
如何用大型语言模型全面解析客户评论,提升企业竞争力?
如何用大型语言模型全面解析客户评论,提升企业竞争力?
亲爱的读者朋友们,今天我们将深入探讨如何利用大型语言模型(LLM)有效提取和解析客户评论,帮助企业更好地理解客户需求,从而提升竞争力。在信息爆炸的时代,如何从海量的客户反馈中提取有价值的信息,是每个企业必须面对的挑战。接下来,我们将详细解析各个方面,希望能够给你带来新的启发。
一、非结构化数据的背景
无论是社交媒体、客户评论还是产品反馈,企业每天都会接收到海量的非结构化数据。这些数据虽然难以处理,但却蕴含着客户对产品的真实看法和市场趋势的关键信息。根据一项研究,约有70%的客户会在购买后留下反馈,然而,许多企业在处理这些数据时却面临着重重困难。有效地解读这些数据,不仅能够帮助企业优化产品,提升用户满意度,还能在激烈的市场竞争中占据优势。
随着社交媒体的崛起,消费者的声音变得比以往任何时候都更重要。根据Statista的数据,2022年全球社交媒体用户达到了45亿,企业如若错过了洞察消费者情绪的机会,可能会导致产品失误甚至品牌危机。正确地处理和分析这些数据,企业才能及时发现潜在的问题,做出相应调整。
二、企业如何理解客户反馈
在面对客户反馈时,许多企业常常看重的是数字评分。然而,单纯依赖评分往往无法深入了解客户的真实感受。例如,如果一位客户在评价中给出了较低的星级,却描述了产品使用中的一些积极体验,这种情况并不罕见。深入理解产品的优缺点,以及客户愿意推荐或回购的因素,才是一项能够带来实际价值的分析。通过了解不足之处,企业可以进行有效的改进。

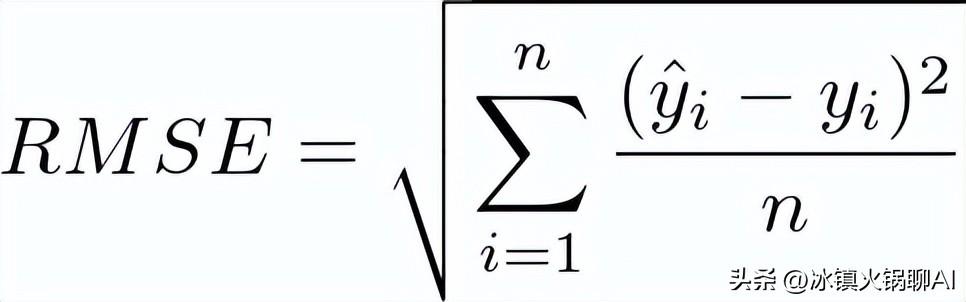
大型语言模型(LLM)的崛起为企业解读客户反馈提供了新的可能性。它们不仅可以处理数字评分,还能深入分析文本评论,提取出潜在的产品优缺点、使用场景及客户体验。这种高级解读能力,使企业能在海量的信息中快速找到最关键的内容。因此,越来越多的企业开始将LLM纳入客户反馈分析的工具箱,借此提升客户满意度与品牌形象。
三、数据集介绍
在分析客户评论时,选取合适的数据集至关重要。亚马逊评论数据集就是一个典型的例子。该数据集包含来自亚马逊的3500万条评论,跨越了18年,涵盖了丰富的产品和用户信息。这为研究人员和企业提供了宝贵的资源,让他们可以基于真实的用户反馈进行分析与模型训练。

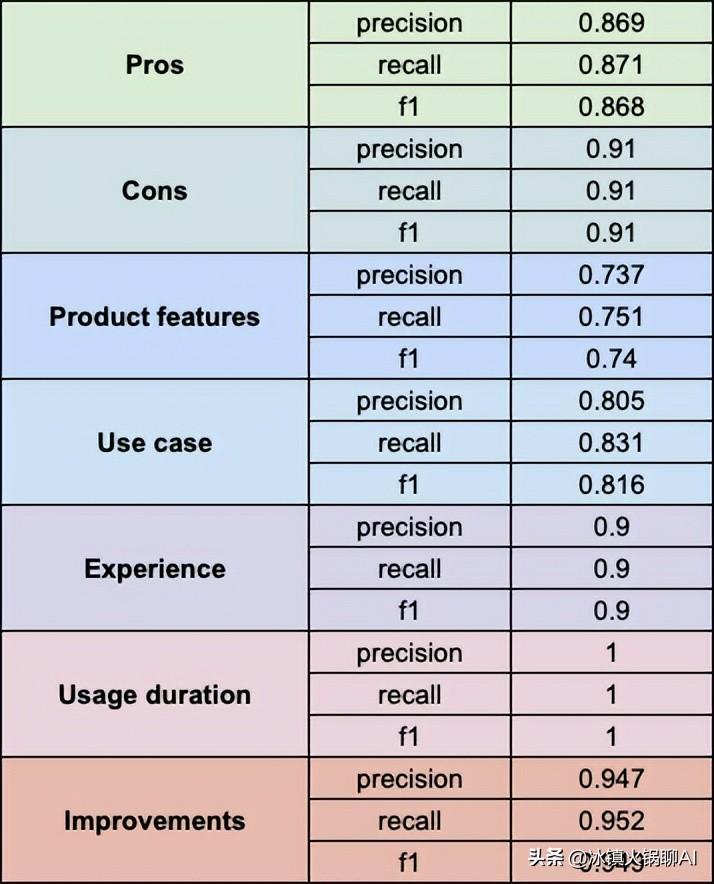
在选取数据集时,可以从中抽取600,000条训练样本和130,000条测试样本。数据集由三个主要字段组成:类别索引(评分)、评论标题和评论文本。对于需要提取元数据的研究,建议手动标记评论的特定佛伽。例如,您可以从评论中提取出用户满意的功能(Pros),不满意的功能(Cons),使用情境(Use case),整体体验(Experience)等关键结构。这一过程虽然耗时,但却能为后续的分析奠定坚实的基础。
四、元数据提取的核心要素
元数据提取的核心在于明确提取的结构和要素。比如,用户反馈中提及的正向和负向体验、产品功能及使用场景等都是提取元数据时不可忽视的部分。对这些信息的系统化提取,有助于企业从更为细节的层面理解客户需求。
