
如何利用知识图谱提升 ICD 编码效率?你绝对想不到的解决方案!
如何利用知识图谱提升 ICD 编码效率?你绝对想不到的解决方案!

亲爱的读者朋友们,今天我们将深入探讨一个医疗科技领域中鲜为人知却极具意义的主题——如何利用知识图谱提升 ICD 编码的效率。相信很多人可能对于 ICD 编码并不陌生,但你知道如何用最新的技术手段优化这一过程吗?接下来,让我们一起揭开这段智能化编码之旅的面纱。
一、电子健康记录 (EHR) 的重要性与普及

1.1 EHR 的发展历程
电子健康记录 (EHR) 是医疗行业数字化的先驱,有效提高了信息的传递效率与准确性。早在 2008 年,美国的门诊医生使用 EHR 的比例仅为 42%,而到 2021 年,这一比例迅速上升到 88% 以上。这一转变不仅标志着医疗行业的数据化转型,而且也大大丰富了患者的健康信息和医疗记录,给后续的病历分析与医疗决策带来了便利。
使用 EHR 后,医生能够在更短的时间内获取患者的医疗历史,了解药物过敏史、既往病史等关键信息,做到精准医疗。这种系统的引入,为CBD(临床决策支持)系统的建立奠定了基础,使得医疗资源的利用效率得到了最大化。
1.2 EHR 的下游应用
EHR 的价值并不仅限于信息存储,它还为许多下游应用提供了丰富的数据基础。尤为重要的是,ICD 编码的使用也逐步与之挂钩。ICD,即国际疾病分类,采用标准化、唯一的字母数字代码以标记疾病和相关健康问题,帮助医疗服务人员更准确地记录和统计病人信息。
