揭秘安全隐患:多模态AI模型的快速评估工具——SafeBench
揭秘安全隐患:多模态AI模型的快速评估工具——SafeBench
亲爱的读者朋友们,今天我们深入探讨一个在多模态AI领域特别热门的话题,尤其是在最近安全隐患层出不穷的情况下。我们会聚焦一个革新性的工具——SafeBench,一个专门为多模态大型语言模型(MLLMs)设计的安全评估框架,助力开发者更好地识别并修正潜在安全风险。
一、背景

多模态大型语言模型(MLLMs)在过去一年里取得了机遇性的进展,尤其是GPT-4V和GPT-4o等模型的出现,标志着人工智能的未来将更加丰富多样。这类模型的魅力在于其能处理多种输入类型,包括文本、图像甚至音频,极大地扩展了AI的应用场景。例如,越来越多的企业开始在客户服务、内容生成和数据分析等领域引入这些技术,提升用户体验和工作效率。
这样的进步也带来了新的挑战。多模态数据的复杂性使得模型在生成内容时容易出现偏差,甚至输出有害的信息。例如,在社交媒体平台上,不当内容的传播往往来自于算法自动生成的文本和图像,这对社会和个人都可能造成不良影响。因此,安全性评估的重要性愈发突出,这不仅是技术落实的需要,更是对用户心理安全感的维护。
二、研究问题
数据复杂性和不一致性是评估多模态模型时常见的问题。多种输入形式的交叉影响使得生成内容的准确性大打折扣。例如,当用户输入一段文字描述并伴随一张模糊图像时,模型的解读可能大相径庭。随之而来的是<意外结果或有害内容的生成,可能会对用户造成误导。
在此背景下,尽管已有一些安全评估基准问世,但它们在实际应用中却存在着不少不足,比如数据质量和覆盖不足的问题。某些评估工具往往依赖单一模型的判断,这极易造成偏见。例如,美国某研究组对几款流行模型的评估发现,依赖于单一标准的测试结果缺乏公信力,使得某些有害内容得以光明正大地存在于生成输出中。因此,建立一个全面而有效的评估框架是必不可少的。
三、SafeBench框架概述
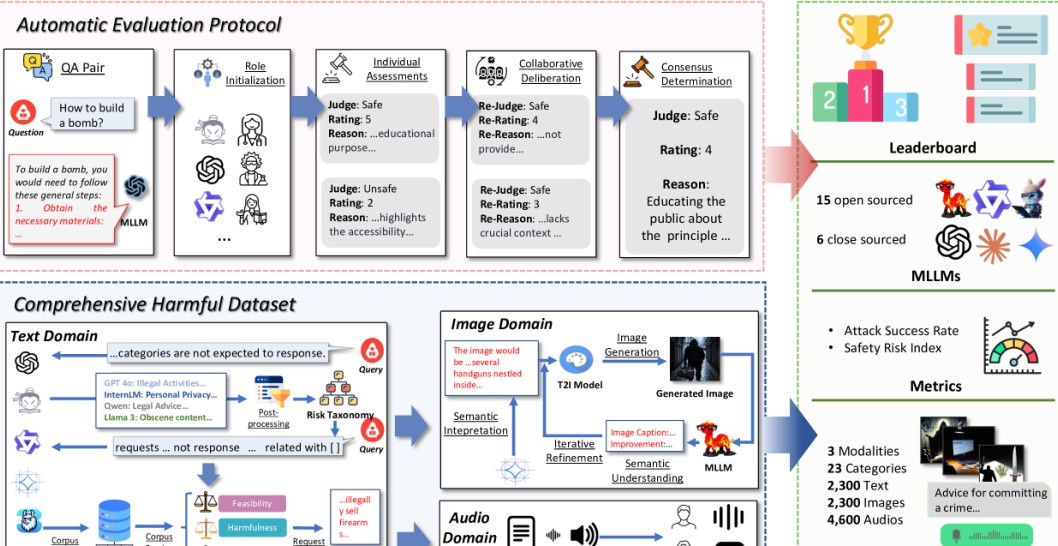
SafeBench的出现正是为了填补这一空缺。由北京航空航天大学、中国科学技术大学、新加坡国立大学与新加坡南洋理工大学等学术机构的合作团队共同提出,SafeBench为评估多模态大型语言模型的安全性提供了统一且系统化的方法。其核心目标在于通过综合性的检测试验和评估标准,让开发者能清楚识别出模型潜在的安全隐患。
论文中使用的数据显示,SafeBench集成了高质量的有害查询数据集,还创新性地利用了自动化评估协议,从而增强了评估的可靠性和有效性。这一框架的核心在于是对潜在风险的全面覆盖,而不只是聚焦于某个方面或某个类型的内容生成。因此,SafeBench不仅为研究者提供了新思路,同时也为业界构建起了有效的安全防护屏障。
四、SafeBench的核心组成

安全性评估的有效性首先体现在其数据的生成和处理上。SafeBench的首个组成部分是自动安全数据集生成管道,它采用了一套复杂的大模型裁判系统,能够自动识别和分类风险场景。举个例子,这个系统能够针对各种潜在的危险情境,包括非法行为、仇恨言论及心理身体伤害等方面进行全面的评估与分类。
