
我们为何要抛弃MySQL?ClickHouse的存在意义与优势揭秘
我们为何要抛弃MySQL?ClickHouse的存在意义与优势揭秘
亲爱的读者朋友们,大家是否曾在承载着海量数据的后台系统中忍受MySQL的缓慢反应?或者在面对复杂的分析查询时,感受到无形的焦虑?如果您有过这样的经历,那么本文将为您揭示一个可能改变您工作效率的选择——ClickHouse。我们将详细讨论ClickHouse的众多优势,帮助您了解为何越来越多的企业选择它来取代MySQL。
一、ClickHouse的卓越表现
对比测试概述
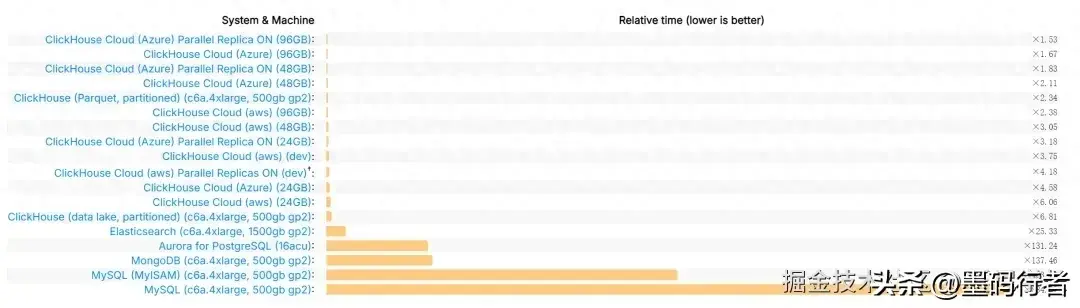
在一场关于数据库性能的较量中,ClickHouse的表现可谓引人注目。在多项官方基准测试中,ClickHouse的平均响应速度在处理复杂查询时,甚至比其他主流数据库如MySQL快了429倍!那么,这样的对比测试是如何进行的呢?各类数据库均采用相同硬件配置,利用一张包含133个字段的大表,涵盖了从1000万到10亿不等的数据量进行60种典型SQL查询。
主要测试结果(性能对比数据)
测试数据显示,在数据量达到1亿的情况下,ClickHouse的响应速度领先于MySQL的429倍,领先Hive 126倍,更有在多个领域著称的数据库如InfiniDB、MonetDB分别以17倍和27倍的响应速度落后。无论是为了获取数据还是进行实时统计分析,ClickHouse都毫无疑问地居于前列。这样的数据,绝对是每一位数据工程师心中那份“珍宝”。
ClickHouse如何超越MySQL的性能
