
你离构建完美的大模型检索增强生成系统还有多远?
你离构建完美的大模型检索增强生成系统还有多远?
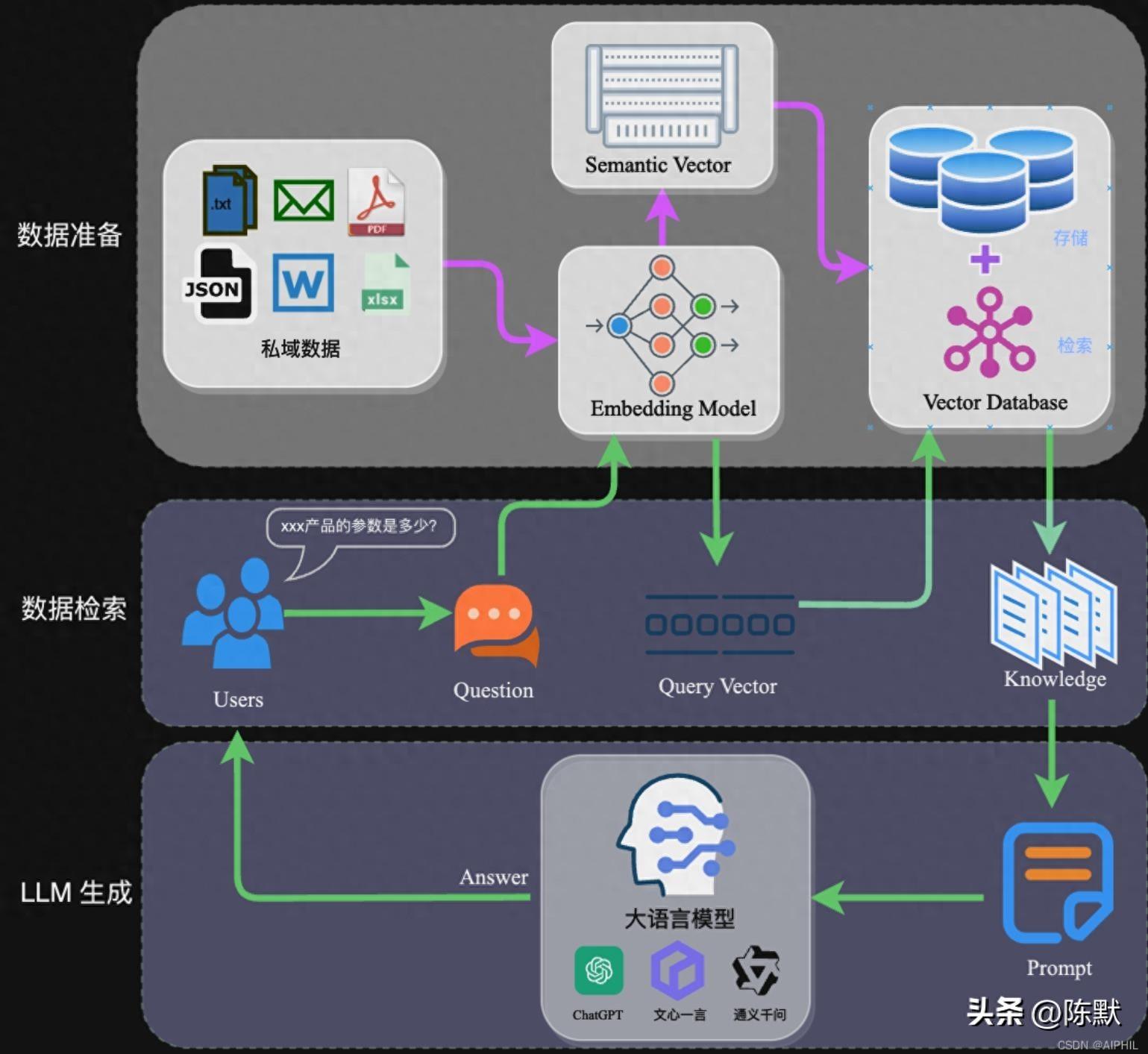
亲爱的读者朋友们,是否曾想过要构建出一个理想的大模型检索增强生成(RAG)系统,却面临着重重挑战?本文将带你深入探讨RAG系统的构建过程,分析各个环节所存在的问题,并为你提供切实可行的解决方案和案例,让你在信息处理的道路上走得更稳、更远。
一、数据处理方面
数据提取
在构建RAG系统的过程中,数据提取是关键的第一步。现实中,我们要面对众多复杂的文件格式,如PDF、Word或者甚至Excel,这些文件不仅包含文字,还有图表、图片等多种信息形式。如何从这些复杂的文件中提取出有效的数据成为了一个巨大的挑战。
在处理PDF文件时,我们可能遇到文本与图像混合的情况。此时就需要借助光学字符识别(OCR)技术。OCR可以帮助我们将图片中的文字信息提取出来,但其准确率并不能做到100%。在使用OCR时,我们一定要注意对结果进行校对,如有可能的错误或遗漏,及时修改,以保证数据的完整性与准确性。
对于图表信息的提取,我们需要运用到更高级的机器学习算法,以理解图表的结构与意义。这包括了数据的上下文信息提取,如:文件的主题、所属分类等。在此过程中,可以采用预训练的深度学习模型来加速数据提取的效率和准确性。
上下文元信息提取
上下文元信息,对于后续的数据处理与分析至关重要。比如在文档切分时,如果没有准确提取这些元信息,系统可能会出现切分错误,从而影响后续检索的效果。这就要求我们对文本的语义和逻辑有充分的理解。
不同类型的文件,提取上下文元信息的方式各有不同。针对不同文件格式,可以开发多种解析函数,利用正则表达式、NLP工具等手段,实现自动化处理。这不仅提高了效率,还降低了人工介入的风险。
数据清洗与质量把控
数据质量是RAG系统的坚实基础。原始数据往往含有噪声、错误、重复以及不一致性。例如,文本中的拼写错误、语法错误,甚至是数据格式的不统一都会导致生成的答案失真。因此,在数据清洗阶段,我们可运用正则表达式、数据去重算法等手段对数据进行清洗。
指导建议:建议使用开源库如pandas和numpy来处理数据,并进行数据框架设计,将数据结构化,更便于后续处理与分析。在数据来源多样化的情况下,应当维护一套质量评估机制,通过规则检查、人工审核与算法结合来确保数据的可靠性。
二、索引构建方面
数据切分策略
有效的数据切分是索引构建的核心。切分不会过大,从而导致信息检索粒度不足;也不能过小,以致于丧失上下文信息。在RAG系统中,不同类型的文本需要采用不同的切分策略。例如,对于长文本,可以考虑按段落切分;而对于短文本,则可以按句子进行切分。
在实施过程中,可以运用自然语言处理技术(如:分词算法)来提升切分的准确性。此外,利用文本分类模型对不同切分策略的效果进行评估,选择最佳的切分方案,形成闭环反馈。
向量表示与嵌入
切分后数据的向量表示与嵌入构建,是索引的另一重要步骤。选择合适的向量嵌入模型,将文本有效转换为向量表示至关重要。目前,常用的模型包括Word2Vec、BERT等。选定模型后,需确保其具有良好的语义理解能力,以便进行有效的检索。
注意事项:不同模型的计算成本差异较大,处理大规模数据集时,一定要考虑计算资源的分配,合理调度CPU及GPU资源,以提高计算效率,同时保持向量质量。
三、检索阶段方面
检索质量和准确性