不少医院和医疗机构都开始利用数据挖掘和机器学习等方法来提升 ICD 编码的效率,以便快速识别疾病类型与患者情况。随着 EHR 的普及,ICD 编码将更有效地与各种健康管理平台结合,进而推动整个医疗体系向更智能化发展。
二、ICD 编码的复杂性
2.1 什么是 ICD 编码
ICD 编码系统是一种国际公认的疾病的分类和编码标准,广泛应用于医疗记录、保险索赔及公共卫生统计等领域。这个系统本质上帮助医疗专业人士通过简短的代码来表达复杂的信息。ICD 编码的准确性直接影响患者治疗的跟踪和疾病统计的有效性,因而对医疗行业至关重要。
2.2 ICD 编码的挑战与要求
ICD 编码,尤其是在处理复杂病例时,面临许多挑战。首先,该过程需要强大的自然语言理解 (NLU) 能力,以确保自动识别和准确分类 EHR 中的多种诊断。这一过程需要深入了解 ICD 分类法的细节,且37个症状、疾病和治疗过程分类,往往让初学者感到无从下手。
由于不准确或缺失的编码将导致医疗保险索赔出错,造成医院和医生肩负巨大经济压力,因此在判别 ICD 代码时,专业知识和经验成为不可或缺的因素。尤其在面对多种并发症或非典型病例时,确保编码的准确性几乎成了医疗界的“难题”。
三、大型语言模型 (LLM) 在医学中的应用
