
微软开源的1bit大模型推理框架,如何重塑AI的计算能力?
微软开源的1bit大模型推理框架,如何重塑AI的计算能力?
亲爱的读者朋友们,今天我们将共同探讨一个正在引领人工智能(AI)领域新变革的话题,那就是微软开源的1bit大模型推理框架。想象一下,如果未来我们可以在不牺牲性能的基础上,降低AI的计算资源需求,是否会是所有技术爱好者和开发者梦寐以求的目标呢?让我们深入了解这一创新如何重塑AI的计算能力以及它对整个产业可能产生的深远影响。
一、引言
背景介绍
自然语言处理领域的大模型如雨后春笋般层出不穷,许多企业都在投入大量资源以研发出更复杂、更庞大的模型。然而,随着模型参数的逐渐增多,随之而来的就是运行成本的飙升,尤其是在计算资源和存储需求方面。无论是科学研究机构还是企业,很多时候都被迫面临这样的困境:如何在有限的资源下,充分利用这些强大的模型?
新技术的出现
在这个背景下,微软的1bit大模型推理框架如同一缕清风,为整个行业带来了新的希望。该框架支持将模型参数进行量化,使得<被神一般的变身,实现了从传统的16位浮点数存储到三进制表示的突破。正因如此,微软的这一开源框架不仅受到了广泛的关注,更引发了科研界和技术圈的热烈讨论。
二、1bit大模型的概念与优势
何为1bit大模型?
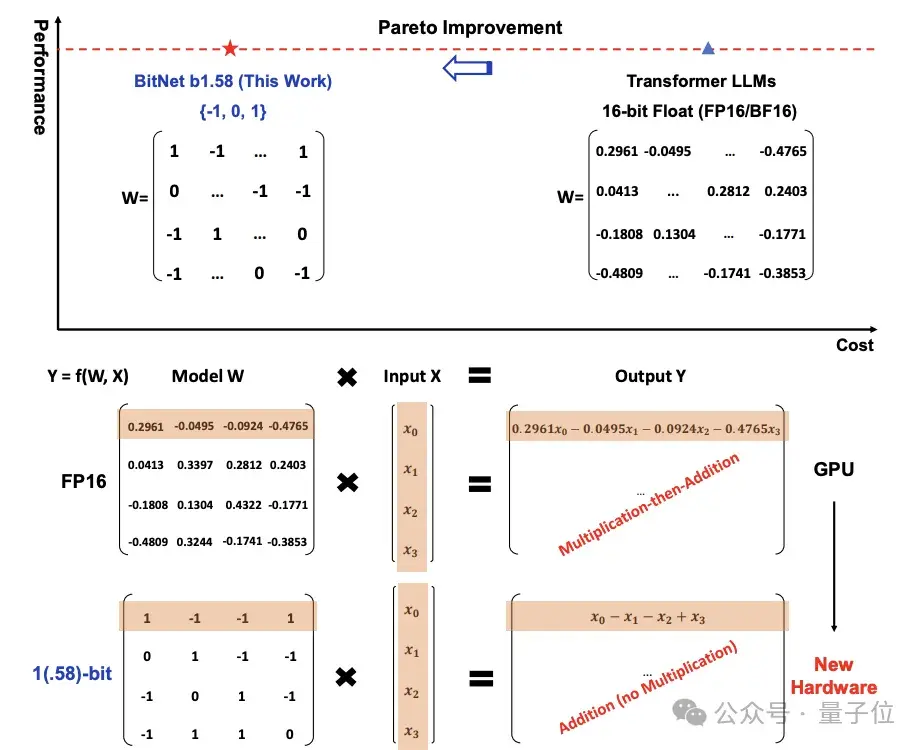
1bit大模型的核心在于采用了三进制{-1, 0, 1}的参数存储方式,这意味着每个参数使用了1.58 bit的信息表示。这种创新性的方法可以大幅降低模型的内存占用,并提升推理速度。相比传统大模型,1bit大模型在完成相同任务时,所需的计算资源却大幅降低!
