医学图像处理的新突破:UniMedI如何重塑AI与多模态 图像解析
医学图像处理的新突破:UniMedI如何重塑AI与多模态 图像解析
亲爱的读者朋友们,随着人工智能的飞速发展,医疗科技的前景也在不断被重新定义。特别是在医学图像处理领域,如何有效整合多模态图像数据,提升诊断的准确性与效率,成了众多研究者努力探索的方向。在这篇文章里,我们将深入探讨浙江大学与微软亚洲研究院共同研发的 UniMedI 框架,它将如何通过创新的方式解决传统医学图像处理中的痛点,以及这背后所蕴藏的无限可能。
一、引言
从字面上看,机器不再是简单的执行者,而是仿佛具备了人类特有的反应能力。这种转变在AI的发展中并非遥不可及,尤其是在医学领域。研究者们将目光投向了如何让计算机在特定任务中代替人类,减少人工操作的繁琐。正是在这一背景下,视觉语言预训练(VLP)技术的兴起给医学图像处理带来了新机遇。VLP将视觉数据与语言信息结合,使得模型能够更好地理解图像内容与文本描述之间的关系。
尽管VLP在医学图像分析方面展现出了一定的效果,依然存在着模型训练数据的局限性。许多现有的模型过分依赖于单模态数据,比如2D X光片,而忽视了实际诊疗中多模态图像的重要性,如CT或MRI等。这让我们深思:如何才能在数据稀缺的情况下,通过合适的技术手段实现更高效的医学图像分析呢?
二、VLP在医疗领域的现状与挑战
医学图像处理的核心在于如何快速而准确地进行图像解读,传统的方法多采用单模态数据进行训练。然而,依赖单一的2D图像数据集常常导致模型的局限。例如,X光片虽然能够显示骨骼和肺部状态,但对于某些复杂的病症,如肿瘤的准确识别,往往需要结合CT或MRI等3D数据进行多维度分析。这种高维信息的整合,就成为了医学图像处理中的一大挑战。
不同模态数据的异质性是另一个亟待解决的问题。2D和3D图像在结构和数据表现上存在显著差异,简单的结合往往无法有效发挥出它们的潜能。除了异质性,缺乏成对数据的问题也让模型训练变得更加复杂。例如,要将一个3D图像与其相关的2D切片进行对比学习,但在实际中,合适的配对样本并不容易找到,这就导致了训练集的稀疏性。
为了破除这种困局,亟需采取有效策略将多模态图像整合到统一的模型中,使得模型不仅能独立处理2D或3D图像数据,还能在两者之间实现有效的协作与学习。
三、UniMedI框架的提出
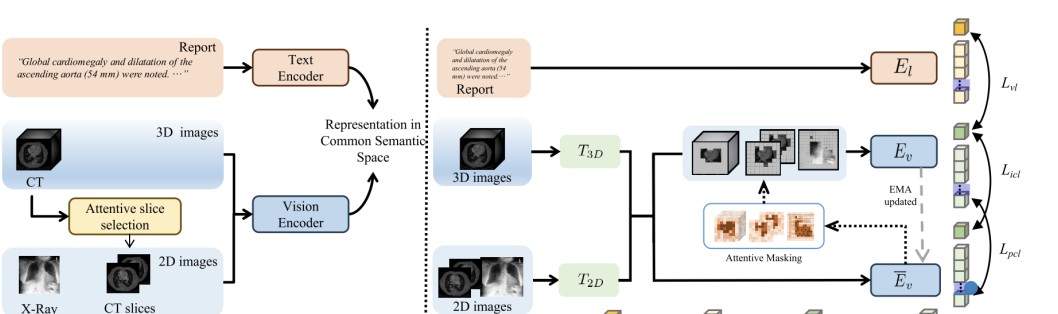