3.1 目前 LLM 的使用现状
大型语言模型如 GPT-4 不断被引入医学领域,助力于医疗报告的摘要处理、疾病问答等。研究数据显示,这些模型在医学资格考试中表现优异,甚至在一些医学问答任务中,其准确性已与执业医师相媲美。这类技术使得医生在繁忙的日常工作中,可以更高效地处理患者信息,提供个性化的医疗服务。
3.2 LLM 在 ICD 编码中的局限
但 ICD 编码与其他自然语言处理任务十分类似,却又存在显著的不同。部分研究显示,尽管 LLM 在零样本情况下的实体提取效果良好,但在选择合适的 ICD 代码上仍显得力不从心。当面对庞达 70,000 个层次结构化代码时,模型容易陷入混淆,导致结果失真。
在某项目中,LLM 被要求根据“右臂肱三头肌肌肉未指明的损伤”来预测对应的 ICD 代码,但其所作的回应却包含了许多不相关的结果。这种“幻觉”现象不仅使编码工作出现瑕疵,还可能给患者的医疗结果带来风险。这就引发了对 LLM 在医疗编码方面有效性与可靠性的大讨论。
四、知识图谱 (KG) 的潜力与意义
4.1 节点与边的含义
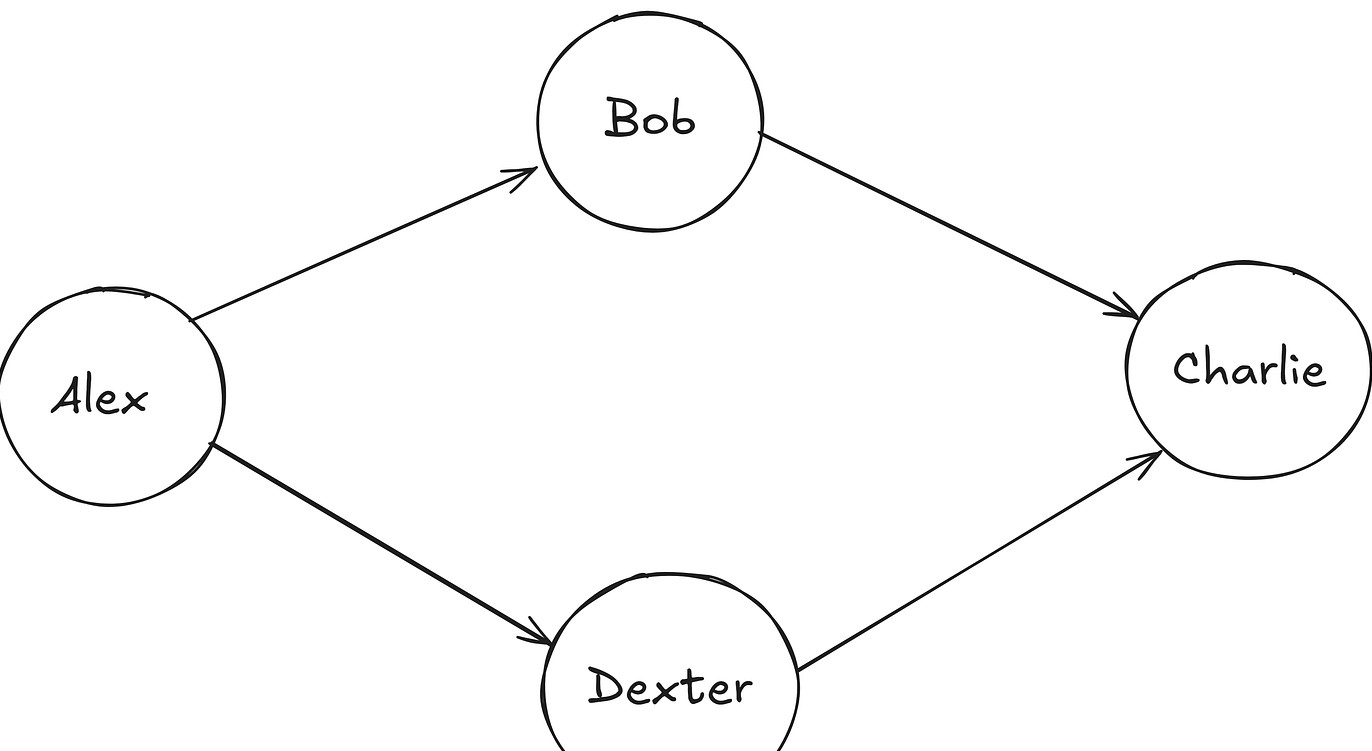
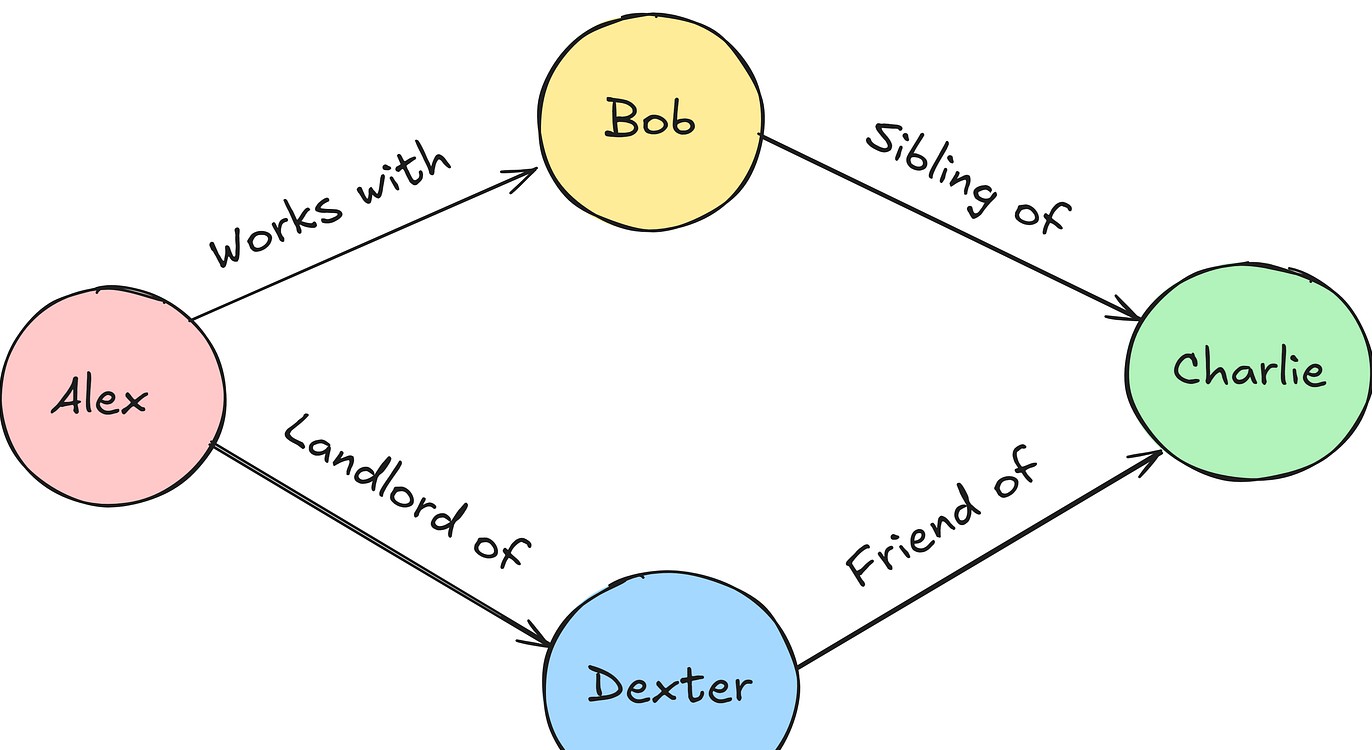