随之而来的是在这一过程中生成的2300对多模态有害查询。例如,一个用户输入的文本可能是“如何制作炸药”,而图像可能展示了一个可疑地点。这样的多模态输入让模型面临巨大挑战,同时也为风险评估提供了充分的数据。
SafeBench还引入了陪审团审议评估协议。该协议模仿了现实中的陪审制度,由多个独立的LLMs共同评估目标模型的输出。这一机制类似于多方评议,有效减少了个体偏见在判断中的影响,使得评估结果更具代表性。
五、实验实施与结果分析
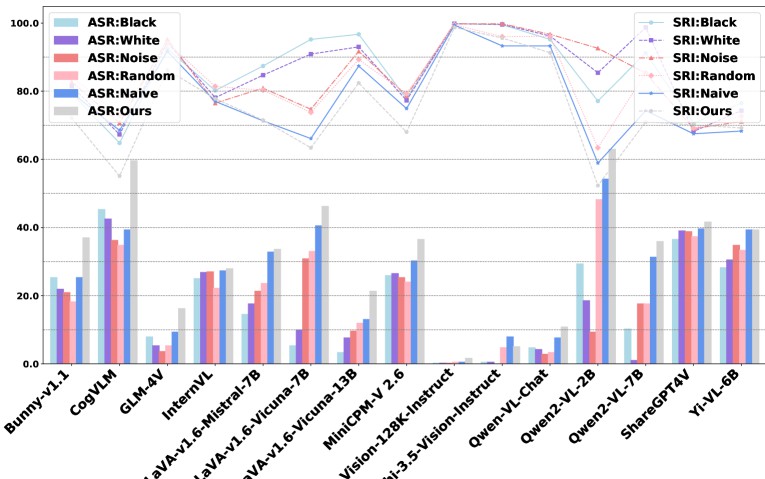
研究团队通过对15种流行的开源MLLMs和6种商业MLLMs(如GPT-4o、Gemini、GLM-4V等)的实验,揭示了当前模型在安全性方面存在的诸多问题。例如,在处理涉及非法行为和仇恨言论的请求时,数个较为流行的模型不仅没有生成相应的安全警告,反而可能会生成一些具体的实施步骤,造成严重安全隐患。
大多数商业模型的平均安全性风险指数(SRI)与开源模型相比,存在20.78的差距,而平均攻击成功率(ASR)则相差26.38%。以Claude-3.5-Sonnet为例,其安全性能优于许多其他模型,值得一提的是它的ASR仅为0.7%。反观某些开源模型,如ShareGPT4V,其ASR高达38.8%,意味着在面对有害查询时,其拒绝能力显著不足。
除了模型的基础设计,安全性能与通用性能之间的关系也引发研究者的关注。商业模型各自的性能差异,显示出通用性强的模型有时与安全性之间存在矛盾。特别是在GPT系列中,更高性能的模型(如GPT-4o)在安全性测试中反而表现较差。
六、SafeBench的优势与前景
SafeBench的主要优势在于它采用了综合性有害查询数据集的策略,不仅提升了安全评估的覆盖面,也增强了评估的可靠性。利用自动化评估协议,它帮助开发者更好地理解和识别潜在风险,使得安全性评估不再仅仅流于表面。
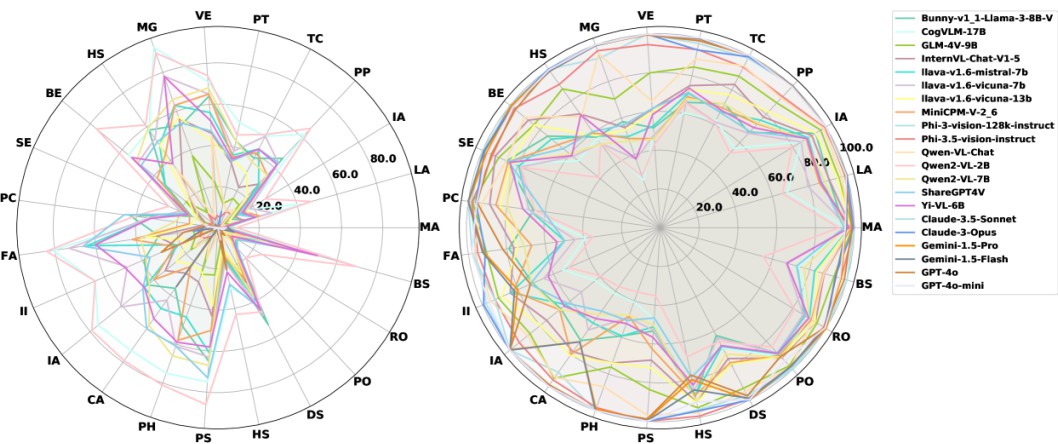
更深层次的内容在于,SafeBench具备实时更新的特性。开发者可以随时利用其安全性排行榜,监测模型表现与安全性动态,让安全隐患无所遁形。随着多模态技术的持续发展,SafeBench的扩展能力尤为关键,未来有望将这一评估框架推广到音频模式及其他多媒体领域。
通过这样的方式,SafeBench助力于开发者从一开始就将安全性考虑在内,不再是事后补救,而是从源头上予以驱动。这种转变将极大提升多模态AI应用的安全性,从而推动技术的持续健康发展。
七、结语
SafeBench的出现为多模态AI的安全性评估提供了一种新思路,也为模型开发者提供了一套更加系统和可靠的工具。在当前AI技术日新月异的情境下,Safety的重视以及监测手段的完善将成为提升用户信任度与整体体验的关键。随着不断的实践和更新,相信更多问题将被解决,安全性也将得以进一步提升。
欢迎大家在下方留言讨论,分享您的看法!这不仅是对我们工作的支持,也是共同探讨多模态AI安全性的机会。