为了应对上述挑战,浙江大学的胡浩基团队与微软亚洲研究院的邱锂力团队共同研发出了一种全新的框架,名为UniMedI。这一框架的核心在于其能够有效地将不同模态的医学图像整合至同一语义空间。通过引入诊断报告,UniMedI成功实现了2D和3D图像的统一表示,使得计算机模型可以更好地理解医学图像背后的临床信息。
引入“伪配对”技术是UniMedI的一个创新之处。在传统的训练模型中,数据配对常常需要研究者事先进行标注,而UniMedI通过语言引导,从复杂的3D图像中选择与之相关的2D切片进行配对。这一策略不仅增强了不同模态图像之间的相关性,更为模型提供了更丰富的学习目标。
通过这样的创新,UniMedI的框架便能够适应更多实际应用场景,为医学图像的多模态分析提供了全新的解决方案。未来,该框架有望成为医学图像解析领域的重要工具,助力临床诊断的精准化。
四、UniMedI框架的实现
UniMedI框架的成功实现离不开高质量的数据集。研究团队选取了来自MIMIC-CXR 2.0.0的2D X光片与BIMCV的3D CT扫描数据进行训练。数据的预处理环节则是保证模型准确性的关键步骤。例如,团队对2D X光片数据进行了筛选和清理,消除了所有侧面图像,以便与下游任务中的前方视图图像对齐。这一处理确保了数据的一致性与完整性。
接下来的模型设计中,UniMedI采用了两个编码器:视觉编码器与文本编码器。视觉编码器使用ViT-B/16,主要负责提取2D和3D图像在公共特征空间中的表现;而文本编码器则采用BioClinicalBERT,旨在将文本信息有效编码为模型可理解的格式。这一过程的核心在于两种编码器的通用性,使得无论是2D还是3D数据,都能够在同一模型中进行有效的学习与分析。
为了克服配对数据不足的问题,UniMedI引入伪配对技术,并设计了一种基于语言指导的注意力切片选择策略。当输入是3D图像时,UniMedI能够从中提取与报告最相关的2D切片,从而在没有精确配对的情况下,实现对图像之间关系的有效学习。这一创新大大提升了数据的利用率和学习效率。
五、实验与评估
在具备了框架的基础上,接下来的实验与评估环节至关重要。研究团队对2D和3D数据集进行了多次实验检验UniMedI的性能。这一系列的实验不仅包括医学图像分类,也涵盖了语义分割等多项任务。
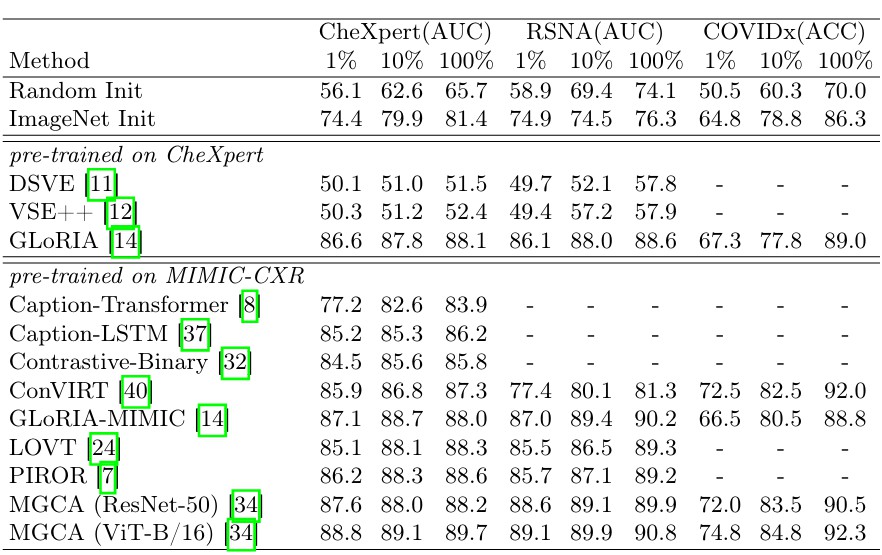
