
数据分析黑科技:如何用DBSCAN算法识别异常值?
数据分析黑科技:如何用DBSCAN算法识别异常值?
亲爱的读者朋友们,今天我们将深入探讨一个非常重要的话题,那就是在大数据时代,如何通过DBSCAN算法来有效识别和剔除数据集中的异常值。随着数据量的激增,如何保证数据的质量成为了亟待解决的挑战。而DBSCAN算法,凭借其独特的聚类方式,成为了数据科学家们手中的一把利器。
一、大数据时代的数据挑战
数据质量的重要性
在当今这个信息爆炸的时代,企业和组织越来越依赖数据驱动决策。然而,获取的数据往往存在很多问题,尤其是数据的质量和完整性。一项调查显示,大约60%的企业在数据分析时遭遇过数据质量问题,这直接导致他们的决策失误。数据完整性对分析的影响不容小觑,错误的或缺失的数据会导致错误的分析结果,从而影响公司的战略决策和市场反应。
异常值导致的分析偏差,更是数据分析中的“杀手”。异常值通常是指与大多数数据显著不同的数据点。例如,如果某商品的销售额在某个月暴增,这可能并不意味着真实情况,而是由于数据错误或市场波动等造成的。因此,及时发现并处理这些异常值,可以有效提升数据分析的准确性和研究结果的可靠性。
异常值的识别与处理
异常值的定义在不同领域可能存在一定差异,但通常被认为是那些偏离正常数据范围的数据点。在数据科学的世界中,异常值的存在会直接影响模型的训练,造成算法预测结果的失真。一项研究显示,未处理的异常值可能导致模型的准确率降低高达30%,这无疑是一个相当可观的数字。因此,处理异常值的重要性不言而喻。对异常值的有效识别和处理不仅是数据清洗的必要步骤,也是确保模型普适性和可靠性的关键。

二、DBSCAN算法概述
DBSCAN算法简介
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法。与许多传统聚类算法不同,DBSCAN并不需要预先指定簇的数量,而是根据数据点周围的密度来进行聚类。这使得DBSCAN在面对具有不规则形状和大小的数据集时显示出其独特的优势。
核心点、边界点与噪声点的定义是DBSCAN的基础。在DBSCAN中,根据密度分布将数据点划分为三类:核心点(Core Point)、边界点(Border Point)和噪声点(Noise Point)。这使得算法不仅能有效地进行聚类,还能够识别并处理数据中的异常值和噪声。
DBSCAN的关键参数
在DBSCAN算法中,有两个关键参数需要设置:eps(ε)和min_samples。前者定义了一个数据点的邻域范围,后者则是决定一个点是否为核心点的最小点数。这两个参数的设置直接影响到聚类效果的好坏。比如,如果在数据集较为密集的区域选择了一个较大的eps值可能会将多个分散数据误判为同一类,而较小的eps值可能会导致实际所属的簇被错误地划分为多个簇。因此,如何合理选择这两个参数在进行DBSCAN分析时显得尤为重要。