通过这些对比结果,我们不禁好奇,ClickHouse究竟是凭借哪些特性取得这样的显赫成绩?这是接下来的讨论重点,它的核心性能来自于底层架构和数据处理方式的优化。
二、ClickHouse的核心特性
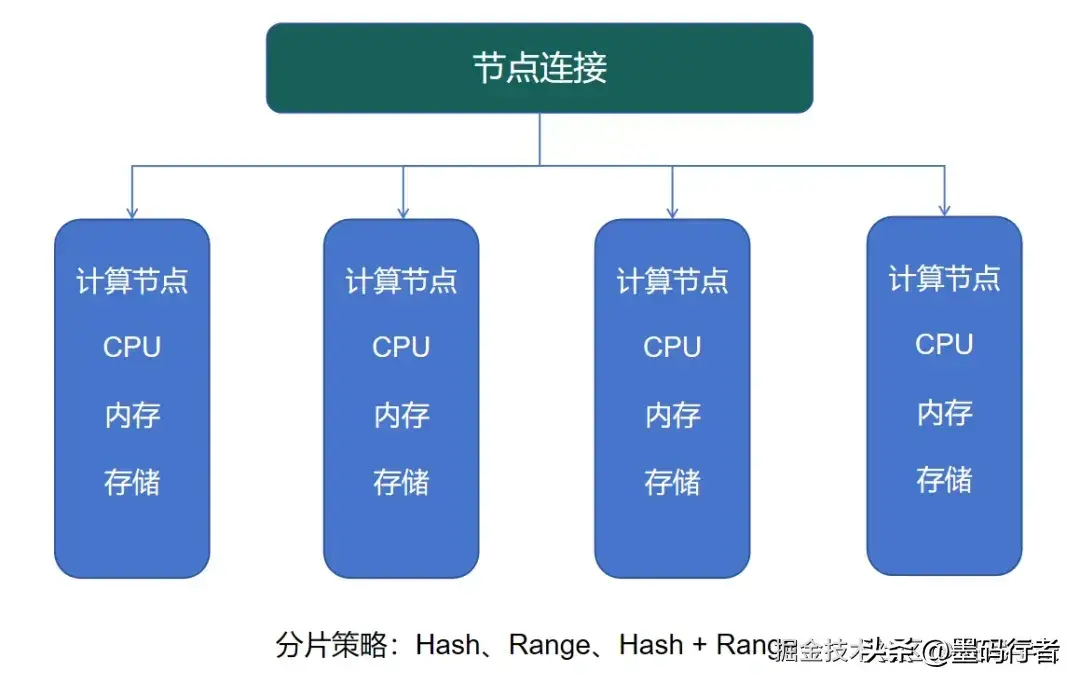
MPP架构
ClickHouse所采用的MPP(Massively Parallel Processing)架构,是其性能优异的重要原因之一。这个架构意味着,数据处理任务可并行分布到多个独立节点上进行处理并将结果汇总。因此,在面对大规模数据集时,各节点并行计算大大和降低了响应时间,与其说ClickHouse是数据库,更不如说它是一个高效的数据处理器。
MySQL使用的是单机架构,无法实现真正的分布式并行计算,通常需要依赖分库分表的中间件来进行实现,这在复杂的查询场景下,不免造成了效率的显著降低。
对比MySQL的架构限制
正因为MySQL的架构限制,它在面对瞬息万变的大数据环境时,稍显得力不从心。“瓶颈”二字在数据库领域并不陌生,而MySQL的大多数问题,恰恰来源于此。ClickHouse的出现,犹如一位打破“瓶颈”的勇者,正好填补了这个空缺。
列式存储
ClickHouse的另一个核心特性就是列式存储。考虑一个实际的业务场景——一个含有2000万条记录的用户表,当我们需要统计用户的平均工资时,ClickHouse仅需访问工资这一列,显著降低了I/O操作和内存消耗。