RAG模型的效果在很大程度上依赖于检索到的信息质量。若检索器找不到相关的事实段落,生成的结果将无法令人满意。由于语义歧义、向量空间密度等,可能导致检索到结果的相关性不足。
可以考虑引入多任务学习模型和<|vq_8159|>深度强化学习算法,来提升检索效果和精度。此外,结合semantic similarity algorithms(如余弦相似度等)来解决语义匹配问题,可大幅度提高文档检索的准确性。
覆盖范围和实时性
在构建RAG系统时,我们不应忽视语料库的覆盖面。即使是大型语料库,也难以完美覆盖所有用户可能查询的实体与概念,尤其是新兴或小众主题。因此,定期更新和扩展语料库,是提升系统覆盖与实时性的关键。
数据更新频率建议设定为每周或每月,这样能确保用户获取到最新的信息。而对于实时应用,则需借助流式数据处理技术来快速更新。
情境调节
即便检索能力强大,RAG模型依然会面临情境调节的难题。有效的情境调节能够帮助模型动态理解上下文,正确合并外部知识到生成的文本中。
在实现过程中,可采用专门的算法,如交叉注意力机制,它允许模型在生成时能有效关注重要信息,提高生成结果的相关性与准确性。
四、生成阶段方面
信息融合与连贯性
在生成阶段,有效地将检索到的信息与大模型生成的内容融合,是一项不小的挑战。不同来源的信息可能存在风格、语气及表达方式的差异。生成的答案需要具备连贯性和一致性,避免出现不自然的衔接问题。
为了解决这一问题,可以采用文本生成的预训练模型,如GPT系列,通过大量示例学习,提升模型的生成能力。此外,结合内容相似度判别与信息交互区分来保证生成内容的连贯性。
答案的准确性和可靠性
生成的答案尤其在事实性回答场景中,必须保持高度准确。一方面,需利用相关的知识图谱进行背景知识支持,另一方面,要通过多轮验证机制来确保生成内容的可信度。
多轮验证手段包括基于用户反馈的动态调整与评估。持续监控生成的内容,通过用户的真实反馈,优化模型设计,从而实现更高的准确性。
个性化落地
个性化能力是提升RAG系统应用效果的关键。针对用户的需求与上下文信息进行定制化回答,能够极大提高用户的满意度。利用机器学习技术对用户信息进行建模,实时更新用户画像,以适应不同的提问意图及背景知识,将是成功的关键。
解决方案:采用多任务学习与迁移学习等方法,针对不同用户生成不同的响应方式,需要一定规模的用户数据进行训练,但其效果将会显著提升个性化服务的能力。
五、系统性能优化方面
计算资源消耗
在处理大规模数据集时,RAG技术常常需要相当大的计算资源。一方面,深度学习模型计算量大,另一方面,用户请求多并发对计算资源的要求更为严苛。因此,系统的计算资源进行合理配置与管理至关重要。
通过采用模型压缩、量化以及蒸馏等技术,可以在不显著影响模型性能的前提下,减少计算资源的消耗。这样能有效降低运营成本,同时提高系统的响应速度。
推理延迟
在一些实时应用场景中,如智能客服或智能助手,系统的响应速度至关重要。推理延迟长会严重影响用户体验,因此优化检索与生成过程所需时间是首要任务。
通过优化索引算法、推理路径及并行计算方式,可以显著减少推理延迟。同时,建议使用流行的推理引擎(如NVIDIA TensorRT),从而实现快递的查询与生成。
适时的模型与算法的融合、性能的调优,也能让用户在体验RAG系统时,得到快速而流畅的反馈与支持。
欢迎大家在下方留言讨论,分享您的看法!我们相信,理解并解决这些挑战,不仅能助力你构建一个高效的RAG系统,还能在信息时代中寻找更多的机遇。