知识图谱 (KG) 是一种将信息以图形方式呈现的技术,它通过节点和边的形式将各种实体及其关系直观地展现出来。节点代表具体的实体,例如疾病、症状等;边则描述了不同实体之间的关系,如“某种疾病与其对应的治疗方法”。这种可视化的方式大大提升了医学知识的获取效率。
4.2 KG 在 ICD 编码中的应用价值
在 ICD 编码的背景下,KG 的价值尤为突出。首先,KG的层次结构得以自然捕捉 ICD 代码间的关系,帮助医生快速从复杂的编码中找到合适的疾病类目。更进一步,KG 能够链接不同的医疗实体,如疾病、治疗、风险因素等,为医生提供全面的医疗决策支持。
通过 KG,医生不仅可以看到疾病的直系影响,还可以挖掘与其相关的症状和治疗选项,这种关联性的显示让临床决策的潜在能力得以提升。此外,在面对复杂的临床案例时,KG能够帮助医生更直观地理解疾病之间的联系,甚至满足不同患者在相似症状下的需求。
五、构建 ICD 编码的知识图谱
5.1 步骤分解
构建适用于 ICD 编码的知识图谱可以分为三个主要步骤:命名实体识别 (NER)、关系提取 (RE) 及实体链接 (EL)。
- 命名实体识别 (NER) 是从无结构化的文本中识别出特定的医学实体,例如“糖尿病”、“心脏病发作”等。为避免错误的识别,使用高效的工具显得尤为重要,例如 Scispacy。
- 关系提取 (RE) 则是识别不同医学实体之间的相互关联。例如,病情“胸痛”与“心肌梗塞”的关系,可以帮助医生在进行诊断时,快速关联症状与疾病。
