMagic的基本介绍
1.1 WebMagic的定义与特点
WebMagic是一个用于爬虫开发的框架,旨在简化爬虫的开发流程。无论你是刚刚接触爬虫的小白,还是经验丰富的开发者,都能在这个框架中找到适合自己的功能。相对于其他复杂的爬虫工具,WebMagic提供的灵活API,使得只需编写少量代码,就可以快速实现一个爬虫。简单、易用的特点使其在GitHub上获得了超过11.4K的Star,成为开发者心目中的“新宠”。
1.2 目标读者与使用提示
无论你是学生、程序员,还是数据分析师,WebMagic都能为你在数据抓取领域提供很多帮助。在开始使用之前,请务必遵循爬虫的法律法规,切忌非法使用爬虫!在实际开发中,合法、合规的使用数据能让你的工作更加顺利且富有成效。
1.3 文章结构概述
文章将多个重要方面拆解,逐步展开,包括WebMagic的特性、架构组成及使用指南等。每个部分都会搭配生动的实例,确保您在阅读的过程中,能够找到清晰的指导和实操的思路。
二、WebMagic的核心特性
2.1 完全模块化设计
WebMagic采用的是模块化设计理念。每个功能都被独立成模块,这不仅增强了代码的可读性,还大大提高了开发的灵活性。举个例子,想要修改爬虫的某一部分逻辑时,无需重构整个代码,只需针对特定模块进行更改,节省了时间和精力。
模块间的高度解耦也为团队协作提供了保障。在不同的功能开发者之间,可以划分任务,快速推进项目。例如,一个团队可以专注于模块化的Downloader,另一个团队则开发PageProcessor,彼此不干扰。这种分工合作的方式,常常让许多项目的完成效率大幅提升。
2.2 灵活的API
WebMagic的API设计经过精心打磨,致力于提供简单、直观的接口。通过POJO(Plain Old Java Object)和注解的方式,可以让开发者像搭积木一样搭建爬虫。在没有繁琐配置的情况下,开发者可以专注于业务逻辑,而不是环境配置。
在实际应用中,这样的设计给许多新手带来了极大的便利。不再需要花费大量时间去理解复杂的框架结构,只需几行代码,就能让你的爬虫跑起来,比如:
```java
public class MyPageProcessor implements PageProcessor {
public void process(Page page) {
// 添加抓取逻辑
}
}
```
通过这种灵活的接口,开发者的思维能够得到最大程度的解放,专注于解决真正的问题。
2.3 重要功能支持
WebMagic提供多线程和分布式爬虫的功能,这意味着你可以在短时间内抓取大量数据。此外,支持JS动态渲染的页面,让很多现代网站不会再对数据抓取形成屏障。这种设计对于需要抓取大量数据的项目尤为重要,有助于提高项目的整体效率。
可以通过配置多线程同时抓取多个页面,大幅提高抓取速度。你可能会问,这个功能具体如何实现?很简单,只需在Spider中设置线程数量即可,代码如下:
```java
Spider.create(new MyPageProcessor())
.thread(5) // 设置线程数为5
.start();
```
这样的能力,对于那些对时效性有要求的数据抓取任务,不容小觑。
三、WebMagic的架构组成
3.1 四大核心组件分析
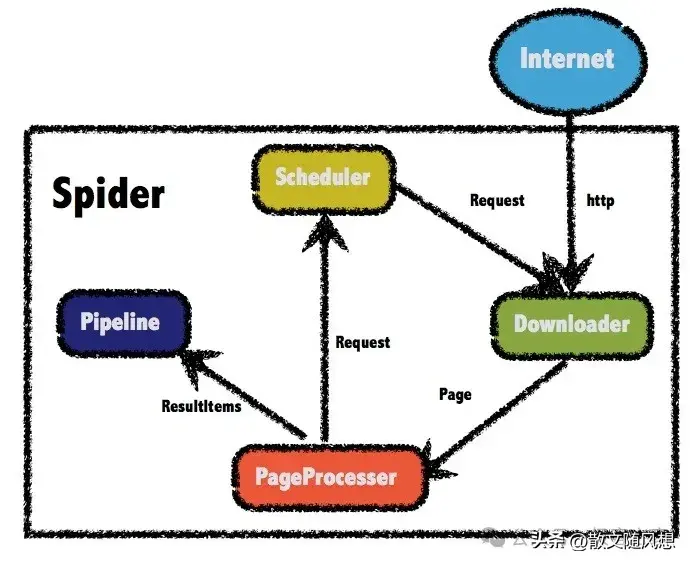
WebMagic的成功离不开它清晰明了的架构,主要由四大组件构成:Downloader、PageProcessor、Scheduler和Pipeline。
3.1.1 Downloader:下载功能
Downloader模块负责从网络上下载页面内容,支持HTTP及HTTPS协议。这个过程中可以添加请求头、设置代理等,有助于规避一些反爬机制。开发者可以自定义下载的行为,灵活性颇高。
3.1.2 PageProcessor:处理逻辑
PageProcessor是爬虫的核心所在,负责解析下载的内容并提取所需的数据。编写处理逻辑时,可以通过链式调用的方式简化代码,增加可读性。例如,使用XPath、CSS选择器等方式灵活提取数据,提升了工作效率。
3.1.3 Scheduler:管理任务
Scheduler模块的作用是管理要抓取的请求队列,实现任务的调度管理。WebMagic自带的是优先级队列,能够保证重要的请求先被处理。例如,在处理网页时,可以设定哪些内容需要优先抓取,确保重要信息不会被遗漏。
3.1.4 Pipeline:数据持久化
在数据抓取完成后,Pipeline模块负责将数据持久化到指定的存储中。WebMagic默认提供了将数据输出到控制台的功能,你也可以自定义将数据存储到数据库、文件或其他存储介质中。以下是一个示例,将数据保存到MySQL数据库中:
```java
public class MySQLPipeline implements Pipeline {
public void process(ResultItems resultItems, Task task) {
// 保存到数据库逻辑
}
}
```
3.2 Spider类的作用
Spider类如同一位指挥家,协调着四大组件之间的配合。使用Spider的API,你可以轻松配置抓取策略、参数等,快速启动整个爬虫。这种设计不仅能够保证各个组件高效合作,还能够在需要调整时,快速反应。
四、WebMagic的使用指南
4.1 Maven依赖管理
在使用WebMagic之前,通过Maven管理项目依赖,是一个高效且便捷的方式。在项目的pom.xml文件中,添加WebMagic的依赖即可。需要注意的是,WebMagic使用的是slf4j-log4j12作为日志实现,因此如果你已经有自己的日志实现,需在项目中去掉此依赖。
以下是一个示例依赖配置:
```xml
```
这样配置后,就可以飞速引入WebMagic的核心功能,保持项目的整洁与高效。
4.2 定制PageProcessor的实用方法
PageProcessor是你实现抓虫逻辑的地方,编写较为复杂的抓取逻辑时,设计一个属于自己的PageProcessor显得尤为重要。在编写时,考虑到未来可能需要抓取的不同网站,留有扩展的余地将会是一个明智的选择。
下面是一个实际的代码示例,通过抓取OSC博客来演示如何实现PageProcessor:
```java
public class MyOSCPageProcessor implements PageProcessor {
public void process(Page page) {
page.addTargetRequests(page.getHtml().links().regex("https://osc.cn/article/.").all());
page.putField("title", page.getHtml().xpath("//h1/text()").toString());
page.putField("content", page.getHtml().xpath("//div[@id='content']/text()").toString());
}
}
```
这个示例中,我们使用了正则表达式来抓取符合特定条件的链接,并将提取到的标题和内容保存。这种模块化的代码结构,极大提高了可读性和可维护性。
五、执行与结果展示
5.1 Spider的执行入口
Spider是启动爬虫的入口,通过配置相关参数可以来实现不同的抓取需求。以下是如何创建和启动Spider的示例:
```java
Spider.create(new MyOSCPageProcessor())
.addUrl("https://osc.cn")
.thread(5) // 设定抓取的线程数
.run();
```
通过addUrl方法来指定起始的抓取链接。万事俱备后,只需调用run方法,Spider就会在后台自动进行数据抓取,结果将通过Pipeline模块进行处理和持久化。
5.2 Pipeline的结果输出
在数据被抓取并处理后,结果会通过Pipeline进行输出,开发者可自定义输出到各种数据存储。WebMagic默认提供了ConsolePipeline,简单明了,适合快速验证抓取效果。当你在控制台中看到数据输出时,可以说一声“耶”,你的爬虫终于成功了。
如果需要将数据写入文件或数据库,只需实现相应的Pipeline接口并将其传入Spider即可。例如,将数据写入文件的Pipeline实现:
```java
public class FilePipeline implements Pipeline {
public void process(ResultItems resultItems, Task task) {
// 写入文件逻辑
}
}
```
然后在Spider的配置中加入:
```java
Spider.create(new MyOSCPageProcessor())
.addPipeline(new FilePipeline())
.run();
```
这种灵活性无疑为开发者提供了更多选择,让他们可以在不同场景中灵活运用。
WebMagic的魅力在于它的简洁与实用,特别适合初学者和中小型项目的快速开发。如果你在爬虫的道路上苦苦挣扎,不妨试试这个框架。欢迎大家在下方留言讨论,分享您的看法!