在元数据提取的过程中,可以采用零样本提示技术(Zero-shot Prompting)。这种方法不需要大量标记数据,更加高效。在构建一个有效的提示时,明确向LLM说明期望的输出形式,如提取“Pros”、“Cons”、“Experience”等信息,就能显著提高模型的准确性。此外,建议使用OpenAI的LLM来处理评论数据,它们在文本解析和语义理解方面表现优异,能够解决传统算法在复杂任务中的局限性。
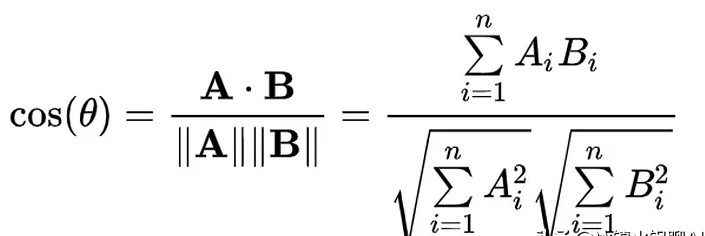
在数据提取完成后,需对输出的准确性进行评估。可通过与已有数据比较,或者通过混淆矩阵可视化来理解模型的预测与实际评分之间的差异。这一步骤能帮助进一步优化提取的过程,确保最终数据质量。
五、模型的评估与性能
评估大型语言模型(LLM)的效果,必须采用适当的指标。比如,星级评分预测的准确性可以通过均方根误差(RMSE)来衡量,这是评估预测与真实值之间差异的重要指标。通过对100条评论的分析,计算RMSE的值,可以清晰了解模型在预测评分时的表现。
在数据聚合后,有必要对结果进行可视化,使得模型预测与实际评分之间的关系更加明晰。这不仅可以揭示模型的优缺点,对于后续的模型调整也是一种有效的指导。在这一过程中,发现的某些矛盾之处,如用户的评论内容与星级评分不一致,可能提示出潜在的消费心理和情感因素。
一个客户可能对产品整体满意,但因某个小缺陷而给予较低的评分。模型在此情境下可能依据评论的积极情感给出较高评分。在结果分析中,尽量挖掘出几条具有代表性的评论反馈,使得更多用户能够看到实际的反馈情况。这种声音的收集,对产品的迭代和客户关系维护至关重要。
六、挑战与局限性
尽管LLM在处理客户评论时展现出强大的能力,但仍然存在一定的挑战和局限性。LLM的输出可能并不总是理想,模型容易受到训练数据偏差的影响,导致结果的可靠性下降。例如,在处理某些情感极端的评论时,模型可能产生幻觉,输出信息失真。因此,使用LLM时应时刻保持谨慎,不可将所有结果视为绝对真实。
在进行元数据提取过程中,由于文本的复杂性,有时需要将字符串转化为向量,以计算它们之间的相似度。这通常使用余弦相似度,通过高维嵌入表示来捕捉上下文和语义。为此,运用OpenAI的文本嵌入模型(如text-embedding-3-large),对字符串进行转换,可以有效计算不同文本间的相似性。
理解LLM的局限性是十分重要的。为了确保信息的准确,建议在使用LLM的过程中,与人工核实结合,尤其在处理敏感数据时。此外,可以构建一些监控机制,在模型出现偏差时进行快速调整。
七、未来展望
随着技术的不断进步,LLM在分析客户反馈方面的应用前景不可**。未来,企业有可能实现多元化的产品评级体系。比如,基于用户评分和LLM评分的双重评价体系,能够为消费者提供更全面与客观的信息,让他们在购买决策中拥有更多参考。
在这一过程中,LLM无疑将成为企业理解客户需求、增强产品竞争力的重要工具。通过有效的解读客户反馈,企业能够敏锐捕捉到市场趋势,迅速作出反应,进而实现产品优化与客户关系提升。
我们期待看到越来越多的企业应用这种先进的技术。若能将LLM与其他工具,如用户行为分析、实时反馈机制等结合,势必会为整个行业带来颠覆性的变化。想要在竞争中胜出,抓住客户心声成为每个企业的当务之急!
欢迎大家在下方留言讨论,分享您的看法!