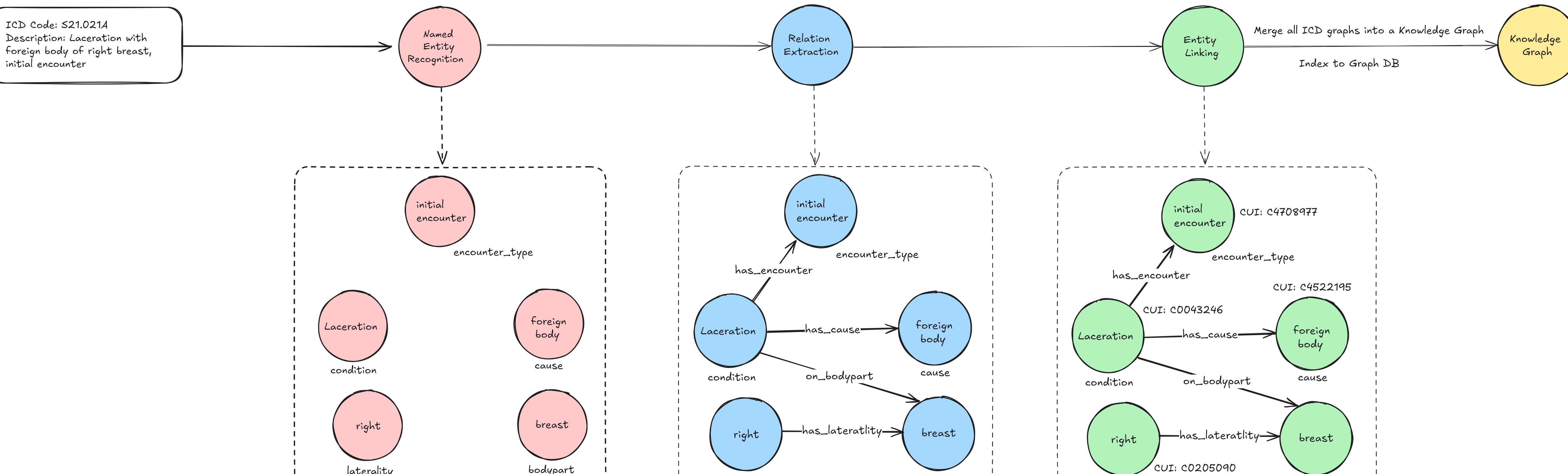
- 实体链接 (EL) 是将所识别的实体与特定的标准概念进行关联,以确保使用的术语在不同的上下文中都保持一致。这一环节中,会有许多同义词概念例如“心脏病发作”和“心肌梗塞”等需要被合理链接。
5.2 具体实施过程
在实施知识图谱构建的过程中,可以运用 LLM 来完成命名实体识别与关系提取两项任务。具体来说,首先需要定义希望提取的实体类型,参考标准 ICD 描述可以使过程变得高效且精确。根据 ICD 代码提出的一组全面的实体类型包括:病情、身体部位、症状等,有助于理清思路。
可以采用 Python 的 Neo4j 图形数据库来存储和查询构建的知识图谱。图数据库能够灵活处理节点和边信息,注重关系数据的查询,并实现按需定制的复杂查询,来满足医疗机构不同的需求。
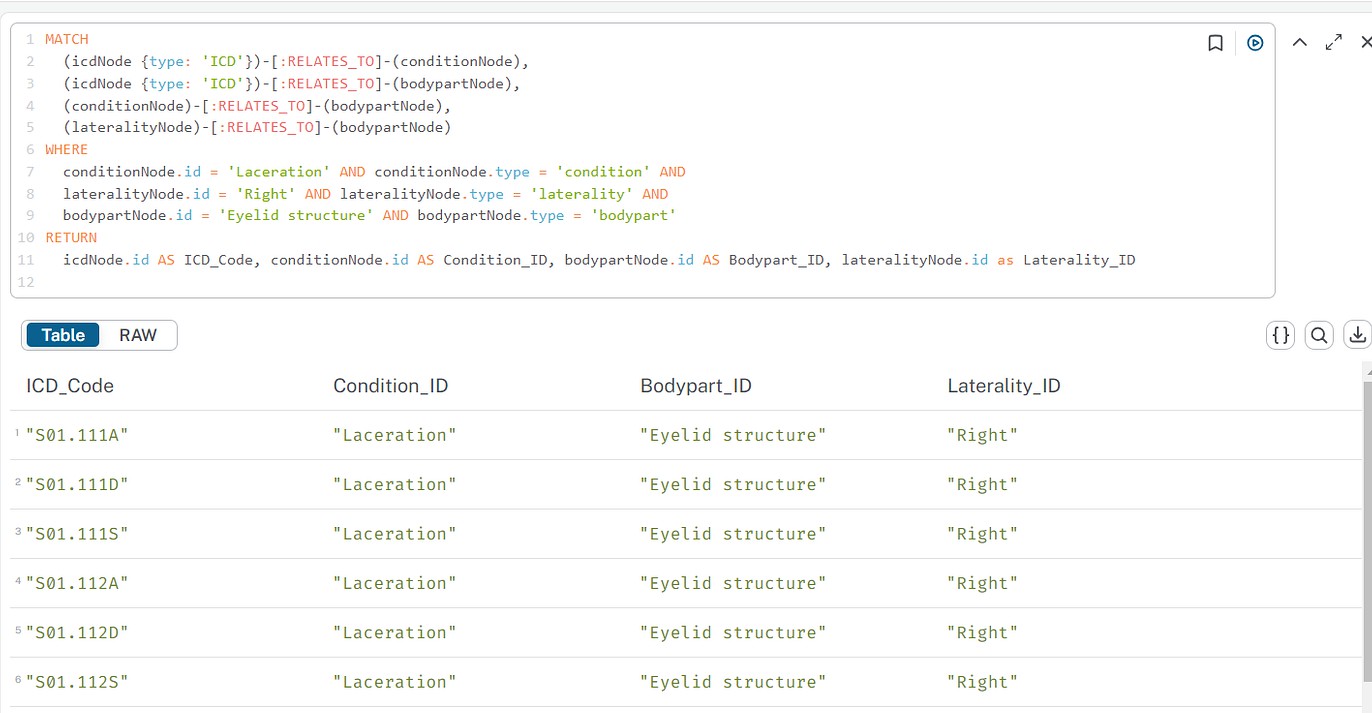
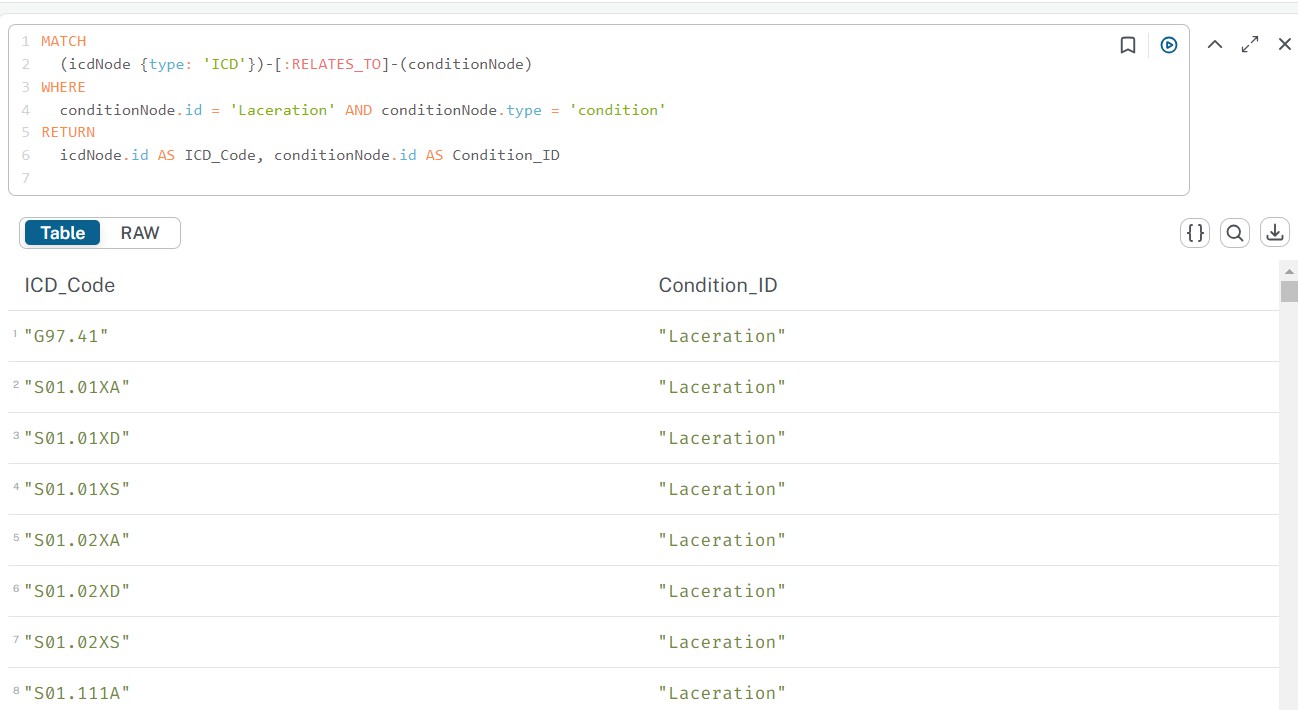
在 Cypher 查询中,可以随意检索与病症相关的所有 ICD 代码,这样便能够对特定疾病进行深入分析,从而为后续的研究工作提供数据支持。例如,医生只需要输入“与胸痛相关的所有 ICD 代码”便可以迅速调取相关信息,极大提高工作效率。
六、未来的研究方向与展望