DBSCAN的分类及示意图
DBSCAN通过分析数据中的点的密度,揭示出各种聚类模式。通过图示化的方式(如图1),我们能够清晰地看到核心点、边界点和噪声点之间的关系,帮助我们理解数据结构。这不仅让初学者能够直观感受聚类过程,也便于在实际应用中验证模型的有效性。
三、DBSCAN算法实施步骤
数据标准化
在应用DBSCAN算法之前,进行数据标准化是不可或缺的一步。标准化的目的在于消除不同特征间的量纲差异,使所有数据能够以统一的标准进行比较。一般来说,通过计算数据的均值(μ)和标准差(σ),可以将数据转换为均值为0,标准差为1的标准正态分布。标准化后的公式为:z = (x - μ) / σ。
这一过程不仅能提高模型的收敛速度,还有助于避免某些特征对聚类结果的影响过大,从而提高最终结果的稳定性。
计算eps邻域
选择一个数据点后,接下来需要计算其eps邻域,即确定哪些数据点在给定的距离范围内。这一步通常涉及到计算每个数据点与其他数据点的距离(可以使用欧几里德距离公式),并找出距离小于或等于eps的所有点。值得注意的是,这一步骤对于DBSCAN的最终效果至关重要,因为所有的聚类信息都基于这些邻域的计算。
形成簇的条件
在确定了每个点的邻域后,需要根据邻域内的点数量判断该点是否能形成一个聚类簇。如果某个数据点的邻域内包含的点数超过或等于min_samples的值,那么这个点就被判定为核心点。这时,聚类就可以形成;如果邻域点数不足,则该点会被视为噪声点。
扩展聚类
算**对每个新加入的点进行扩展簇的操作。如果一个点是核心点,则需要继续扩展周围的所有邻域点,重复上述过程。直到没有新的点能够加入为止。这种方式确保了所有密集区域都被考虑在内,而不是限于某些特定的聚类。
迭代处理所有数据点
这一阶段的关键在于确保所有数据点都被访问过。以一组数字为例:数据1,2,2,5,7,8,10,9,11,15,16,17,20,设定eps=2,min_samples=2。经过DBSCAN的处理后,可以划分出3个聚类簇:簇1:[1,2,2]、簇2:[5,7,8,10,9,11]、簇3:[15,16,17],以及一个异常值20。
四、DBSCAN在实际应用中的效果
实际数据集示例
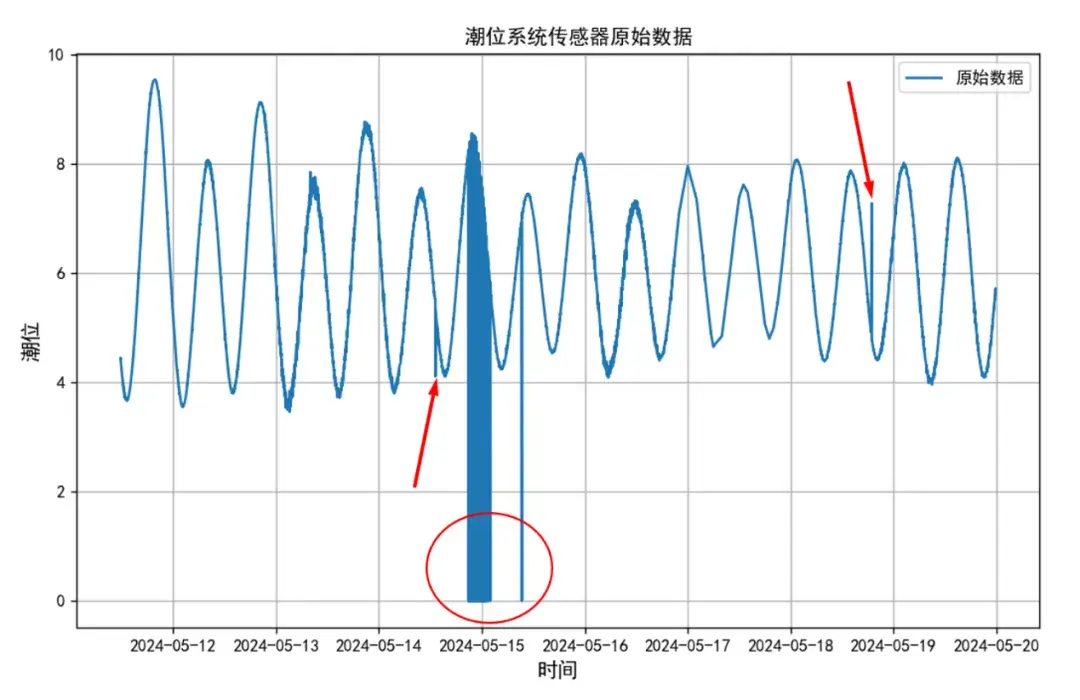
为了更详细地说明DBSCAN算法的实用性,我们以某海上项目潮位传感器的数据为例,该数据集跨度约为2024年5月1日至2024年5月20日。在图2中,原始数据清晰地展示了潮位传感器的读数,其中红色标注部分即为异常值。可以看出,这些异常值可能是因天气变化、设备故障等原因造成的问题,若不加处理,将直接影响后续分析的结果。