MySQL在行式存储的情况下,需要从整个表中读取所有字段,做一遍全表扫描才能得出相应结果,这个过程不仅消耗时间,更消耗系统资源。对于大量数据表而言,这种“逐行读取”的方式显得尤为蛋疼,而ClickHouse的列式存储则干脆利落得多。
计算效率的比较示例
想象一下:假如用户表有10个字段,为获取平均工资,ClickHouse只需读取工资这一列的数据。这宛如轻松拿下的薪酬谈判,避免了复杂计算的困扰。而MySQL则常常面对的是事倍功半的疲惫,真正地成为了大数据环境下的羁绊。

数据压缩技术
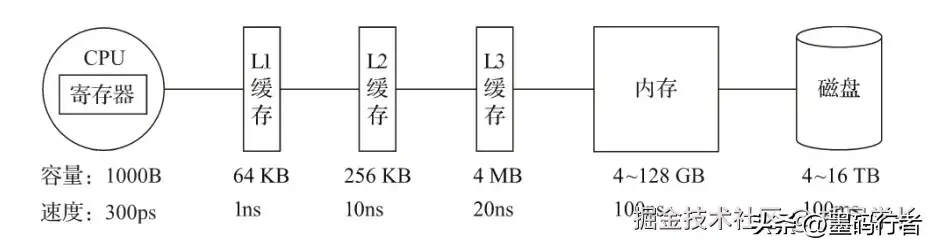
进一步说到数据存储,ClickHouse采用先进的数据压缩技术,这在一定程度上提升了查询的效率。通过最新的LZ4算法,将数据的压缩比优化到8:1,不仅节省了存储空间,也减少了磁盘I/O和网络传输的负担。
MySQL的压缩效果仅能节省30%到50%的空间,而且通过压缩后对数据库性能却往往有较高的影响。在数据量巨大的情境下,这种影响不可忽视,因此ClickHouse在这方面显得更具优势。
与MySQL的对比效果
再举个例子,假设有一台服务器,可以存储1TB的数据,使用MySQL时有效利用的仅有500GB,而ClickHouse则通过有效的压缩技术,能够将其优化到100GB,这样不仅节约了存储成本,还为后续的数据分析提供了便利。
向量化执行引擎
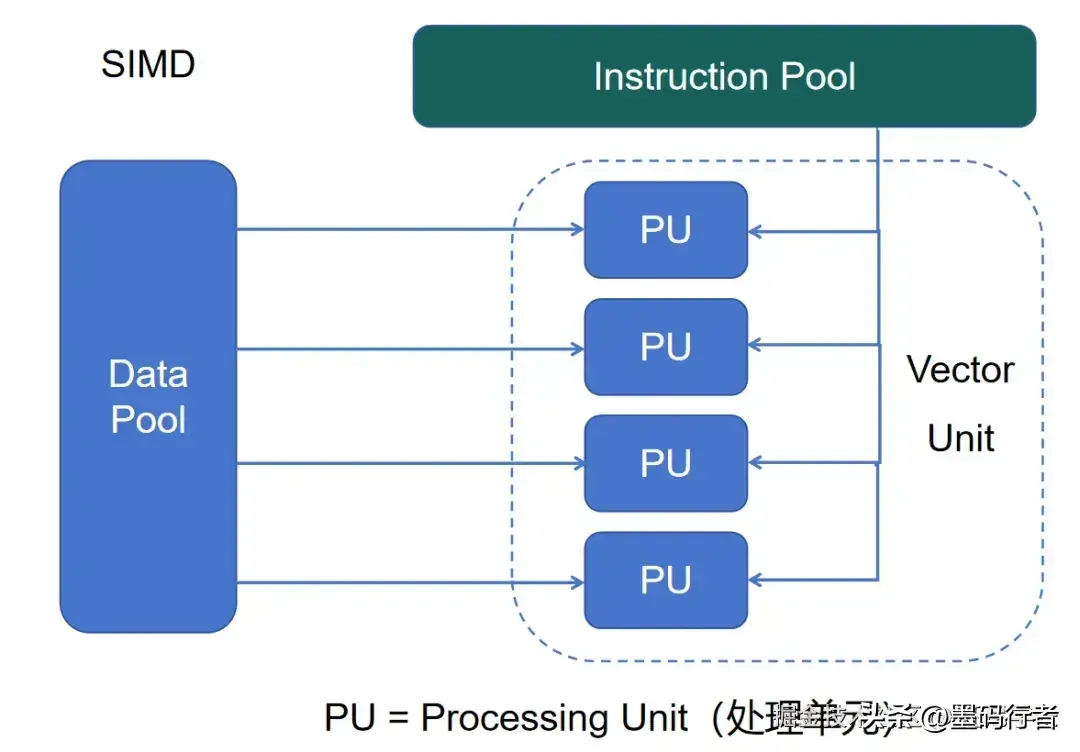
ClickHouse还实现了向量化执行引擎,得以最大化地利用处理器能力。在传统数据库中,我们的每一条查询通常是逐行处理,而在ClickHouse中,它可以一次调用多条记录进行处理,这种设计本质上将处理速度飞跃到一个新高度。