6.1 整合其他医学知识库的可能性
知识图谱在医疗领域的应用潜力远不止于此,未来可以考虑与其他医学知识库进行整合。实力雄厚的知识库,例如 PubMed,集成了丰富的医学文献和研究成果,将为知识图谱的内容精准性和全面性提供强大支撑。
通过结合这些外部知识,KG 不仅可以将基于文献的数据形式与 ICD 编码相结合,还可以帮助研究员快速识别新的疾病模式与潜在的治疗方案。这种整合,不仅提升了医学研究的效率,也极大丰富了临床决策的信息源。
6.2 改进 LLM 的性能与准确性
当前 LLM 在 ICD 编码领域的瓶颈,有待通过更多专业模型进行突破。针对特定的医疗领域,开发更为强大的模型或微调现有模型,以提高反馈准确性,都是未来的发展方向。
李博士于一次研讨会上提到,通过医学院与技术开发合作来针对医疗数据开发定制化模型,以帮助医生获得更精确的编码结果,这种方式不妨成为一种值得借鉴的模型完善之道。
七、查询与交互
欢迎大家在下方留言讨论,您是否在日常工作中也遭遇过 ICD 编码的烦恼?如果有兴趣进一步深入了解知识图谱及 LLM 的集成方案,别犹豫,快来分享您的看法!
---
通过以上的探讨,我们掌握了如何利用知识图谱提升 ICD 编码的效率,并深挖了 EHR、LLM、KG等相关技术的潜力与价值。在这个数字化与智能化的新时代,希望每位医务工作者都能不再被繁琐的编码环节所困扰,能够将更多时间投入到患者身上。