UniMedI展现出优越的性能,特别是在处理多模态数据的结合上。在对多个不同数据集进行医学图像分类时,UniMedI在CheXpert、RSNA以及COVID-19等公共数据集上的表现均超过了其他现有方法。例如,在使用1%、10%与100%训练数据下,UniMedI在CheXpert数据集上的AUROC值分别提高了+0.6%、+0.6%和+0.8%。这足以证明其在数据稀缺的情况下,依然能展现出强大的学习能力与准确的分类能力。
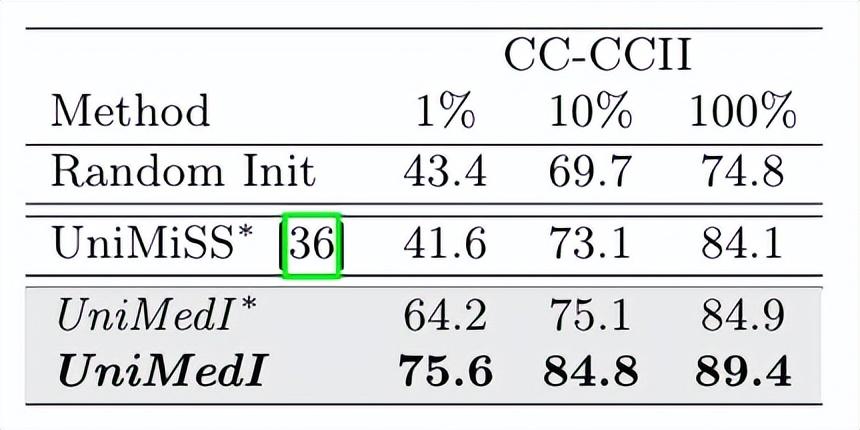
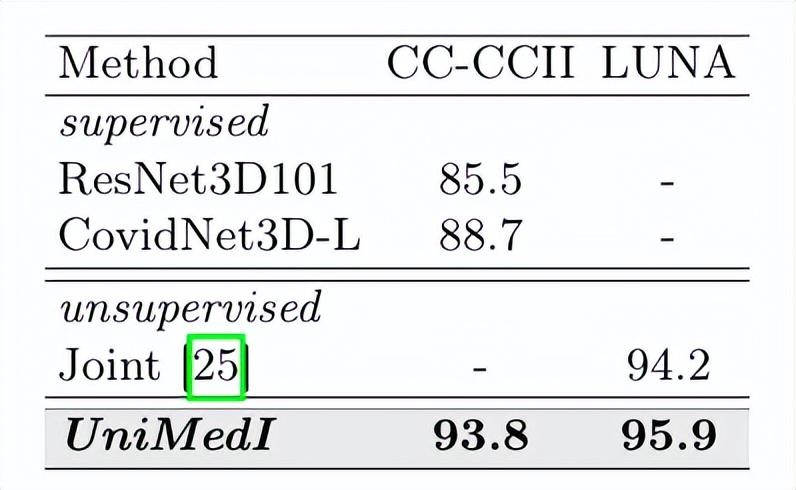
在3D医学图像分类实验中,UniMedI的ACC值也在CC-CCII数据集上取得了显著的提升,相较于其他方法提升幅度可以达到22.6%。这一结果侧面反映出UniMedI能够在数量不均的数据集上实现高效学习与分类,为医学图像分析增添了信心。
六、UniMedI的优势与局限
UniMedI的至关重要之处在于其所带来的优势:多模态数据的有效整合。通过对不同模态之间的特点与信息进行深度挖掘,UniMedI不仅提高了整体模型的学习效果,也为临床提供了更科学合理的决策依据。这一框架有望在未来的多项医学任务中,如图像分类、分割以及检索等领域,发挥更为广泛的作用。
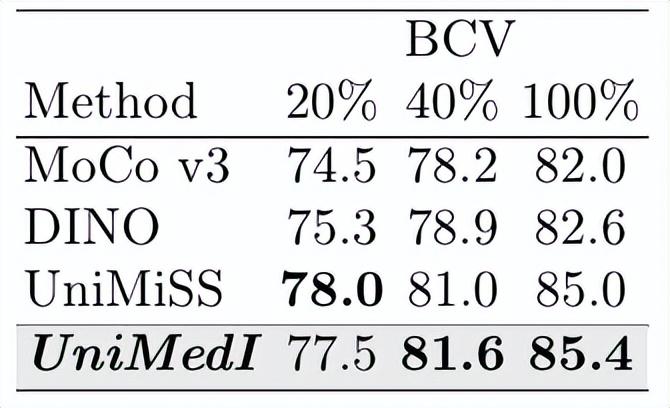
尽管UniMedI展示了良好的性能,仍需认识到其在一些方面存在局限性。例如,由于数据集的稀缺性,以及不同医院之间数据分布的不均衡性,模型的普适性与适应性较低。因此,未来有必要探索更有效的跨医院合作与数据共享的平台,确保更大规模的数据集能够为模型的训练提供支持。
七、现实意义与未来展望
UniMedI的成功不仅为医学图像处理提供了一种全新的思路,也进一步推动了人工智能在临床医学中的实际应用。我们可以设想,当这一模型真正落地应用于医院时,医生们可以凭借其辅助诊断的功能,大幅度提升工作效率与诊断准确度。

随着技术的不断演进与优化,未来还将有更多团队投入到这一领域的研究中,探索VLP与医学图像之间更深层次的结合。通过持续的努力,有望在不久的将来,医务工作者将能更加便利与高效地利用多模态医学图像,提高患者的诊疗体验,切实推动医疗行业的变革。
欢迎大家在下方留言讨论,分享您的看法!