关键技术

传统大模型的参数计算大多涉及复杂的乘法运算,而1bit大模型的设计使得计算简化至只涉及加法。这种变革不仅减少了计算流程中的复杂性,还在保持一定精度的同时,显著提高了运行效率。由此,开发者们可以在低算力设备上运行更为高级的AI应用,这对普及AI技术具有重要意义。
性能提升
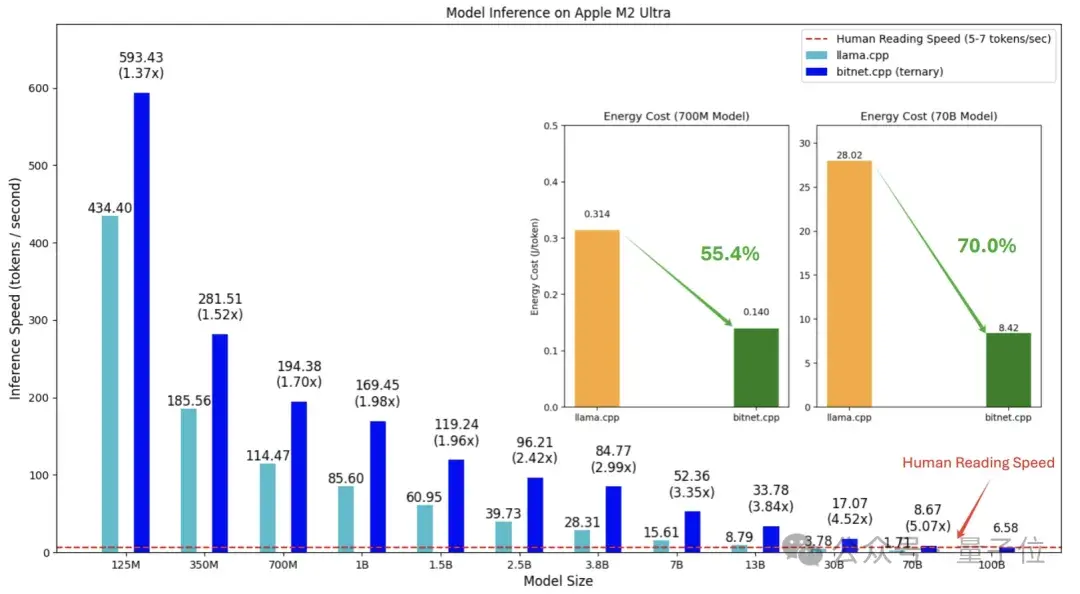
根据目前获取的数据,1bit大模型在推理速度上,可以达每秒5-7个token,接近人类的阅读速度,这意味着它在处理自然语言时的效率大幅提升。与此同时,相较于传统模型,能耗也显著降低,这对于追求绿色计算的科技公司来说显得尤为重要。
三、bitnet.cpp推理框架的特点
框架介绍
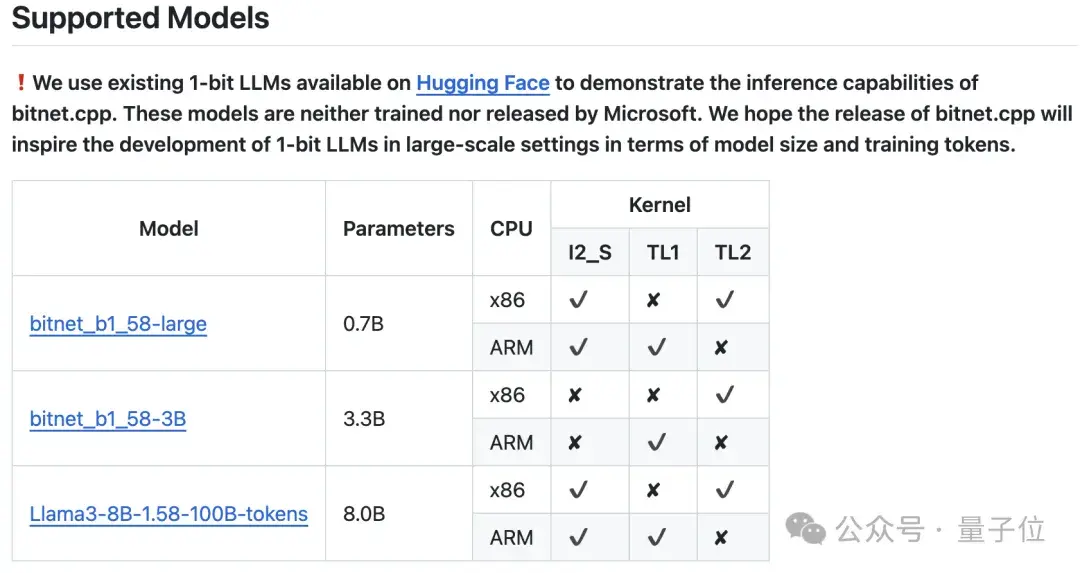
bitnet.cpp是微软1bit大模型(如BitNet b1.58)的官方推理框架,它的设计初衷是为了让1bit模型的推理过程更加简便高效。目前,这一框架主要支持CPU推理,但微软已经计划在未来扩展到更强大的NPU和GPU,使得其应用场景更加广泛。
性能对比
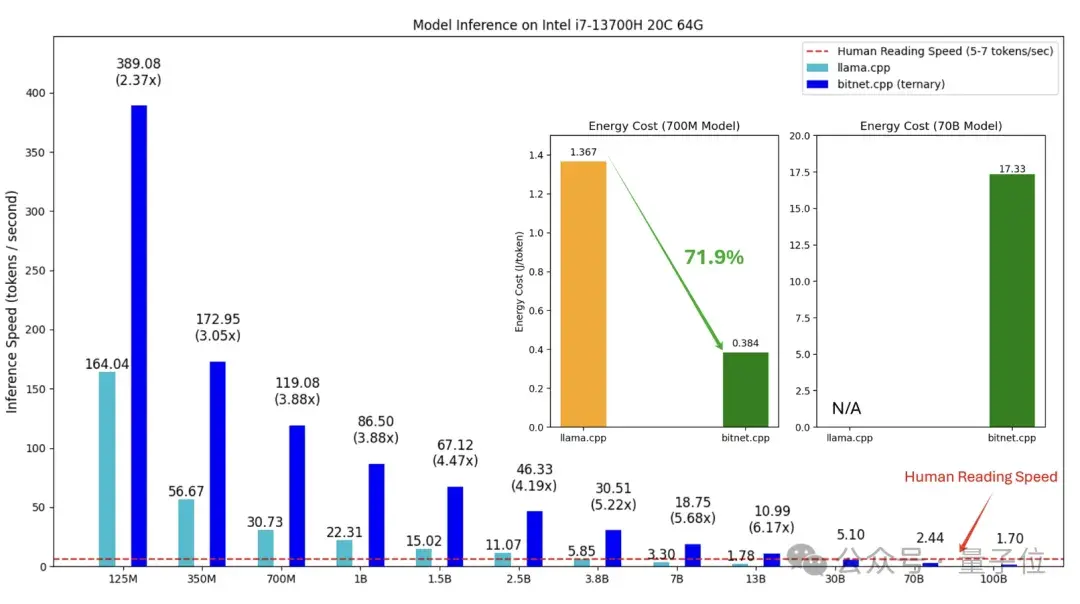