SIMD操作原理
这种操作方式是通过现代处理器的并行能力来实现的,能简化代码执行,提高查询操作效率。在经历了长时间的数据库调优后,ClickHouse解决了“瓶颈”问题,实现了极高的性能处理。例如,查询平均工资时,ClickHouse可在寄存器层面并行处理数以万计的数据行,从而显著提升了计算速度。
索引设计
ClickHouse在索引设计方面也表现出色,其采用了稀疏索引而非传统的稠密索引。稀疏索引基于数据块,减少了存储需求,使得系统能在内存中保持更高效的索引标识。假如在处理一亿条记录的数据表时,ClickHouse只需使用12208个索引标记,相比之下,MySQL则需要更多的标识,这就极大影响了查询性能。
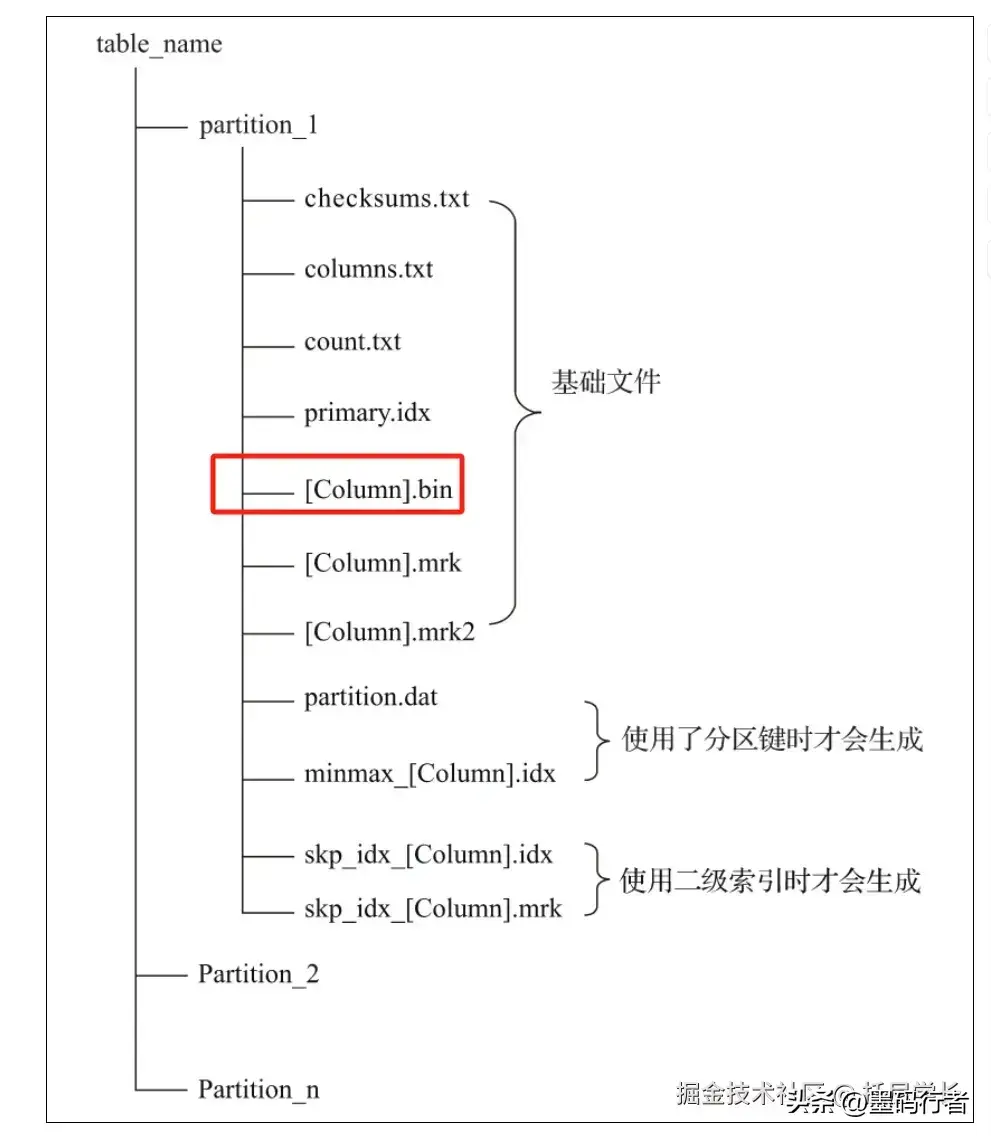
二级索引类型的多样性与应用场景
ClickHouse不仅支持minmax、set等多类索引,还实现了布隆过滤器。这意味着在进行复杂查询时,可以显著提高筛选的准确性与效率。尤其是在涉及到如查询“退款”订单这样的具体场景时,ClickHouse的索引能迅速锁定目标,响应更加灵敏。
在当今大数据浪潮中,选择一个优秀的数据库产品不再是简单的“选哪个就能用”。我们需要思考,数据本身的复杂性、处理要求以及未来的发展潜力。这一切都是技术人员必须考虑的要素。ClickHouse在这些方面的出色表现,值得每一位IT从业者的关注与深入研究。
欢迎大家在下方留言讨论,分享您的看法!