数据处理结果的可视化

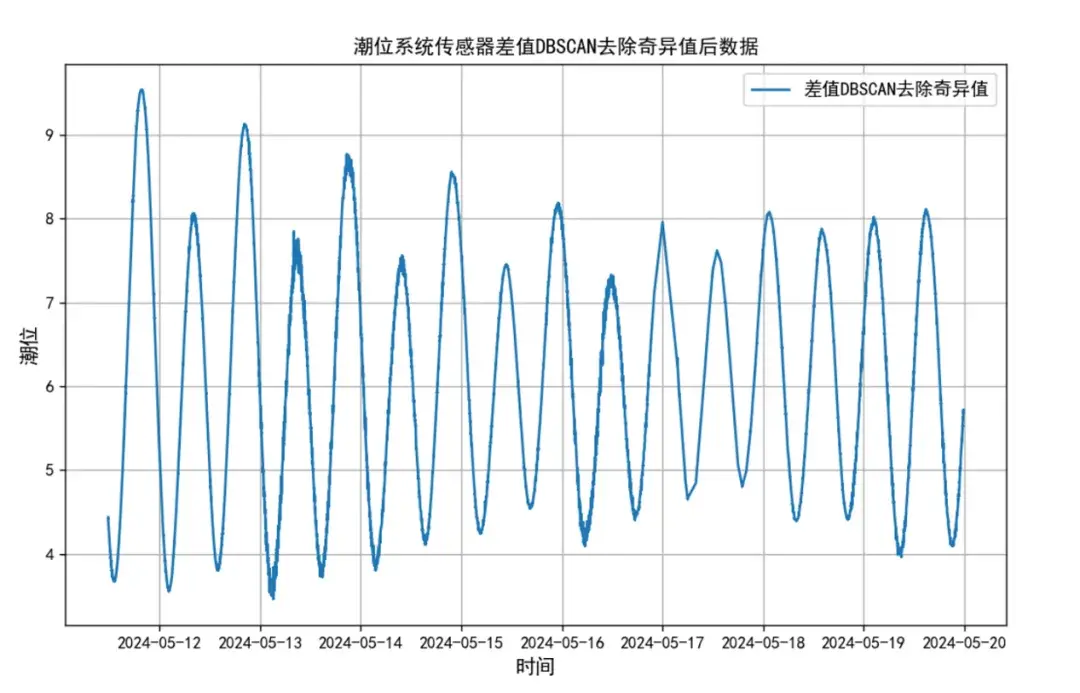
通过DBSCAN算法去除异常值后,处理结果如图3所示。可以看到,经过DBSCAN处理后,大部分异常值被成功剔除,但仍有两个异常值未被过滤。这是因为在设置参数时,eps=0.1,min_samples=30,导致部分接近正常值的数据未能被认定为异常,需进一步审视数据质量。
差值算法的运用
为了更加精准地去除异常值,我们结合了差值算法。在这一过程中,通过计算序列中当前元素与前一个元素之间的差值,当差值超出定义的阈值时,就判定该元素为异常值。经过这一处理后,在图4中所示的结果显示,异常值已经成功剔除,整体数据的显示效果显著提升。
五、DBSCAN的优势与劣势
DBSCAN的优点
DBSCAN算法具有多个显著优点,例如:
- 自动确定聚类数量:与需要预先定义簇数量的K-means等算法不同,DBSCAN可以根据数据的密度自动进行聚类,增强了算法的灵活性。
- 发现任意形状的聚类:DBSCAN特别适合用于处理不规则形状的聚类,特别是涉及地理位置、图像识别等领域时表现出色。
- 处理噪声和异常值的能力:这种算法显著提高了对数据中噪声和异常值的抵抗能力,使得数据分析更为精确。
DBSCAN的局限性
DBSCAN并非完美,仍存在一些局限性。例如:
- 对参数设置的敏感性:DBSCAN的效果高度依赖于eps和min_samples的设置。如果这两个参数设置不合理,可能导致聚类结果不尽人意。比如,eps值过小可能会将实际属于同一簇的数据孤立成多个小簇。
- 对密度变化的挑战:DBSCAN在处理不同密度的数据区域时可能会受到影响,可能导致对某些区域的聚类精度降低。
- 不善于处理突变数据:对于正常数据范围内的突变数据,DBSCAN可能会将其错误识别为正常点,需要结合其他算法进行二次处理。
- 计算复杂度:在处理大规模数据集时,DBSCAN可能会面临较高的计算和内存消耗,需要灵活调整。
六、DBSCAN的适用场景
DBSCAN是一款强大的聚类工具,尤其在处理复杂形状的聚类和包含噪声的数据时表现突出。在地理数据分析、社交网络分析以及无线传感器网络中,DBSCAN都能有效应用。例如,在地理位置数据分析中,该算法能够有效识别出城市中的聚集地带,帮助商家决策开设新店的理想位置。
通过结合DBSCAN算法与其他数据处理工具,如Python库scikit-learn、R的clValid等,可以构建出有效的数据清洗和聚类模型。这将大大提升数据分析的准确率与可靠性。
欢迎大家在下方留言讨论,分享您的看法!