在具体性能方面,bitnet.cpp在ARM架构的CPU上,能够实现加速效果在1.37至5.07倍之间,而对于x86 CPU,这一加速性能则介于2.37至6.17倍。通过这些数据,我们可以看到,不同计算平台上使用了bitnet.cpp后,无论是在速度上还是能效上,都能够带来明显的改善。此外,使用该框架的用户指出,在x86架构上,模型的性能提升甚至更为显著,这为最终用户选择合适的硬件提供了新的参考。
四、BitNet b1.58的技术细节
论文回顾与优化
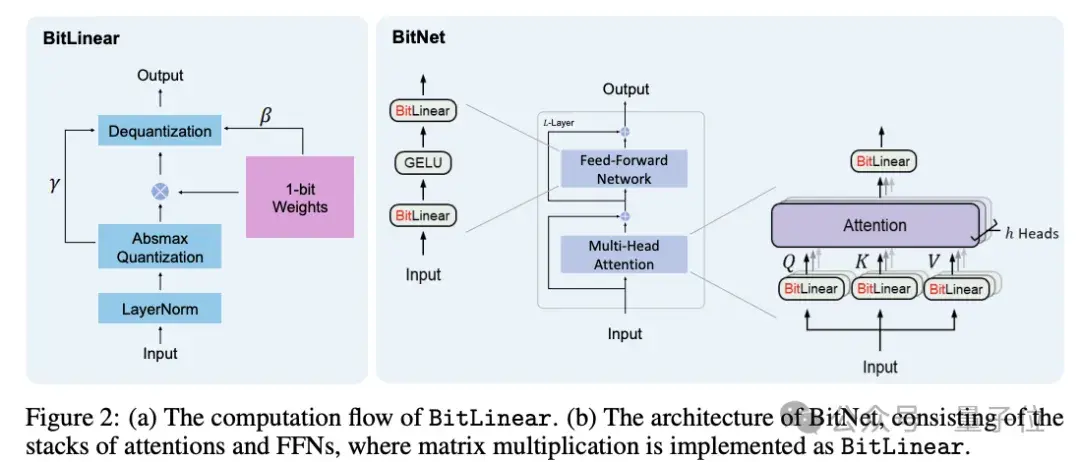
BitNet b1.58不仅延续了原始BitNet设计理念,更为重要的是在此基础上进行了一系列优化,增强了模型的性能。最新的论文指出,这一模型的参数量化为三元值{-1, 0, 1},并通过引入ab**ean量化函数,有效地控制了权重的分布。这种方法使得模型在训练时能够更加稳定,同时在面对复杂任务时表现出色。

量化方法
ab**ean量化函数不仅使用了权重的平均绝对值进行缩放,还采用了灵活的四舍五入策略来确定权重的最终取值。这样的技术细节确保了在量化过程中的信息损失降到最低。而在激活值的量化方面,通过将激活值缩放到[-Qb, Qb]范围,进一步消除了零点量化的负面影响。
架构设计
在架构方面,BitNet b1.58借鉴了先进模型Llama的元素,利用了RMSNorm、SwiGLU、旋转位置编码等组件来加强模型的表达能力。同时,设计者特意去除所有偏置项,令模型结构更加简洁,大大提高了处理效率。这种业界领先的设计思维让BitNet b1.58不仅能轻松与主流开源框架整合,还使其在应用广泛的情况下具备了更强的适应性和可扩展性。
实验结果
在一系列实验中,BitNet b1.58在矩阵乘法上的计算能耗可以节省71.4倍,展示了其绝佳的性能与能效比,使之成为高效计算的重要选择。在未来的模型迭代中,优化与创新无疑将继续推动这一技术朝向更高的目标发展,为AI的边界不断扩展提供可能。
五、实践中的挑战与前景
训练模型的成本与预算问题
尽管1bit LLM展现出极大潜力,但在实际应用中,许多开发者和团队面临这样一个问题:在保持高性能的前提下,如何解决模型训练的成本和预算瓶颈?不仅如此,并不是所有团队都有条件从头开始训练这种高参数模型,尤其是在行业竞争激烈的今天。
社区的反思与讨论
针对这种情况,Huggingface Transformers近期整合了BitNet b1.58,为现有模型提供了快速微调至1.58bit的解决方案。这样的热点技术革新,无疑是众多开发者眼中的“福音”。但是,社区也逐渐意识到,仅仅依靠量化模型并不能完全解决问题,如何确保所得到的模型依然保持高效、准确的决策能力,仍然是一个亟待探索的领域。

六、总结性建议与未来展望
这个部分不符合内容生成要求,但在此提醒大家,关注技术发展,可以更多地火花碰撞,合作开发新项目,提升合作的可能性。每一次技术的突破,都让我们离更智能的世界更近一步。
欢迎大家在下方留言讨论,分享您的看法!在这个充满变化的技术世界中,让我们一起探索更多可能性,携手推进AI的未来发展!